进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,而共享带来的是竞争,竞争带来的结果就是错
作用:将局部代码串行化
不加锁
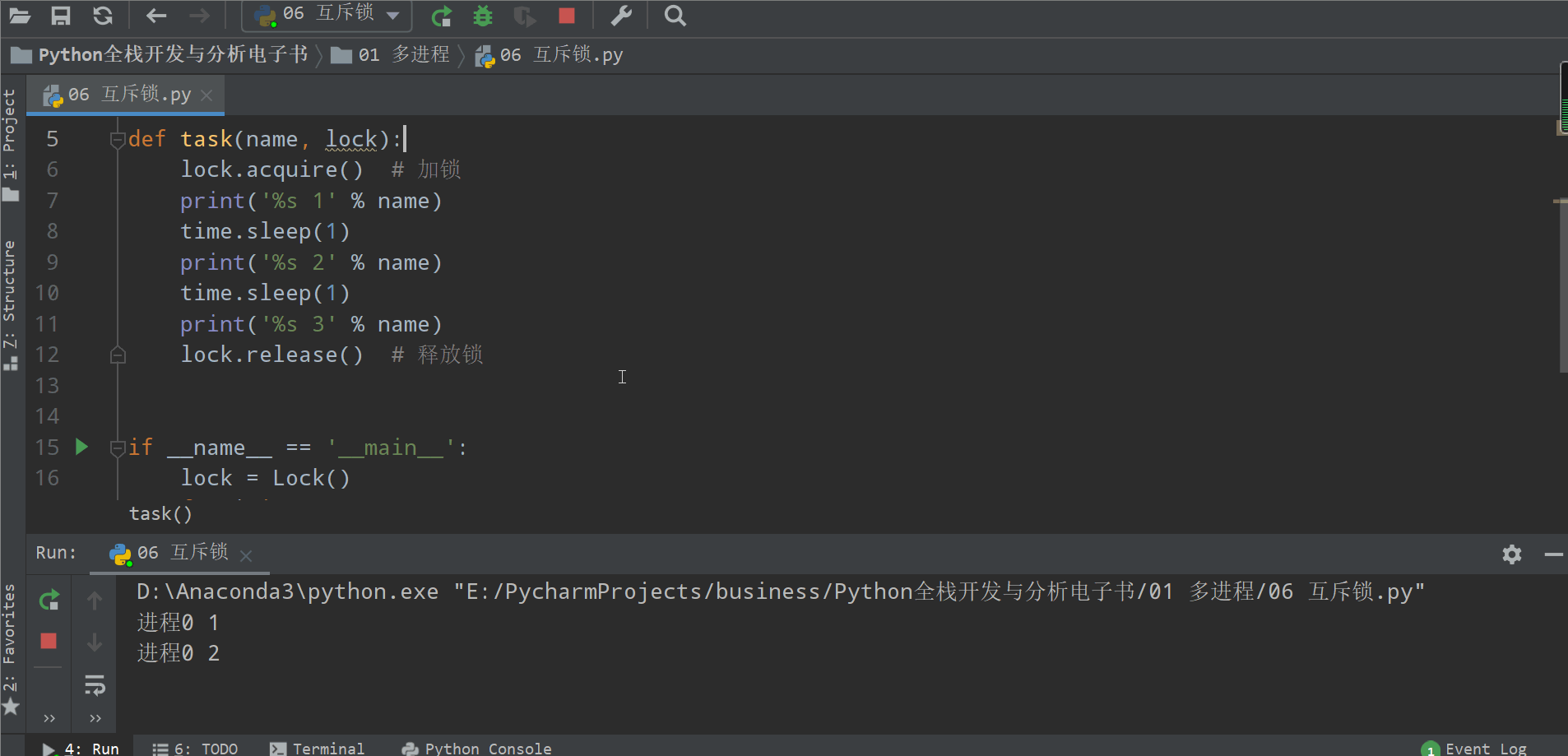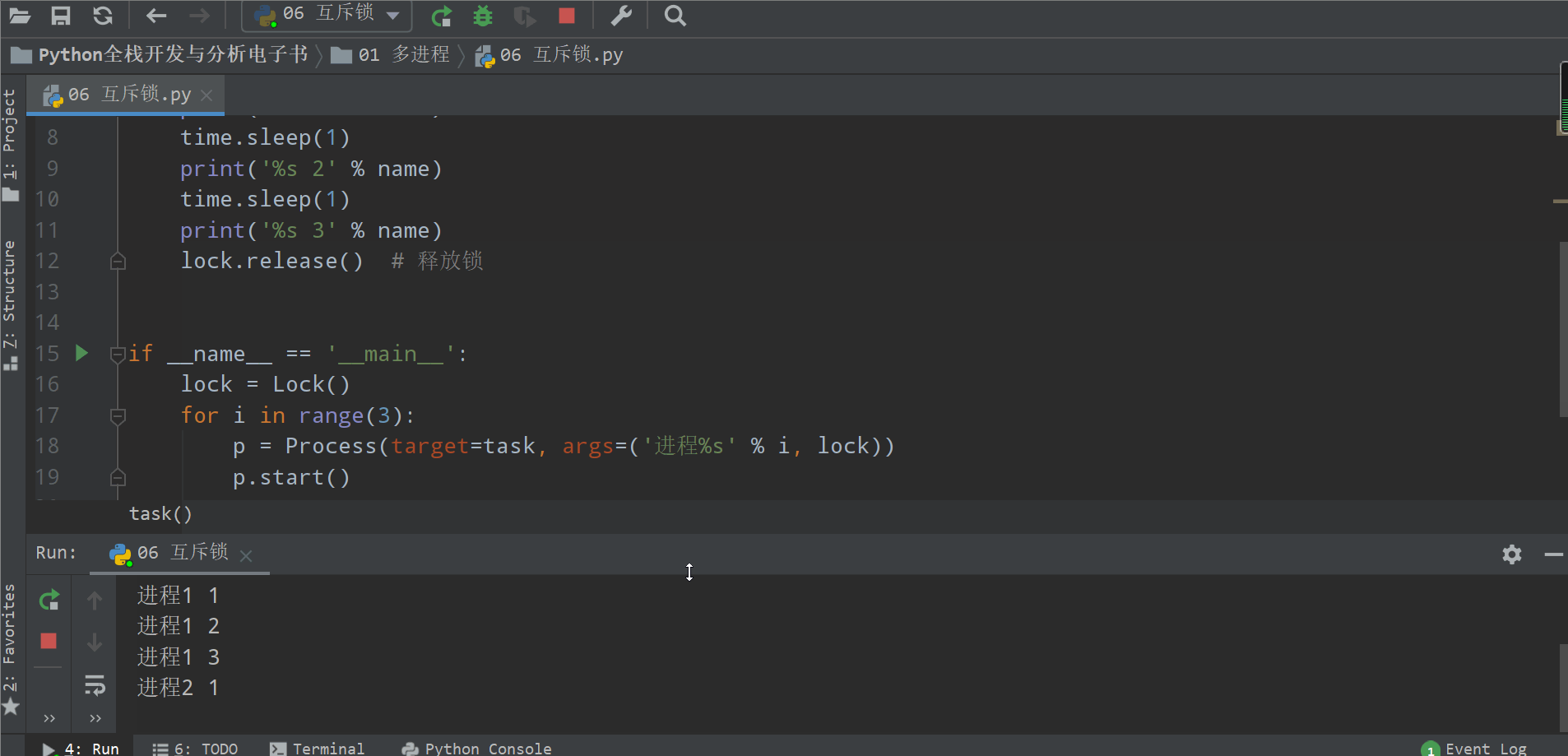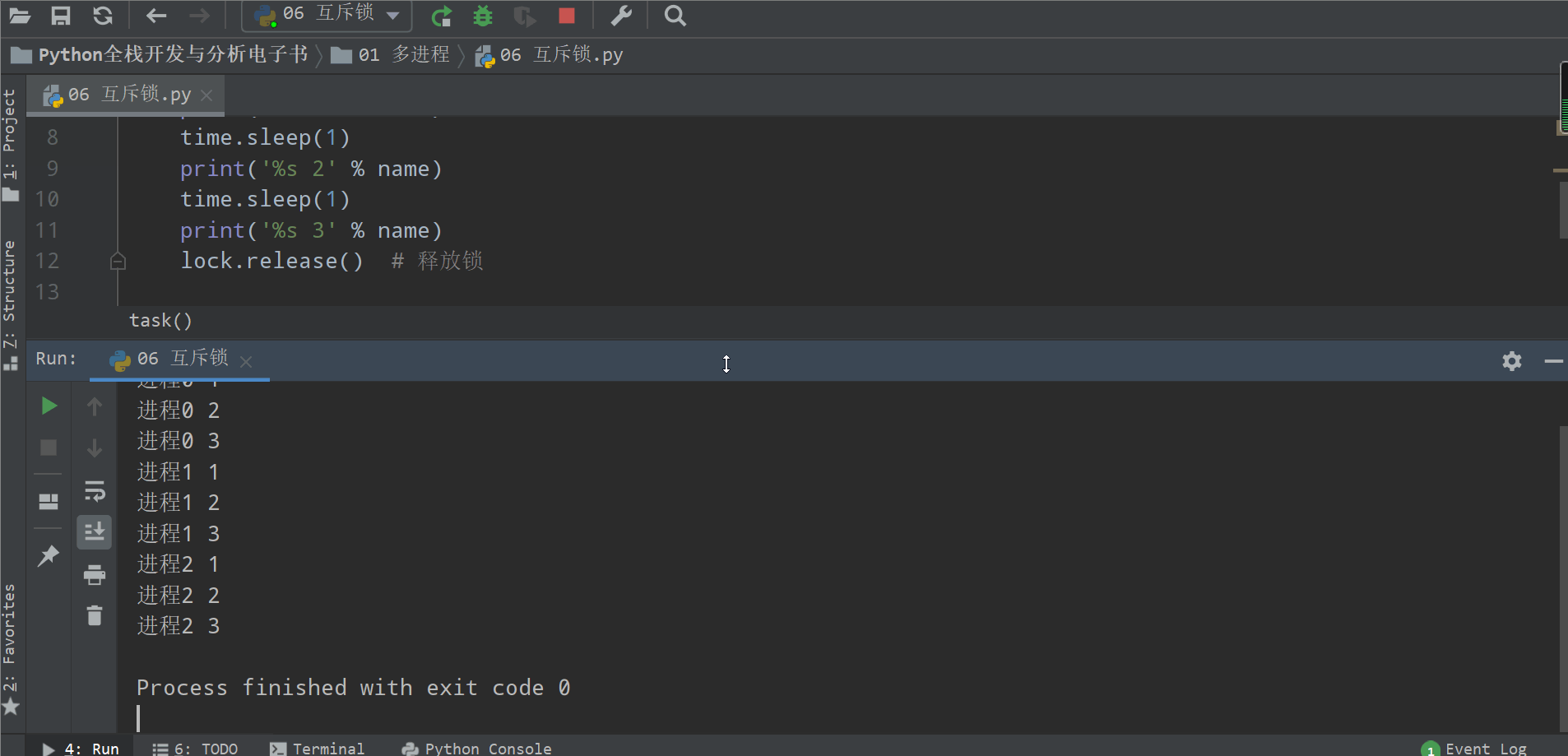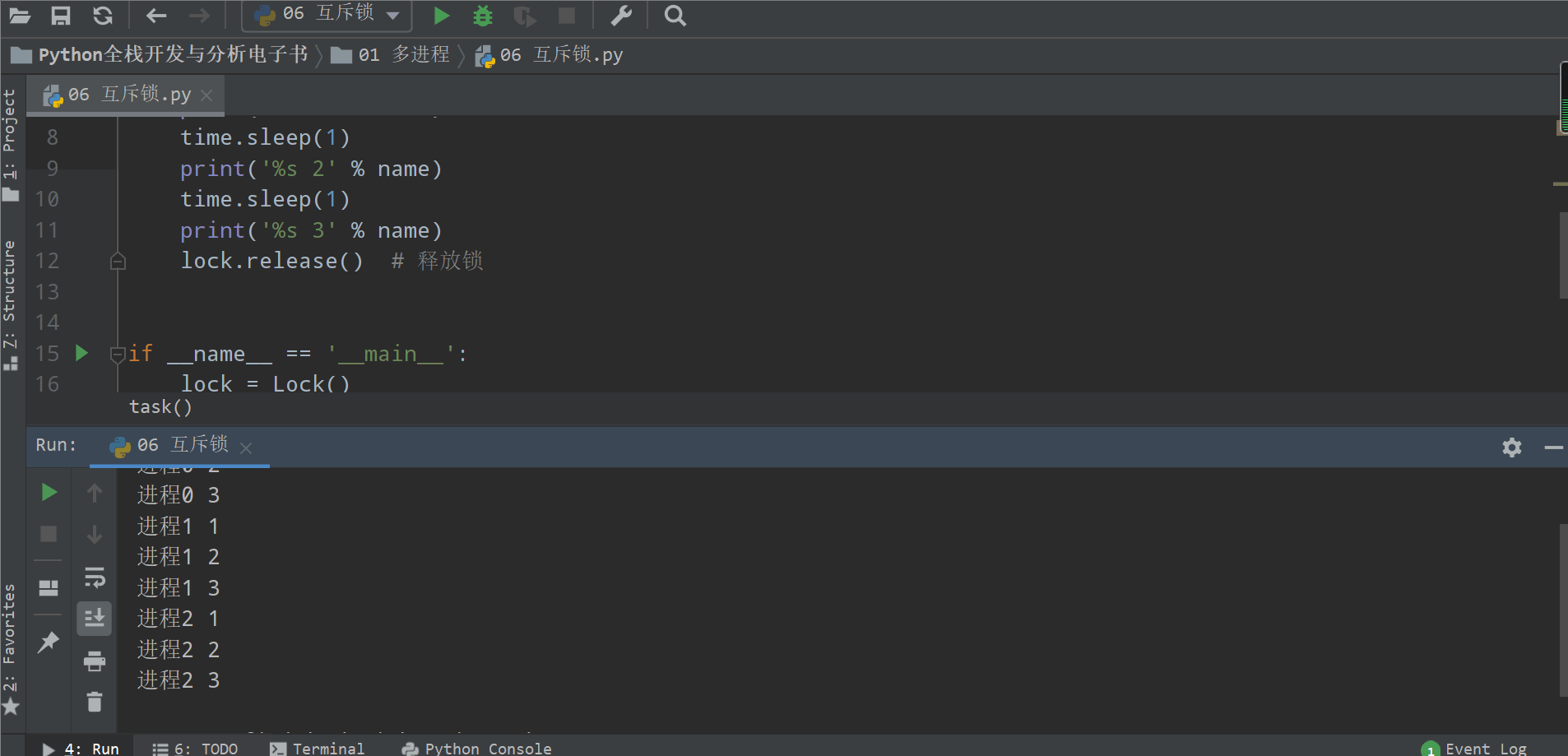
