一、集成学习介绍
1.概念
集成学习(ensemble learning)也叫多分类器(multi-classifier)系统,构建并使用多个学习器来完成学习任务。
集成学习方法的直觉:如果一种数据表示不同但一样有用,此时,这种表示与其他表示的差异越大越好,它们提供了查看数据的全新角度,抓住了数据中被其他方法忽略的内容,因此可以提高模型在某个任务上的性能。集成学习中的基学习器就是学习到了对数据不同的表示。
每个模型从略有不同的角度观察数据来做出预测,得到“真相”的一部分,将各部分汇集,得到更准确的结果。(“盲人摸象”)
(联想:在文本的理解上,如果逆序处理和正序处理的效果一样好,说明在逆序序列上训练的RNN学到的表示虽然不同,但一样有用,双向RNN就是利用这个想法来提高正序RNN的性能。)
2.研究核心
集成学习的研究核心是如何产生并结合“好而不同”的个体学习器。
好,表示准确性。个体学习器至少不差于弱学习器。(弱学习器的泛化性能略好于随机猜测)
不同,表示多样性。个体学习器之间具有差异。(如果所有模型的偏差都在同一个方向,那么集成之后也会保留同样的偏差)
“好而不同”通常意味着使用非常不同的架构,甚至使用不同类型的学习方法。
假设基学习器的误差相互独立,此时,随着个体分类器数目的增大,集成之后的错误率将指数级的下降,最终趋于零。
3.分类

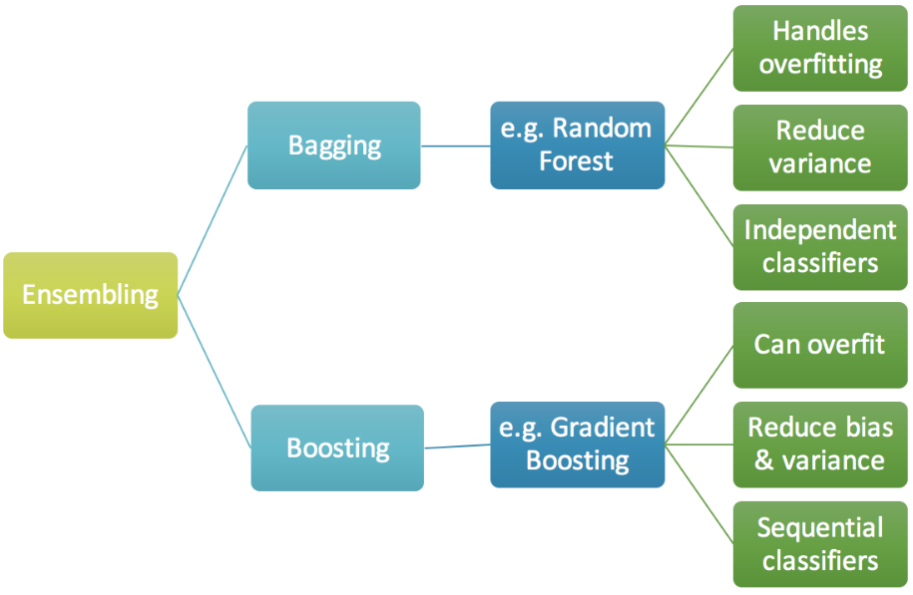
二、Bagging
1.Bagging思想:强强联合变更强
1.1 bagging流程
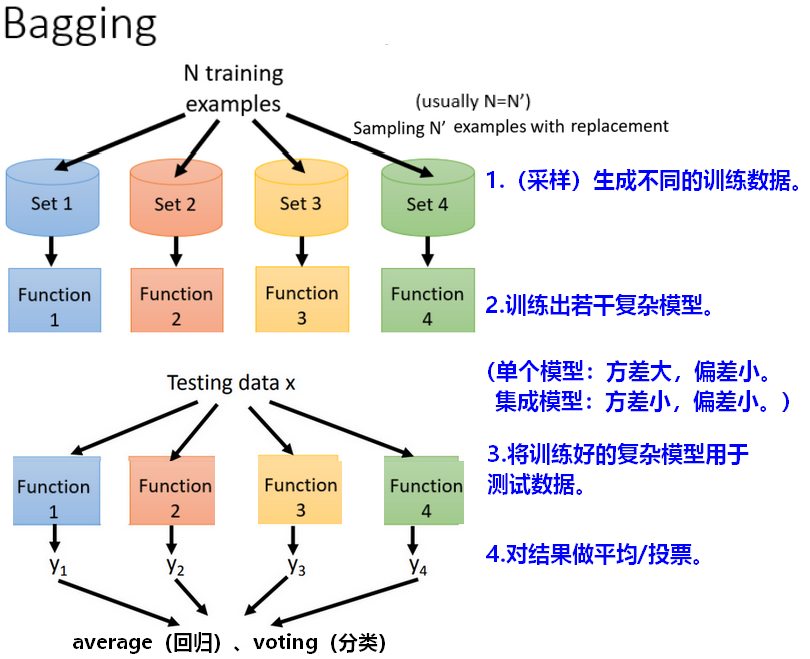
- bagging目的是降低方差(variance),提高稳定性,bagging并不会使模型在训练集上效果更好。
- bagging适用于复杂模型(强模型,方差大,偏差小),容易过拟合的场景,例如:决策树。
-
1.2 采样方法
训练模型时,从含有N条样本的原始数据中有放回的随机采样m次,得到m个样子子集,每个子集有N’条样本,每个子集各放入一个袋子(bag)中,袋子的数量为m个,训练得到m个不同的模型。
通常N’ = 60% * N。
【问题】如何进行采样,生成训练数据? 随机采样数据时,我们希望数据尽量相互独立不影响,这样训练的分类器也可以相互独立。
(trade-off)每次采样的数据量越少,则更独立,但数据量多,训练效果会更好。
