验证数据集
为什么需要验证数据集:
1.由于测试数据并不是真实数据,因此训练出的模型在预测真实值时,可能出现过拟合和欠拟合。
2.训练出的模型依赖测试集,当测试集发生变化,模型需要重新训练
验证数据集的具体作用:模拟真实环境
1.充当测试数据集
2.真正的测试数据集变成了真实数据集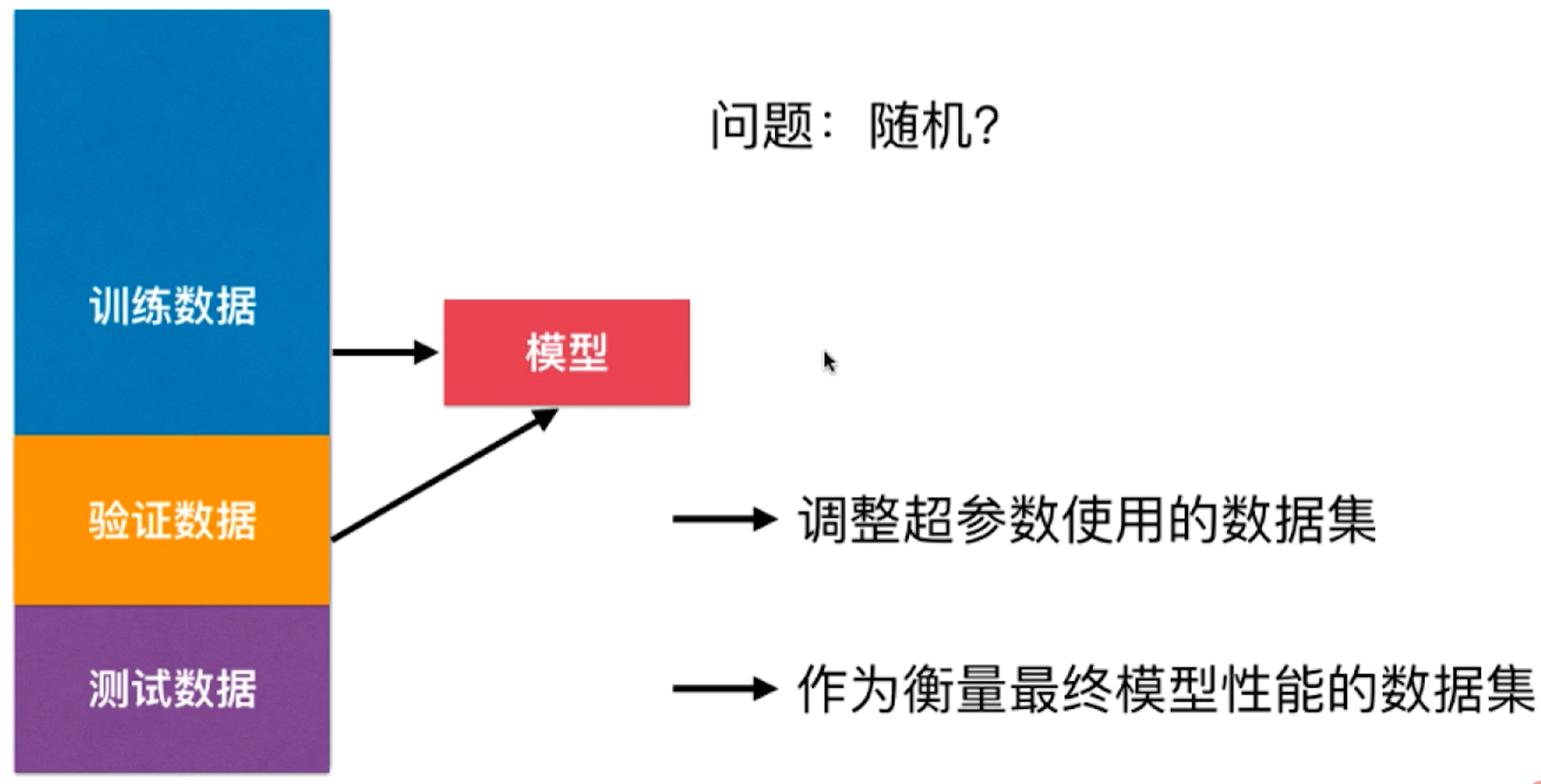
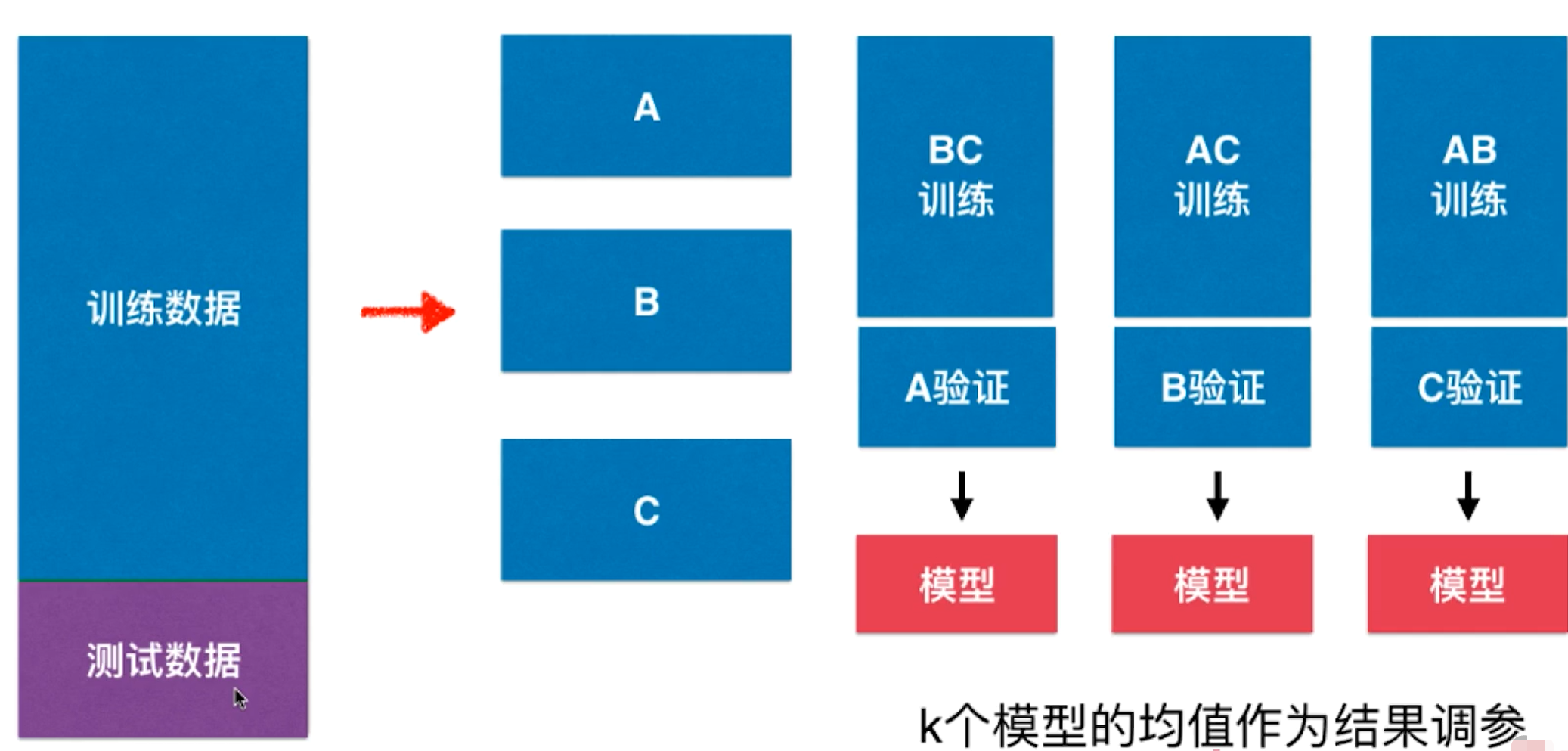
交叉验证
编码
# 1.准备数据import numpy as npfrom sklearn import datasetsdigits = datasets.load_digits()X = digits.datay = digits.target# 2.分割数据from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666)# 3.建模from sklearn.neighbors import KNeighborsClassifierbest_k, best_p, best_score = 0, 0, 0for k in range(2, 11):for p in range(1, 6):knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)knn_clf.fit(X_train, y_train)score = knn_clf.score(X_test, y_test)if score > best_score:best_k, best_p, best_score = k, p, scoreprint("Best K =", best_k) # 3print("Best P =", best_p) # 4print("Best Score =", best_score) # 0.986091794159# 4.使用交叉验证from sklearn.model_selection import cross_val_scoreknn_clf = KNeighborsClassifier()cross_val_score(knn_clf, X_train, y_train) # array([ 0.98895028, 0.97777778, 0.96629213])best_k, best_p, best_score = 0, 0, 0for k in range(2, 11):for p in range(1, 6):knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)scores = cross_val_score(knn_clf, X_train, y_train) # 