读取数据
import pandas as pd# 存储数据# 四条电影记录s1 = pd.Series(['楚门的世界', '泰坦尼克号', '霸王别姬', '你的名字'])s2 = pd.Series(['8.3', '9.5', '9.1', '8.7'])s3 = pd.Series(['672586', '1521451', '1538556', '1001049'])s4 = pd.Series(['剧情', '爱情', '爱情', '动画'])print(s1)print(s2)print(s3)print(s4)# 组成电影数据表df = pd.DataFrame(list(zip(s1, s2, s3, s4)),columns=['title', 'average', 'votes', 'genre'])# print(df)# 存储df.to_csv("file_name.csv")df.to_excel("file2.xlsx")# 读取print("==================")print(pd.read_csv("file_name.csv"))print(pd.read_excel("file2.xlsx"))
数据清理
读取文件
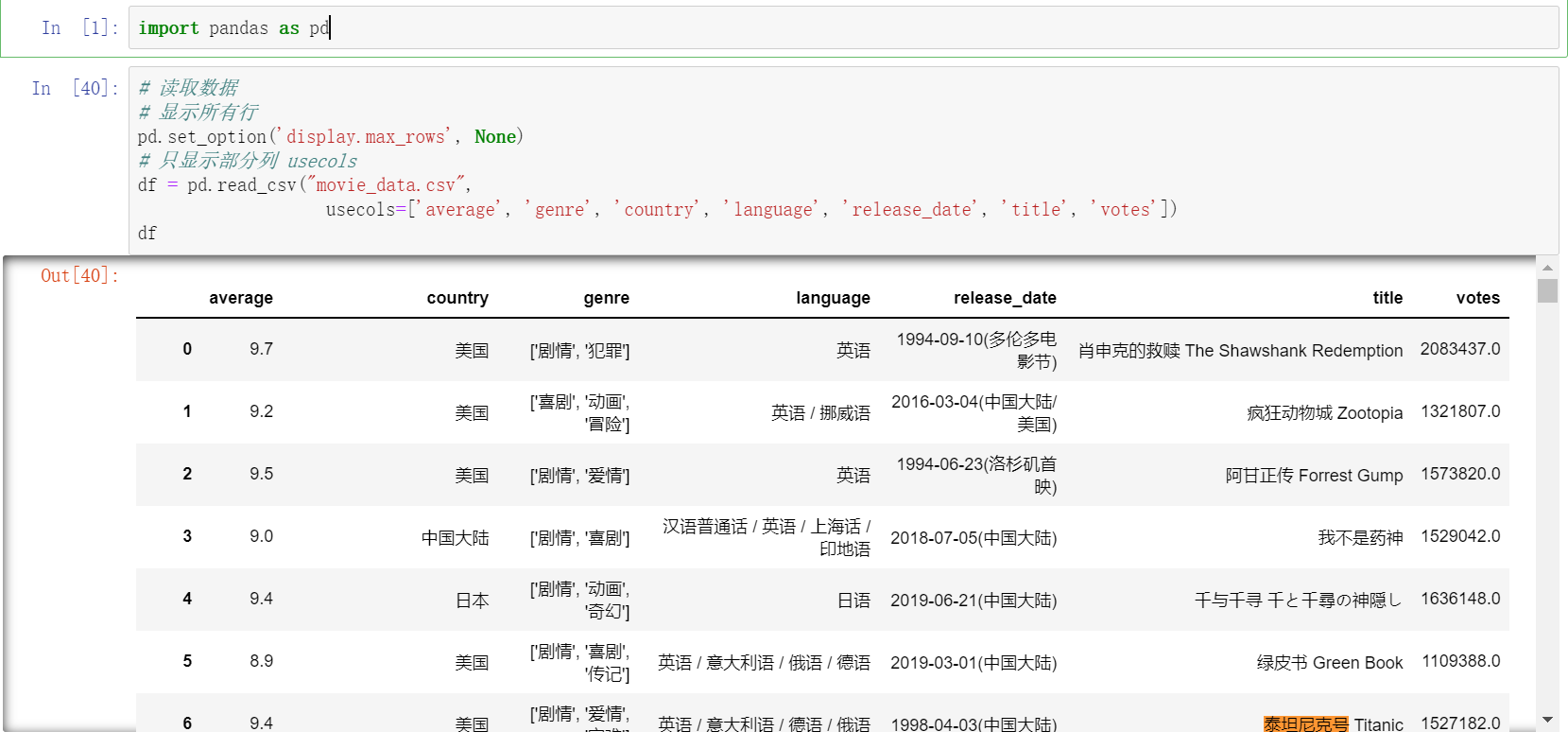
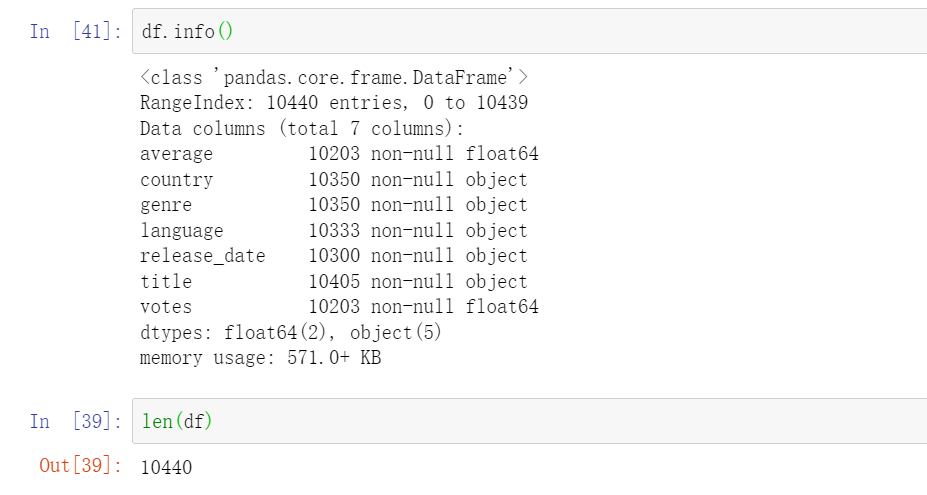
重复值
查重
查重统计(每列的重复总数)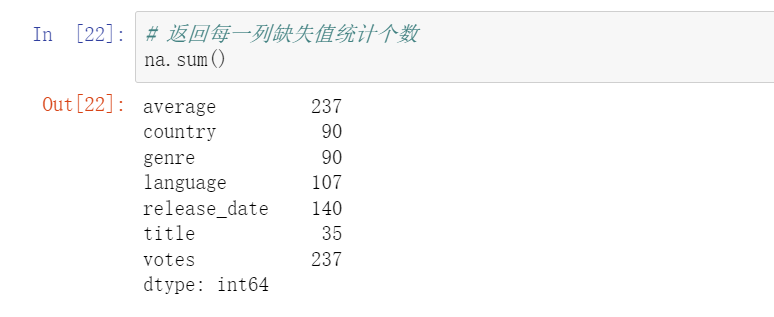