随机选择特征时,如果一共有 n 维特征,一般随机选择
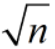 维的特征。
维的特征。(trade-off)每次选择的特征少,则更独立,但特征太少,会影响分类效果。
1.3 个体学习器:强模型
【问题】为什么bagging适用于复杂模型,而不是集成弱学习器?
假设有两个相互独立的同质分类器 ,方差为
,方差为 ,集成模型为
,集成模型为 ,集成后模型的方差为:
,集成后模型的方差为:
n个分类器集成后,真实方差大小满足:
【结论】
bagging能够降低方差,提高模型的稳定性,所以适用于原本方差较大的强分类器/复杂模型;
决策树容易过拟合,且分类器简单、计算量小,所以选用决策树作为个体学习器(决策树可以在训练集上做到0%的错误率)。
2.随机森林
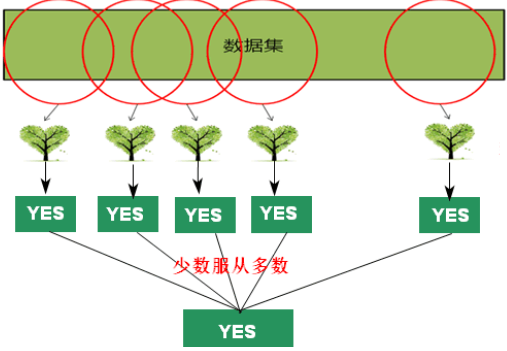
随机森林是由决策树构成的,传统的随机森林是通过之前的重采样的方法做,但是得到的结果是每棵树都差不多(效果并不好)。
【问题】如何得到不同的决策树?>>>如何得到相互独立的决策树?>>>如何获取训练数据?
- 重采样(resampling)数据,但只是这一步还不够;
- 在每次划分分支时,随机限制划分属性/问题,这样就算用同样的dataset,每次产生的决策树也会是不一样的,最后把所有的决策树的结果都集合起来,就会得到随机森林。
2.1 Out-of-bag验证
为了验证模型的效果,一般会划分训练集和验证集;使用OOB之后,就不用单独划分验证集了,而是使用之前没有参与训练的数据做验证(之前没见过),把结果取平均,得到的平均error就是随机森林(集成模型)最后的估测效果。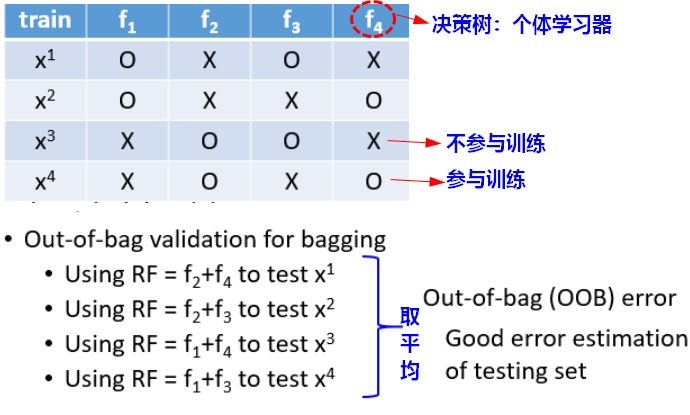
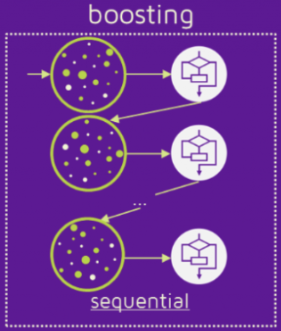
三、Boosting
1.Boosting思想:三个臭皮匠顶个诸葛亮
1.1 boosting流程
1)找到一个分类器 。
。
2)再找到一个互补的分类器 ,可以处理难以学习的样本数据。
,可以处理难以学习的样本数据。
3)结合所有分类器(加法模型)得到结果。
1.2 采样方法
为了得到具有互补效用的分类器,需要用不同的样本数据来训练,每一轮学习的数据集都是更新过的且包含上一轮中较难学习的数据。
【问题】如何获得不同的训练数据集?