交叉验证:随机选取验证数据集和建模score = np.mean(scores)if score > best_score:best_k, best_p, best_score = k, p, scoreprint("Best K =", best_k) # 2print("Best P =", best_p) # 2print("Best Score =", best_score) # 0.982359987401best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=2, p=2)best_knn_clf.fit(X_train, y_train)best_knn_clf.score(X_test, y_test) # 0.98052851182197498# 5.网格搜索# 网格搜索内置了交叉验证from sklearn.model_selection import GridSearchCVparam_grid = [{'weights': ['distance'],'n_neighbors': [i for i in range(2, 11)],'p': [i for i in range(1, 6)]}]grid_search = GridSearchCV(knn_clf, param_grid, verbose=1)grid_search.fit(X_train, y_train)# Fitting 3 folds for each of 45 candidates, totalling 135 fits# 训练集分成3组,一共45个模型,共训练135次grid_search.best_score_ # 0.98237476808905377grid_search.best_params_ # {'n_neighbors': 2, 'p': 2, 'weights': 'distance'}best_knn_clf = grid_search.best_estimator_best_knn_clf.score(X_test, y_test) # 0.98052851182197498# 6.cv参数# 训练集分成几组cross_val_score(knn_clf, X_train, y_train, cv=5)# array([ 0.99543379, 0.96803653, 0.98148148, 0.96261682, 0.97619048])grid_search = GridSearchCV(knn_clf, param_grid, verbose=1, cv=5)
k-folds交叉验证

若有收获,就点个赞吧
0 人点赞
