描述
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例
示例1:
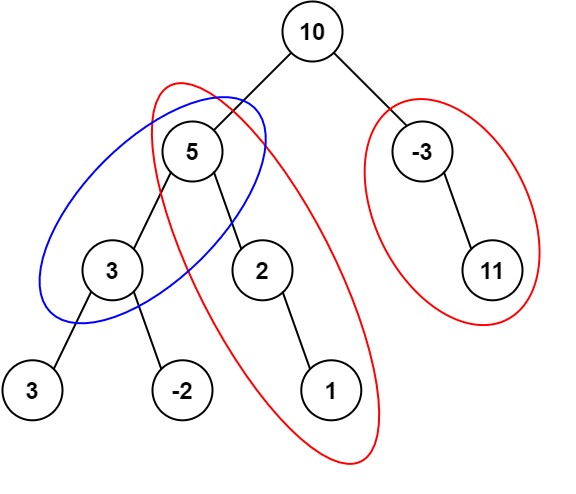
输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8输出:3解释:和等于 8 的路径有 3 条,如图所示。
示例2:
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22输出:3
提示
- 二叉树的节点个数的范围是
[0,1000] -109 <= Node.val <= 109-1000 <= targetSum <= 1000
解题思路
BFS + DFS
- 用
BFS遍历树中所有节点 - 对于每一个节点,用
DFS遍历以这个节点为根节点的所有路径 - 如果满足条件,将结果加一,然后递归遍历这个节点的左子树和右子树
缺点是时间复杂度高,相当于对每个节点都进行一次 DFS。
代码
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/class Solution {int sum = 0;int target;public int pathSum(TreeNode root, int targetSum) {Queue<TreeNode> queue = new LinkedList<>();target = targetSum;if (root == null) return 0;queue.offer(root);while (!queue.isEmpty()) {TreeNode node = queue.poll();findLoad(node, 0);if (node.left != null) {queue.offer(node.left);}if (node.right != null) {queue.offer(node.right);}}return sum;}public void findLoad(TreeNode node, int num) {if (node == null) return;int preNum = num + node.val;if (preNum == target) {sum++;}findLoad(node.left, preNum);findLoad(node.right, preNum);}}
前缀和 + 回溯
- 前缀和定义
- 用它干什么
- HashMap存的是什么
- 恢复状态代码的意义
//恢复状态代码 prefixSumCount.put(currSum, prefixSumCount.get(currSum) - 1);
前缀和定义
一个节点的前缀和就是 该节点 到 根 之间的路径和。
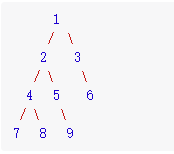
拿下图解释:
节点4的前缀和为:1 + 2 + 4 = 7
节点8的前缀和:1 + 2 + 4 + 8 = 15
节点9的前缀和:1 + 2 + 5 + 9 = 17
前缀和对于本题的作用
题目要求的是找出 路径和等于给定数值 的路径总数, 而:
两节点间的路径和 = 两节点的前缀和之差
还是拿下图解释: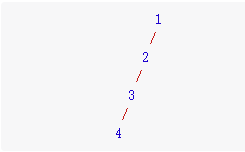
假如题目给定数值为5
节点1的前缀和为: 1
节点3的前缀和为: 1 + 2 + 3 = 6
prefix(3) - prefix(1) == 5
所以 节点1 到 节点3 之间有一条符合要求的路径( 2 —> 3 )
理解了这个之后,问题就得以简化:
我们只用遍历整颗树一次,记录每个节点的前缀和,并查询该节点的祖先节点中符合条件的个数,将这个数量加到最终结果上。
HashMap存的是什么
HashMap的key是前缀和, value是该前缀和的节点数量,记录数量是因为有出现复数路径的可能。
拿图说明:
下图树中,前缀和为1的节点有两个: 1, 0

恢复状态的意义
由于题目要求:路径方向必须是向下的(只能从父节点到子节点)
当我们讨论两个节点的前缀和差值时,有一个前提:
一个节点必须是另一个节点的祖先节点
换句话说,当我们把一个节点的前缀和信息更新到map里时,它应当只对其子节点们有效。
举个例子,下图中有两个值为2的节点(A, B)。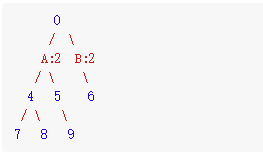
当我们遍历到最右方的节点 6 时,对于它来说,此时的前缀和为 2 的节点只该有 B , 因为从 A 向下到不了节点 6 (A 并不是节点 6 的祖先节点)。
如果我们不做状态恢复,当遍历右子树时,左子树中A的信息仍会保留在 map 中,那此时节点 6 就会认为A, B 都是可追溯到的节点,从而产生错误。
状态恢复代码的作用就是: 在遍历完一个节点的所有子节点后,将其从 map 中除去。
代码
class Solution {
int ans = 0;
int target;
Map<Integer, Integer> map;
public int pathSum(TreeNode root, int targetSum) {
map = new HashMap<Integer, Integer>(); // 记录路径中某个前缀和出现的次数
map.put(0, 1); // 防止包含根节点的时候找不到
target = targetSum;
dfs(root, 0);
return ans;
}
private void dfs(TreeNode node, int currSum) {
if (node == null) return;
// 判断是否存在符合条件的前缀和
currSum += node.val;
ans += map.getOrDefault(currSum - target, 0);
// 将当前前缀和记录下来
map.put(currSum, map.getOrDefault(currSum, 0) + 1);
// 继续往下递归
dfs(node.left, currSum);
dfs(node.right, currSum);
// 回溯,恢复状态
map.put(currSum, map.get(currSum) - 1);
}
}

若有收获,就点个赞吧
0 人点赞