方法1:对训练数据重新赋予样本权重(Re-weighting),来形成每一轮学习的数据集。
在实际应用中,可以直接给Loss损失函数赋予样本权重。
如果有一个样本的权重较大,在训练时就会被多考虑一些。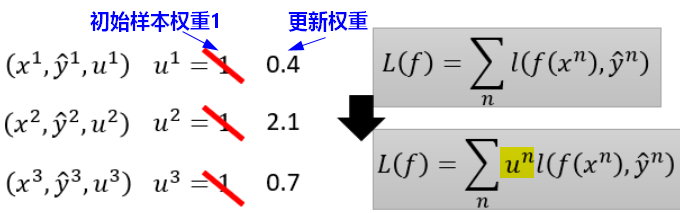
方法2:对于无法接受带权重样本的基学习算法,可以使用重采样(re-sampling)。
1.3 个体学习器:弱模型
通过生成不同的训练数据来得到不同的个体学习器。弱模型的偏差大,方差小。
Boosting适用于弱模型,提升弱分类器效果,Boosting主要关注降低偏差。如果分类器的错误率低于50%,使用boosting后可以将错误率降到0%。
【问题】为什么要使用弱模型作为基学习器?<br /> 提升(boosting)方法组合弱分类器,构成一个强分类器。在PAC(概率近似正确)框架下,强<br /> 可学习和弱可学习是等价的;而且弱学习算法通常更容易。<br /> 大多数提升方法是改变训练数据的概率分布(权值分布),对于boosting提升方法,有**两个核心**<br />** 问题**:一是每一轮如何改变训练数据的概率/权值分布;二是如何组合弱分类器成一个强分类器。
以决策树为基学习器的提升方法叫做提升树(boosting tree),例如:Adaboost,GBDT。树的线性组合可以很好的拟合数据,是一个高功能的学习算法。
- 分类器的训练是有顺序(sequentially)的。
Boosting算法在训练每一轮都要检查当前生成的基学习器是否满足条件(错误率小于50%),如果不满足,则抛弃该基学习器且学习过程停止。
1.4 前向分布算法
boosting最后集成的模型是加法模型:
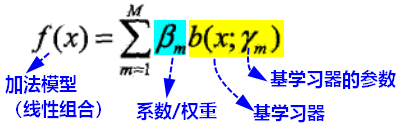
损失函数以及优化问题表示为: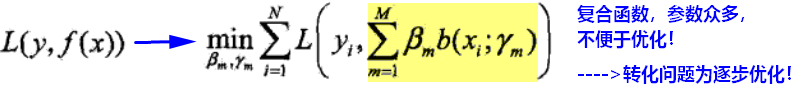
前向分布算法(forward stagewise algorightm):从前向后,每一步只学习一个基学习器以及系数,逐步逼近优化目标函数。每一步只需优化: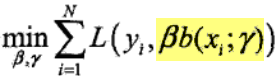

1.5 提升树算法
提升树算法采用基学习器线性组合的加法模型以及前向分布算法。

提升树用于回归还是分类问题,区别在于损失函数的不同:回归(平方误差函数)、分类(指数函数)。分类问题。提升树算法是将Adaboost中的基学习器改为二叉分类树。
- 回归问题:

2.Adaboost
2.1 Adaboost思想
Adaboost中的学习器使用的是决策树桩(decision stump),即仅有一层划分的决策树,目的是分类。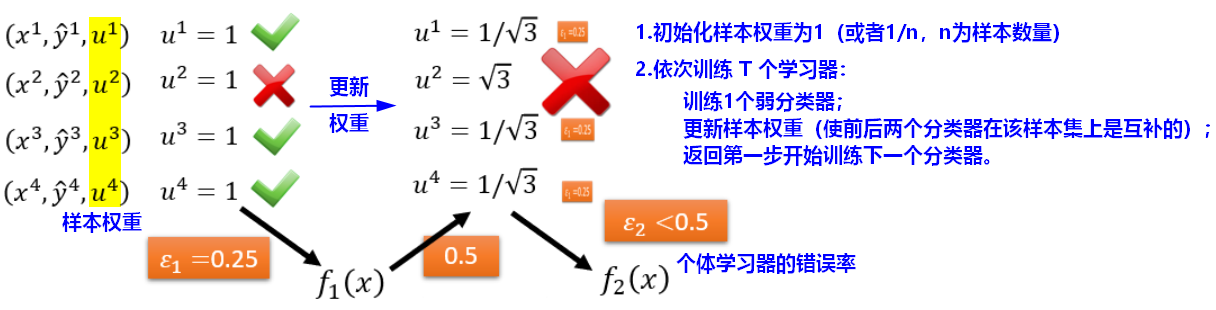
2.2 Re-weight:重赋权
【问题】如何更新样本权重,使得可以训练出互补的模型?