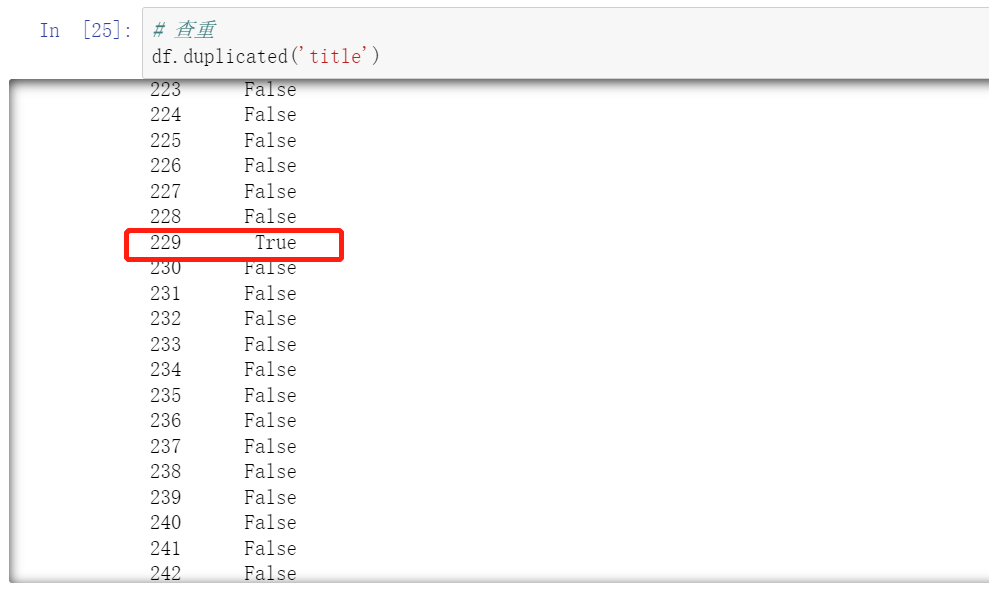
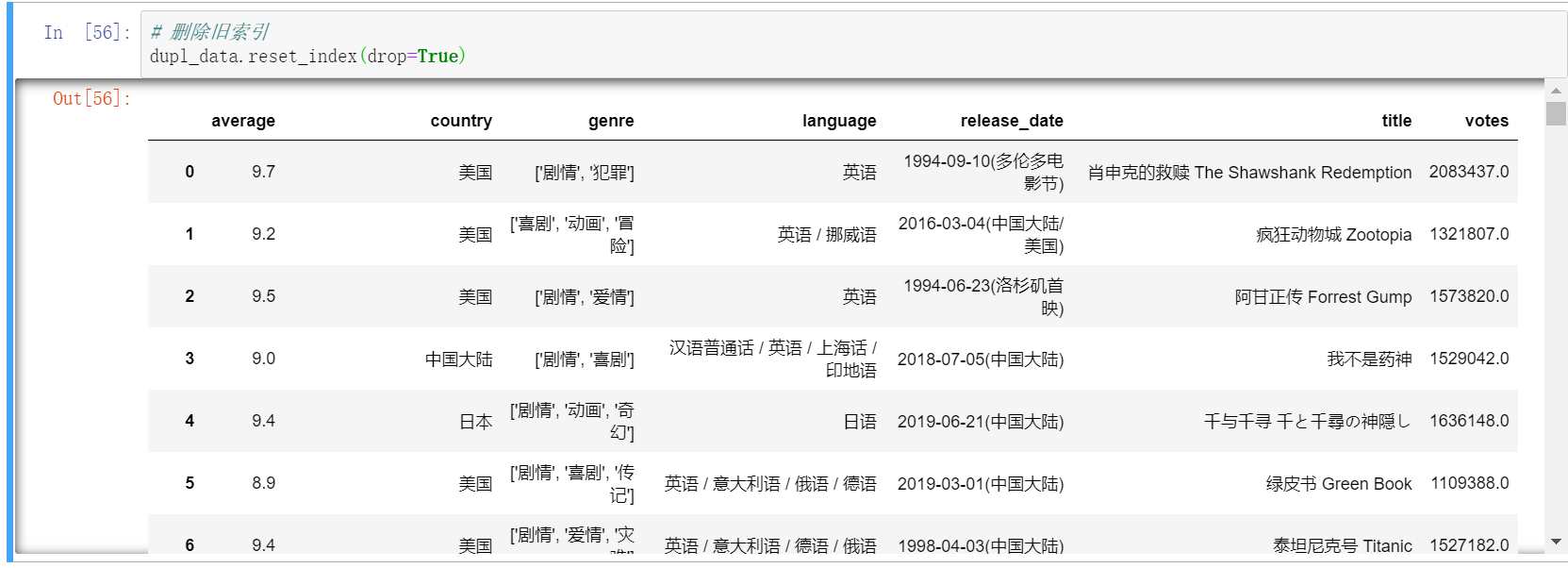
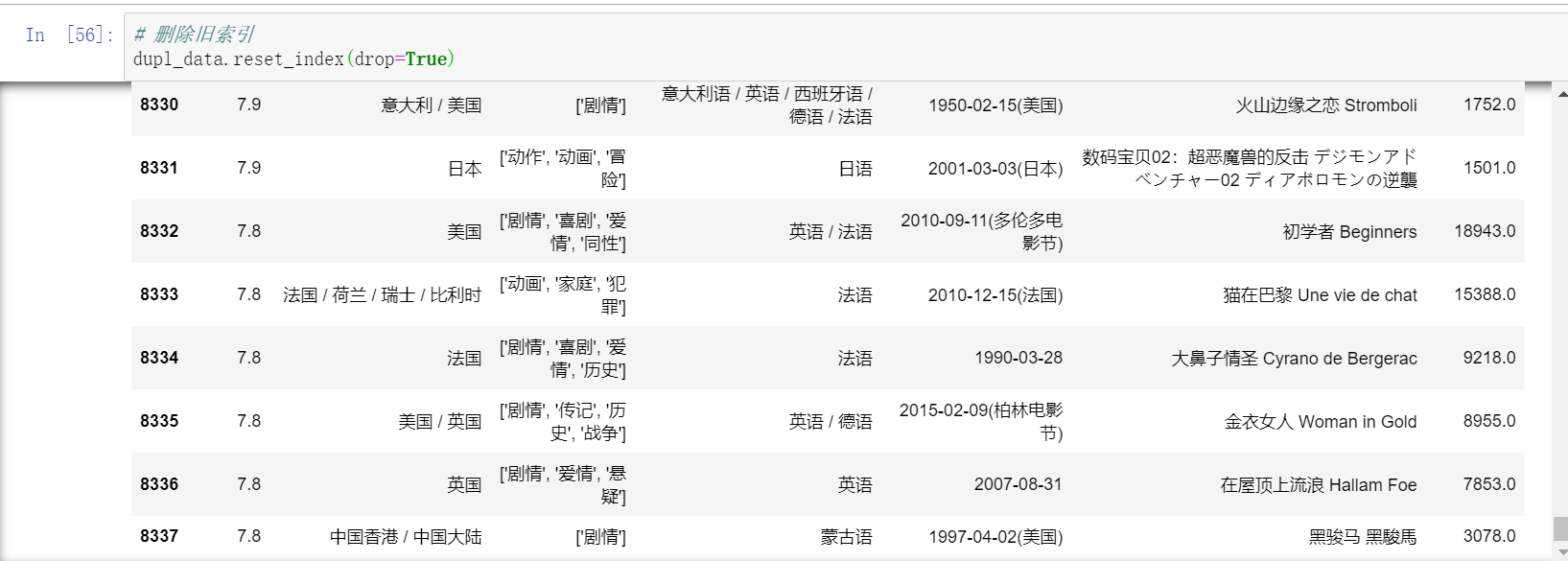
去重
如果不按列,针对所有字段完全相同的行进行删除,则直接