前言
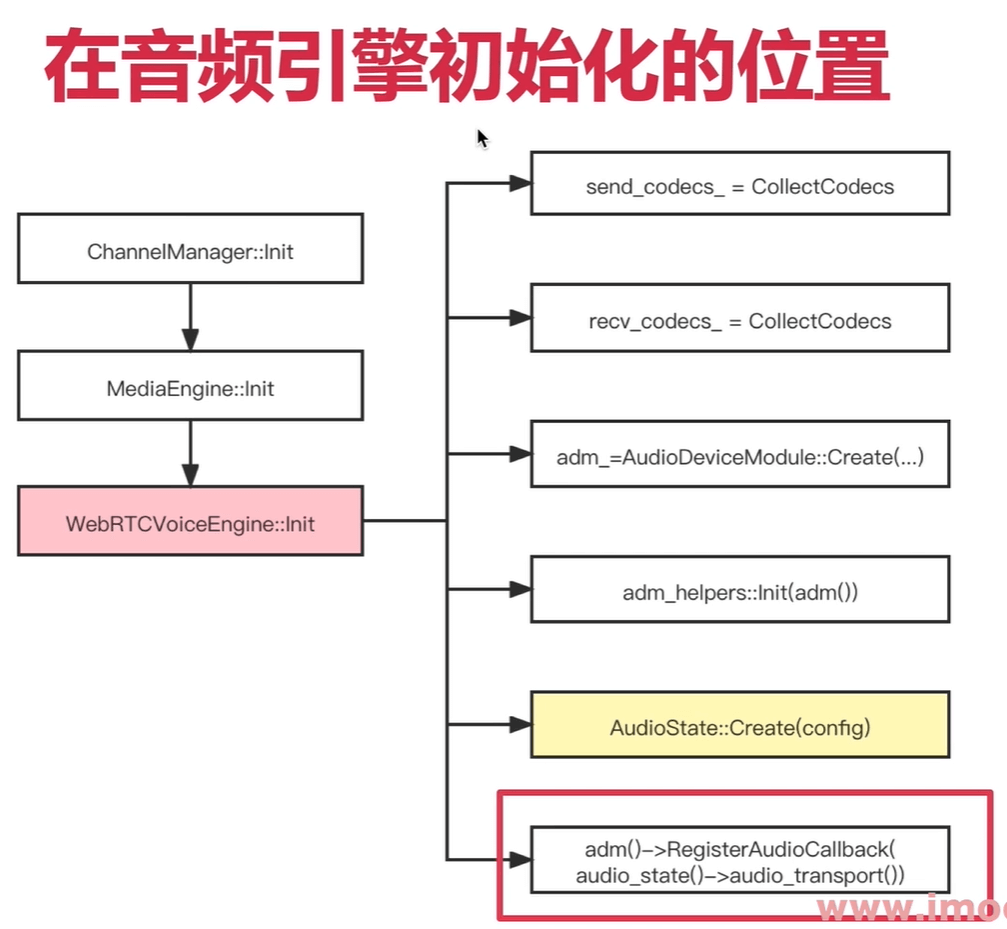
代码分析
创建AudioDeviceBuffer的流程

void WebRtcVoiceEngine::Init() {***// 4、创建ADM#if defined(WEBRTC_INCLUDE_INTERNAL_AUDIO_DEVICE)// No ADM supplied? Create a default one.if (!adm_) {adm_ = webrtc::AudioDeviceModule::Create(webrtc::AudioDeviceModule::kPlatformDefaultAudio, task_queue_factory_);}#endif // WEBRTC_INCLUDE_INTERNAL_AUDIO_DEVICERTC_CHECK(adm());****}
—》
rtc::scoped_refptr<AudioDeviceModule> AudioDeviceModule::Create(AudioLayer audio_layer,TaskQueueFactory* task_queue_factory) {RTC_DLOG(INFO) << __FUNCTION__;return AudioDeviceModule::CreateForTest(audio_layer, task_queue_factory);}
—》
rtc::scoped_refptr<AudioDeviceModuleForTest> AudioDeviceModule::CreateForTest(AudioLayer audio_layer,TaskQueueFactory* task_queue_factory) {****// Create the generic reference counted (platform independent) implementation.rtc::scoped_refptr<AudioDeviceModuleImpl> audioDevice(new rtc::RefCountedObject<AudioDeviceModuleImpl>(audio_layer,task_queue_factory));**}
—》
AudioDeviceModuleImpl::AudioDeviceModuleImpl(AudioLayer audio_layer,TaskQueueFactory* task_queue_factory): audio_layer_(audio_layer), audio_device_buffer_(task_queue_factory) {RTC_DLOG(INFO) << __FUNCTION__;}AudioDeviceBuffer audio_device_buffer_;
—》
AudioDeviceBuffer::AudioDeviceBuffer(TaskQueueFactory* task_queue_factory): task_queue_(task_queue_factory->CreateTaskQueue(kTimerQueueName,TaskQueueFactory::Priority::NORMAL)),audio_transport_cb_(nullptr),rec_sample_rate_(0),play_sample_rate_(0),rec_channels_(0),play_channels_(0),playing_(false),recording_(false),typing_status_(false),play_delay_ms_(0),rec_delay_ms_(0),num_stat_reports_(0),last_timer_task_time_(0),rec_stat_count_(0),play_stat_count_(0),play_start_time_(0),only_silence_recorded_(true),log_stats_(false) {RTC_LOG(INFO) << "AudioDeviceBuffer::ctor";#ifdef AUDIO_DEVICE_PLAYS_SINUS_TONEphase_ = 0.0;RTC_LOG(WARNING) << "AUDIO_DEVICE_PLAYS_SINUS_TONE is defined!";#endif}
注册回调RegisterAudioCallback

void WebRtcVoiceEngine::Init() {***// 7、 Connect the ADM to our audio path.// 注册回调,采集到音频数据后,由audio_transport()传输adm()->RegisterAudioCallback(audio_state()->audio_transport());***}
—》
int32_t AudioDeviceModuleImpl::RegisterAudioCallback(AudioTransport* audioCallback) {RTC_LOG(INFO) << __FUNCTION__;return audio_device_buffer_.RegisterAudioCallback(audioCallback);}