模型的互补效果通过个体分类器的错误率来考察。
- 分类器
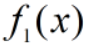 的错误率为(做了归一化normalization):
的错误率为(做了归一化normalization):

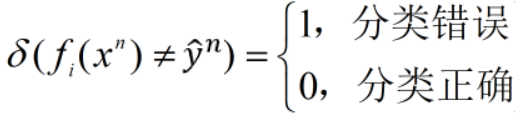
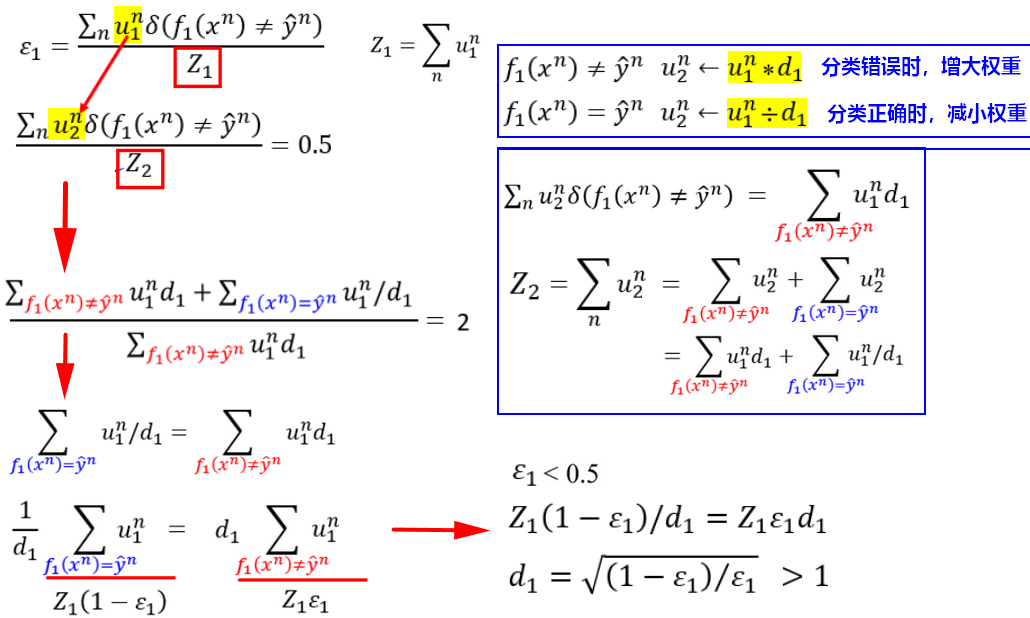
- 更新权重
 ,得到新的训练数据集,如果基于新的训练集可以得到互补模型,此时的数据集在上的分类效果应该是相当于随机的:
,得到新的训练数据集,如果基于新的训练集可以得到互补模型,此时的数据集在上的分类效果应该是相当于随机的:
2.3 Adaboost算法

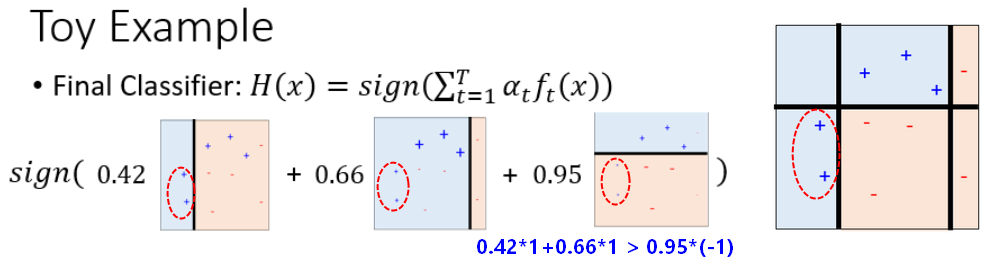
不改变训练数据,而是改变训练数据的权值分布,使得训练数据在基本分类器的学习中起到不同的作用,这是Adaboost的特点之一。
知道如何更新样本权重后,就可以不断使用更新的样本集去训练互补的分类器,最后将分类器聚合:
2.4 Adaboost效果推导
【结论1】
