K-NeastNeighobr
算法思想:近朱者赤,近墨者黑。
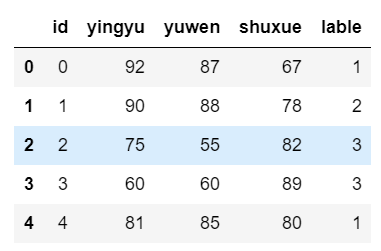
1.加载数据
import pandas as pddf=pd.read_csv('myData.csv')df.head()
2.预处理
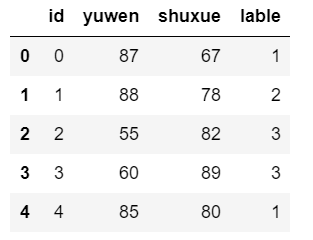
清洗
myResult=df.drop(['yingyu'],axis=1)myResult.head()
筛选
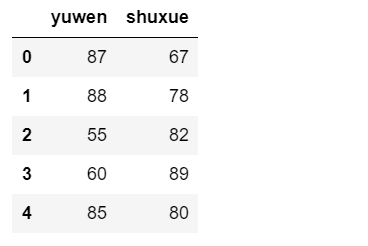
测试集
train_x=df.iloc[0:80,2:4]train_x.head()
train_y=df.iloc[0:80,4].valuestrain_y[0:5]
array([1, 2, 3, 3, 1], dtype=int64)
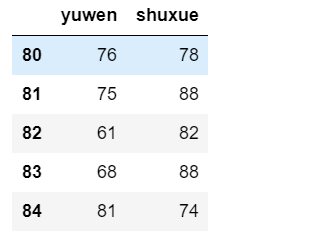
3.训练集
test_x=df.iloc[80:100,2:4]test_x.head()
4.建模
from sklearn import neighborsmodel=neighbors.KNeighborsClassifier()
model.fit(train_x,train_y)
输出:KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=1, n_neighbors=5, p=2,weights='uniform')N默认为5
5.预测
model.predict(test_x)
输出:array([2, 3, 3, 3, 1, 1, 3, 2, 3, 1, 3, 1, 1, 2, 3, 2, 2, 1, 2, 1],dtype=int64)
train_p=model.predict(train_x)train_p
输出:array([1, 2, 3, 3, 2, 3, 2, 3, 1, 2, 3, 3, 2, 3, 3, 1, 3, 1, 1, 3, 3, 1,1, 3, 1, 1, 2, 3, 2, 3, 2, 2, 3, 2, 1, 3, 3, 2, 3, 2, 2, 2, 2, 1,2, 1, 1, 3, 2, 3, 1, 2, 1, 3, 3, 3, 1, 2, 2, 3, 3, 3, 1, 1, 1, 3,2, 3, 3, 1, 3, 2, 1, 3, 3, 1, 2, 2, 1, 1], dtype=int64)
train_y

若有收获,就点个赞吧
0 人点赞