—》
int32_t AudioDeviceBuffer::RegisterAudioCallback(AudioTransport* audio_callback) {RTC_DCHECK_RUN_ON(&main_thread_checker_);RTC_DLOG(INFO) << __FUNCTION__;if (playing_ || recording_) {RTC_LOG(LS_ERROR) << "Failed to set audio transport since media was active";return -1;}audio_transport_cb_ = audio_callback;return 0;}
传递数据
就是采集到音频数据后,调用上一步的回调。

AudioDeviceWindowsCore::DoCaptureThreadPollDMO
DWORD AudioDeviceWindowsCore::DoCaptureThreadPollDMO() {****ULONG bytesProduced = 0;BYTE* data;// Get a pointer to the data buffer. This should be valid until// the next call to ProcessOutput.// 获取buffer数据和数据大小// bytesProduced=320,因为设置输出采样率16000,每个采样2个字节,每次采集10ms数据hr = _mediaBuffer->GetBufferAndLength(&data, &bytesProduced);if (FAILED(hr)) {_TraceCOMError(hr);keepRecording = false;assert(false);break;}if (bytesProduced > 0) {//断点值 160 = 320/2const int kSamplesProduced = bytesProduced / _recAudioFrameSize;// TODO(andrew): verify that this is always satisfied. It might// be that ProcessOutput will try to return more than 10 ms if// we fail to call it frequently enough.assert(kSamplesProduced == static_cast<int>(_recBlockSize));assert(sizeof(BYTE) == sizeof(int8_t));_ptrAudioBuffer->SetRecordedBuffer(reinterpret_cast<int8_t*>(data),kSamplesProduced);_ptrAudioBuffer->SetVQEData(0, 0);_UnLock(); // Release lock while making the callback.// 将数据输送到上层逻辑去处理_ptrAudioBuffer->DeliverRecordedData();_Lock();}****}
—》
int32_t AudioDeviceBuffer::DeliverRecordedData() {if (!audio_transport_cb_) {RTC_LOG(LS_WARNING) << "Invalid audio transport";return 0;}const size_t frames = rec_buffer_.size() / rec_channels_;const size_t bytes_per_frame = rec_channels_ * sizeof(int16_t);uint32_t new_mic_level_dummy = 0;uint32_t total_delay_ms = play_delay_ms_ + rec_delay_ms_;int32_t res = audio_transport_cb_->RecordedDataIsAvailable(rec_buffer_.data(), frames, bytes_per_frame, rec_channels_,rec_sample_rate_, total_delay_ms, 0, 0, typing_status_,new_mic_level_dummy);if (res == -1) {RTC_LOG(LS_ERROR) << "RecordedDataIsAvailable() failed";}return 0;}
—》