drop_duplicates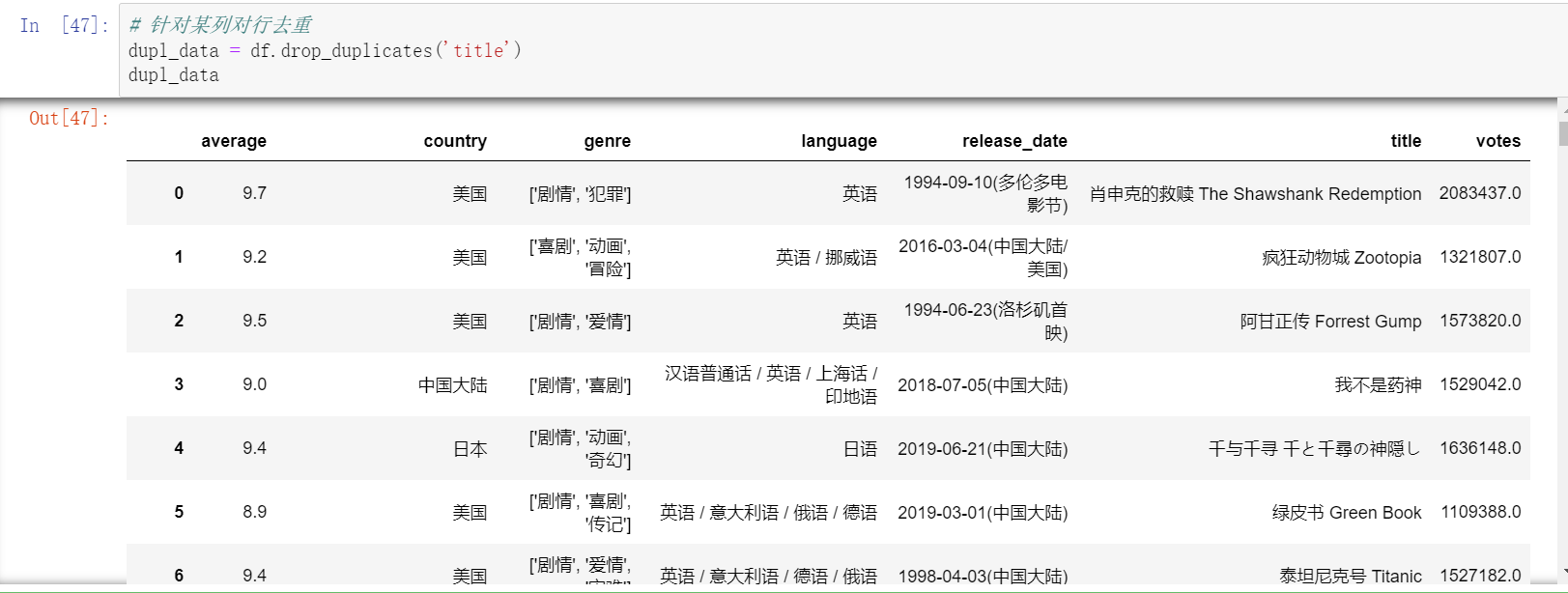
缺失值
Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值。
查看缺失值
按单元格查看

按列查看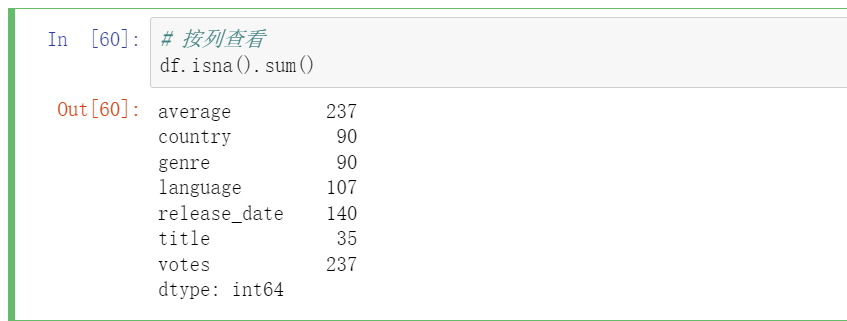