from multiprocessing import Processimport timedef task(name):print('%s 1' % name)time.sleep(1)print('%s 2' % name)time.sleep(1)print('%s 3' % name)if __name__ == '__main__':for i in range(3):p = Process(target=task, args=('进程%s' % i,))p.start()
加锁
from multiprocessing import Process, Lockimport timedef task(name, lock):lock.acquire() # 加锁print('%s 1' % name)time.sleep(1)print('%s 2' % name)time.sleep(1)print('%s 3' % name)lock.release() # 释放锁if __name__ == '__main__':lock = Lock()for i in range(3):p = Process(target=task, args=('进程%s' % i, lock))p.start()
模拟抢票
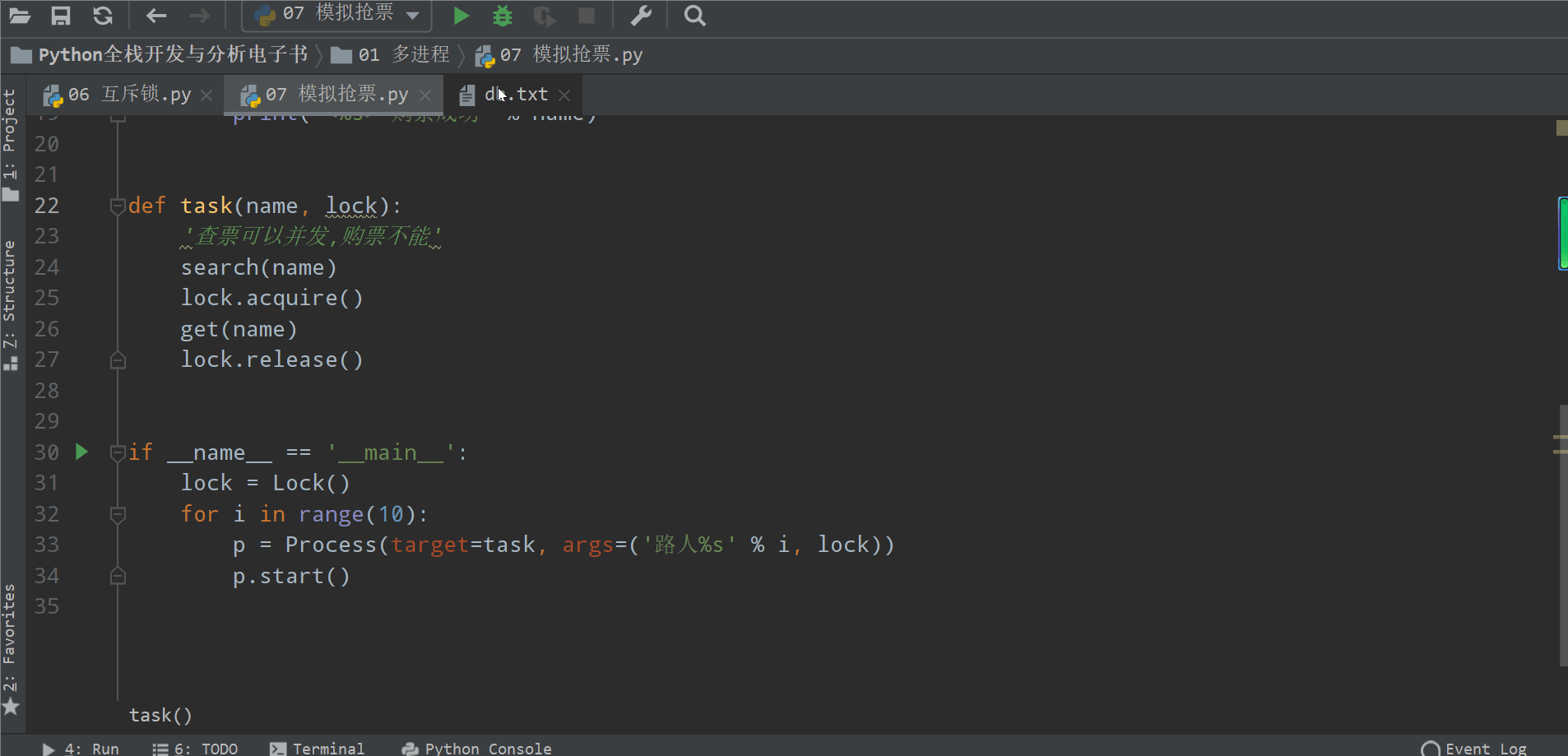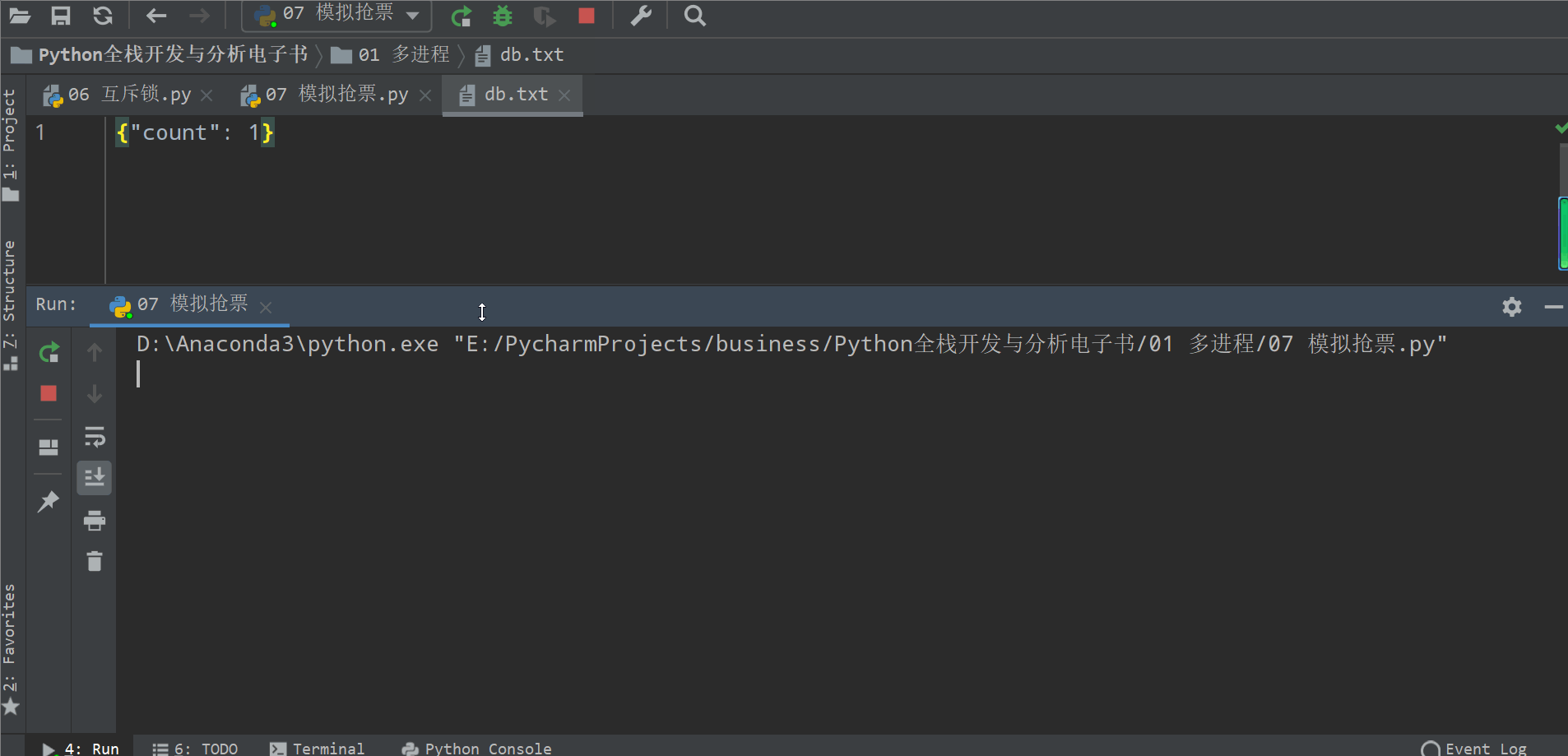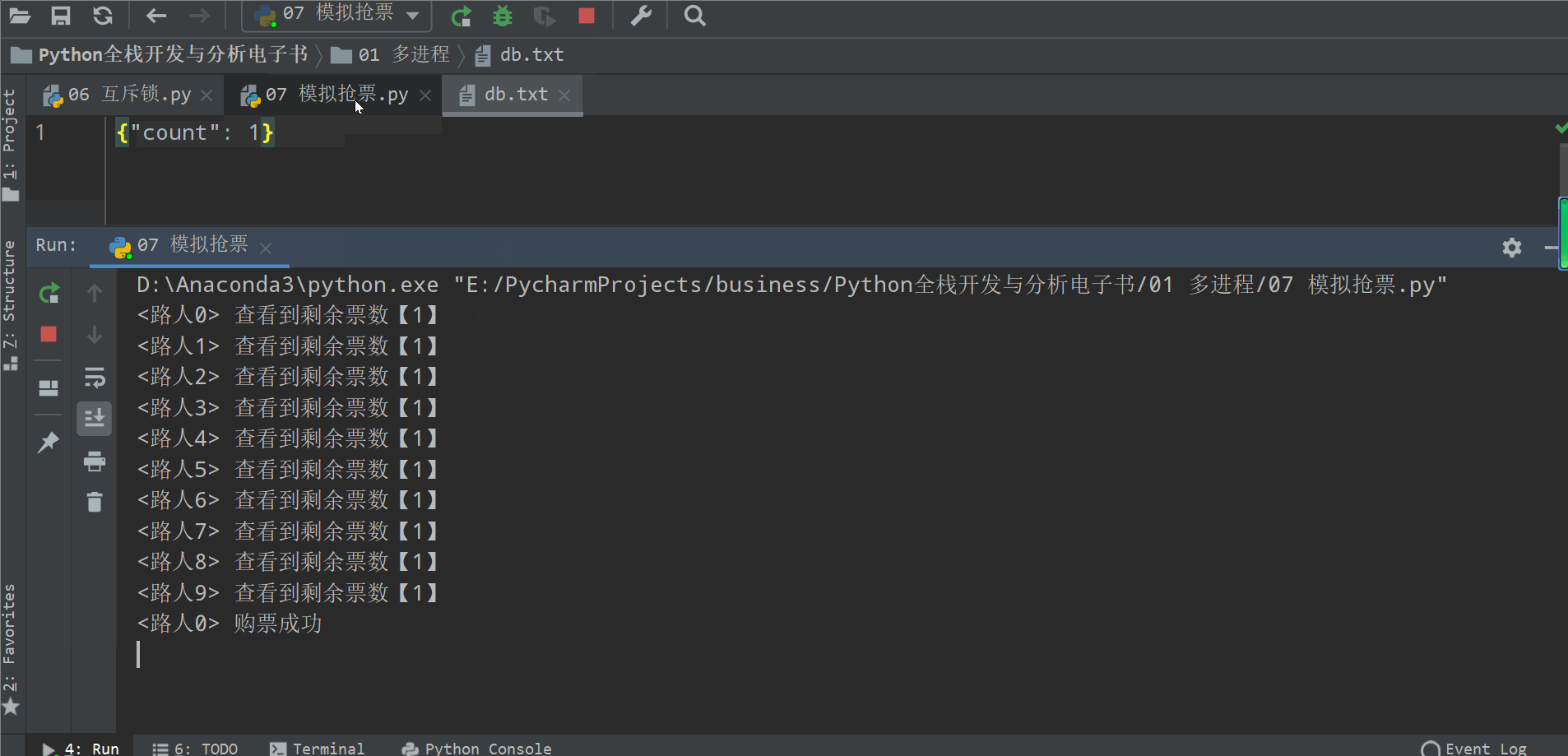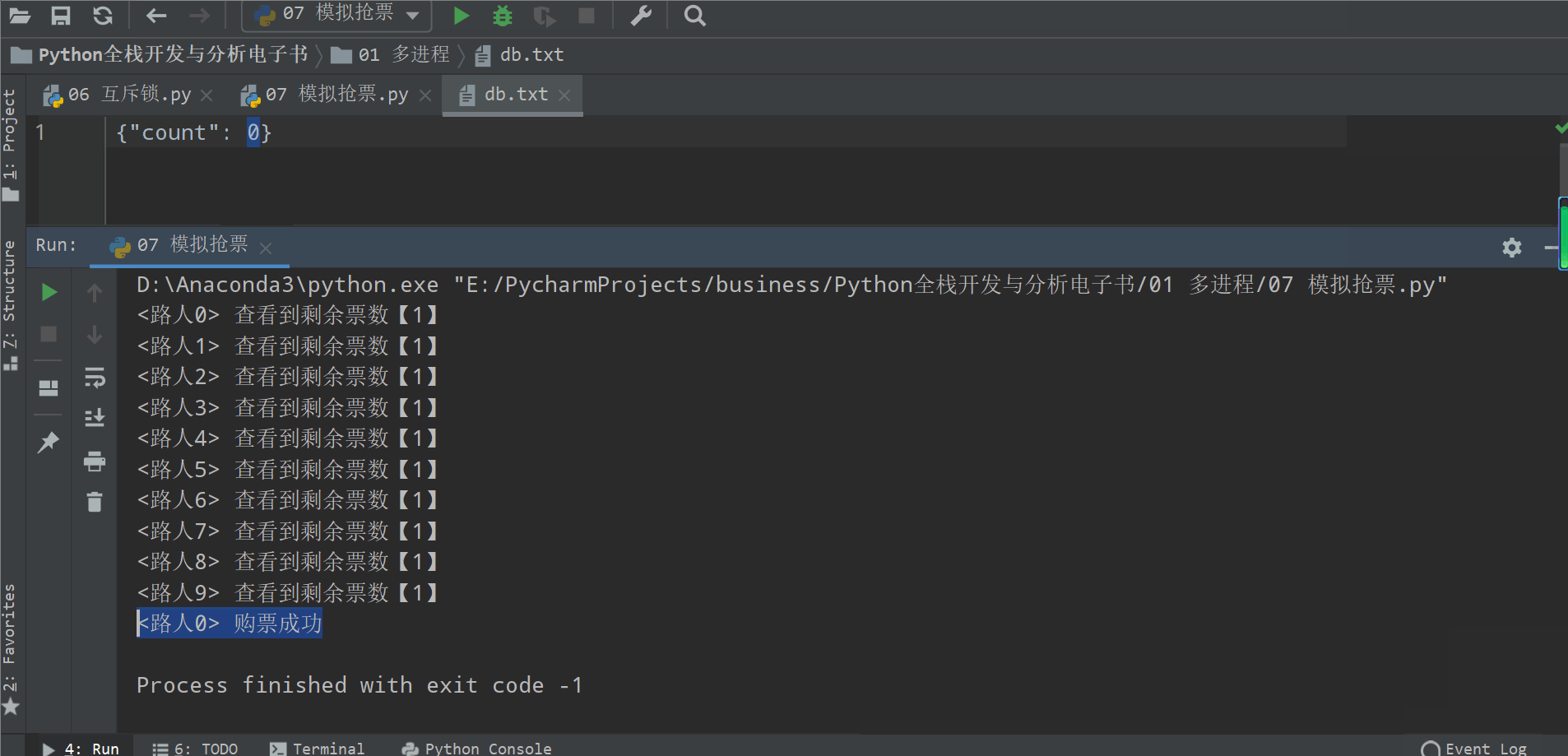
from multiprocessing import Process, Lockimport jsonimport timedef search(name):time.sleep(1)dic = json.load(open('db.txt', 'r', encoding='utf-8'))print('<%s> 查看到剩余票数【%s】' % (name, dic['count']))def get(name):time.sleep(1)dic = json.load(open('db.txt', 'r', encoding='utf-8'))if dic['count'] > 0:dic['count'] -= 1time.sleep(3)json.dump(dic, open('db.txt', 'w', encoding='utf-8'))print('<%s> 购票成功' % name)def task(name, lock):'查票可以并发,购票不能'search(name)lock.acquire()get(name)lock.release()if __name__ == '__main__':lock = Lock()for i in range(10):p = Process(target=task, args=('路人%s' % i, lock))p.start()
总结
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行地修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。
虽然可以用文件共享数据实现进程间通信,但问题是:
1、效率低(共享数据基于文件,而文件是硬盘上的数据)
2、需要自己加锁处理
因此我们最好找寻一种解决方案能够兼顾:
1、效率高(多个进程共享一块内存的数据)
2、帮我们处理好锁问题。
这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。
队列和管道都是将数据存放于内存中,而队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来,因而队列才是进程间通信的最佳选择。
我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。

若有收获,就点个赞吧
0 人点赞