// Not used in Chromium. Process captured audio and distribute to all sending// streams, and try to do this at the lowest possible sample rate.int32_t AudioTransportImpl::RecordedDataIsAvailable(const void* audio_data,const size_t number_of_frames,const size_t bytes_per_sample,const size_t number_of_channels,const uint32_t sample_rate,const uint32_t audio_delay_milliseconds,const int32_t /*clock_drift*/,const uint32_t /*volume*/,const bool key_pressed,uint32_t& /*new_mic_volume*/) { // NOLINT: to avoid changing APIsRTC_DCHECK(audio_data);RTC_DCHECK_GE(number_of_channels, 1);RTC_DCHECK_LE(number_of_channels, 2);RTC_DCHECK_EQ(2 * number_of_channels, bytes_per_sample);RTC_DCHECK_GE(sample_rate, AudioProcessing::NativeRate::kSampleRate8kHz);// 100 = 1 second / data duration (10 ms).RTC_DCHECK_EQ(number_of_frames * 100, sample_rate);RTC_DCHECK_LE(bytes_per_sample * number_of_frames * number_of_channels,AudioFrame::kMaxDataSizeBytes);int send_sample_rate_hz = 0;size_t send_num_channels = 0;bool swap_stereo_channels = false;{MutexLock lock(&capture_lock_);send_sample_rate_hz = send_sample_rate_hz_;send_num_channels = send_num_channels_;swap_stereo_channels = swap_stereo_channels_;}std::unique_ptr<AudioFrame> audio_frame(new AudioFrame());InitializeCaptureFrame(sample_rate, send_sample_rate_hz, number_of_channels,send_num_channels, audio_frame.get());voe::RemixAndResample(static_cast<const int16_t*>(audio_data),number_of_frames, number_of_channels, sample_rate,&capture_resampler_, audio_frame.get());ProcessCaptureFrame(audio_delay_milliseconds, key_pressed,swap_stereo_channels, audio_processing_,audio_frame.get());// Typing detection (utilizes the APM/VAD decision). We let the VAD determine// if we're using this feature or not.// TODO(solenberg): GetConfig() takes a lock. Work around that.bool typing_detected = false;if (audio_processing_ &&audio_processing_->GetConfig().voice_detection.enabled) {if (audio_frame->vad_activity_ != AudioFrame::kVadUnknown) {bool vad_active = audio_frame->vad_activity_ == AudioFrame::kVadActive;typing_detected = typing_detection_.Process(key_pressed, vad_active);}}// Copy frame and push to each sending stream. The copy is required since an// encoding task will be posted internally to each stream.{MutexLock lock(&capture_lock_);typing_noise_detected_ = typing_detected;}RTC_DCHECK_GT(audio_frame->samples_per_channel_, 0);if (async_audio_processing_)async_audio_processing_->Process(std::move(audio_frame));elseSendProcessedData(std::move(audio_frame));return 0;}
里面调用ProcessCaptureFrame里面是进行音频的3A数据处理。。

若有收获,就点个赞吧
0 人点赞