按行查看 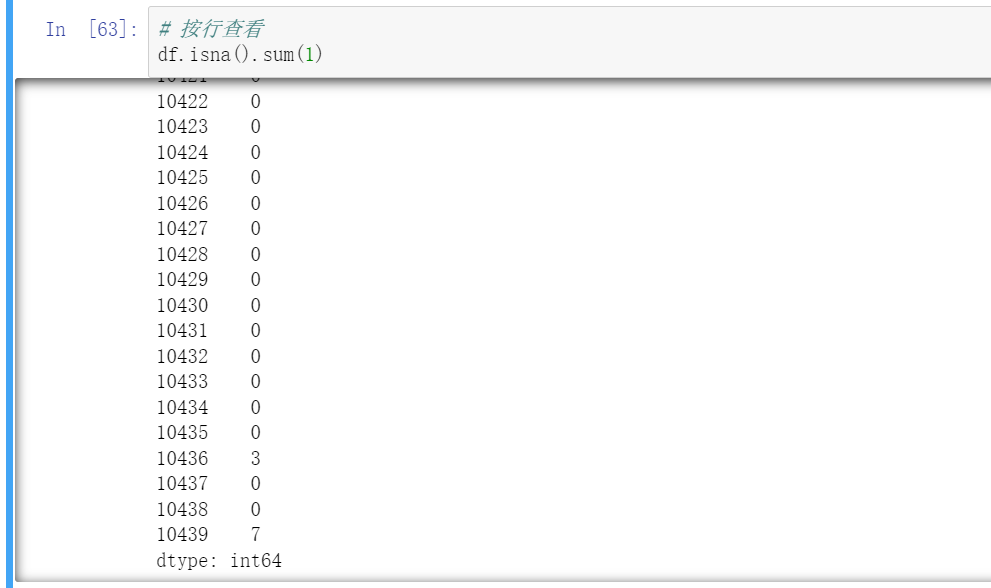
有缺失值的行、列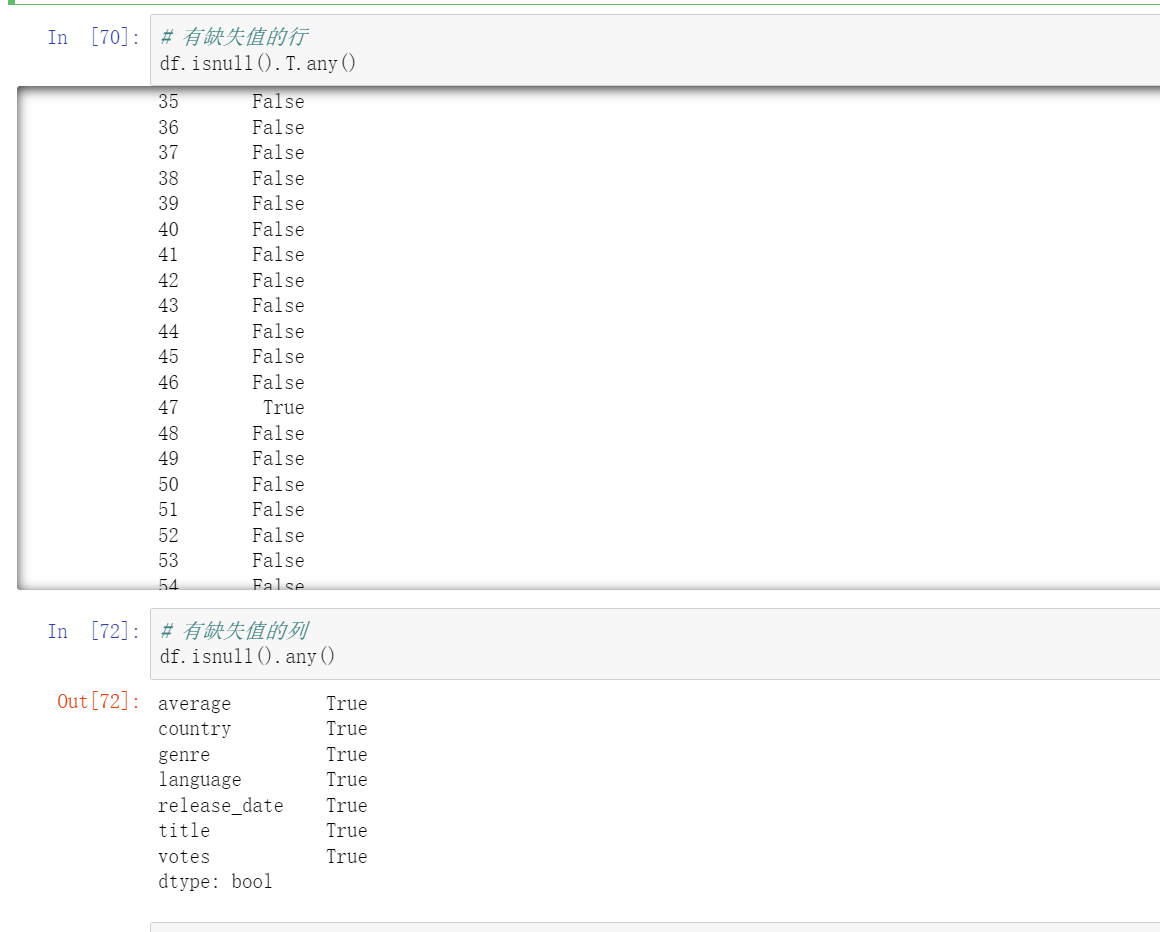
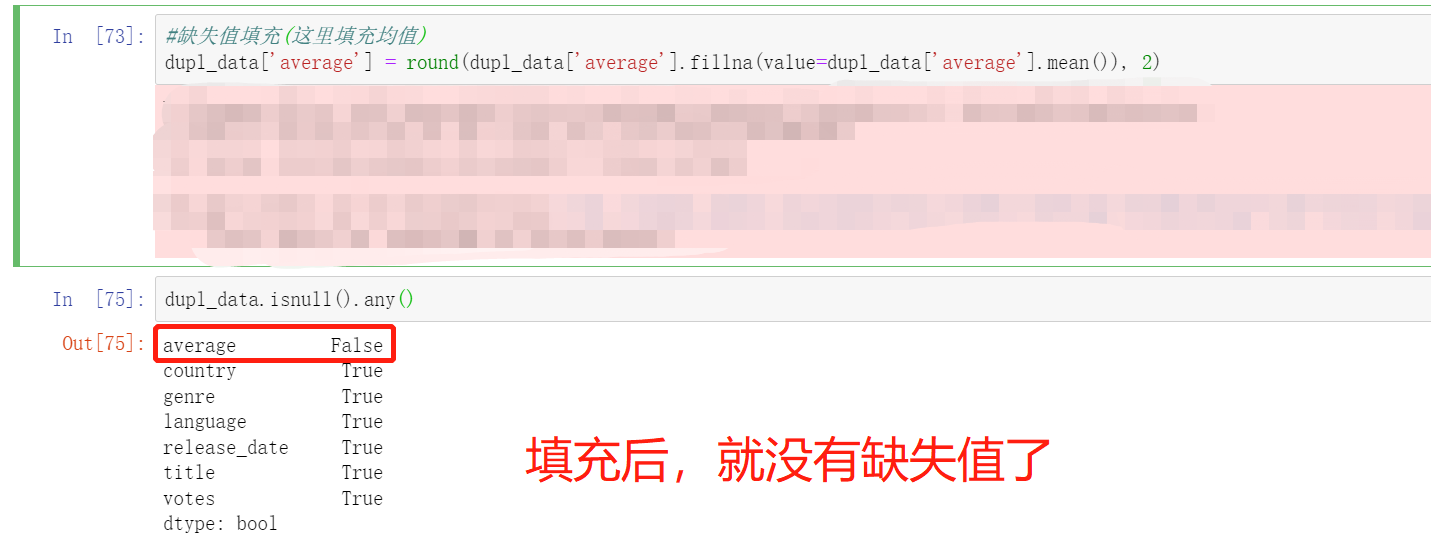
填充缺失值

若有收获,就点个赞吧
0 人点赞