随着个体学习器的数量T越来越多,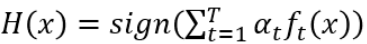 在训练集上的错误率越来越小,逐渐变成0。Adaboost具有适应性,即可以适应弱分类器各自的训练误差,这是Adaboost(Adaptive)名字的由来。
在训练集上的错误率越来越小,逐渐变成0。Adaboost具有适应性,即可以适应弱分类器各自的训练误差,这是Adaboost(Adaptive)名字的由来。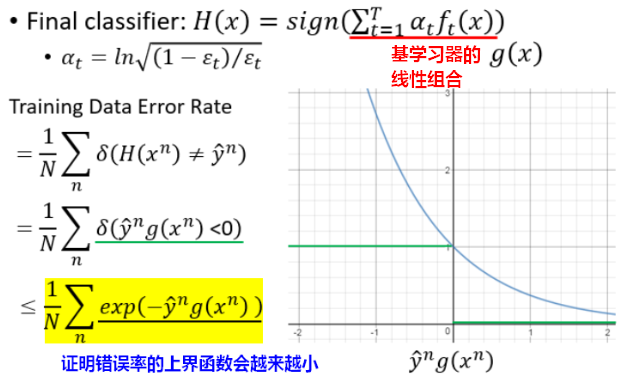

【结论2】
随着训练次数的增多(即加入越来越多的学习器),集成的模型在测试集上的错误率也会不断下降,不会出现过拟合问题。Adaboost有较强的鲁棒性。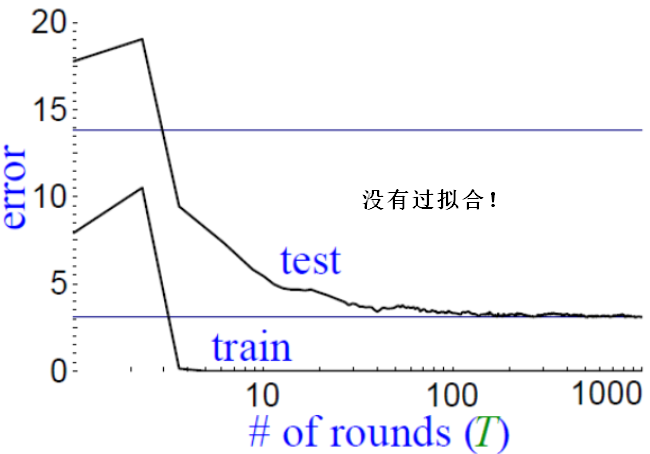
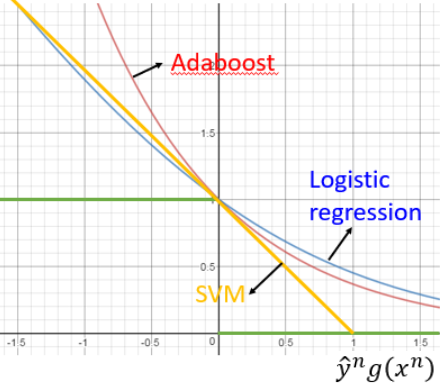
因为随着训练集上的错误率越来越小,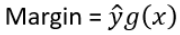 会越来越大,也就是说即使在已经分类正确的情况下(训练集error rate=0),训练次数T越大,margin还是会不断增大,预测会得到更好的效果。
会越来越大,也就是说即使在已经分类正确的情况下(训练集error rate=0),训练次数T越大,margin还是会不断增大,预测会得到更好的效果。
3.GBDT
【详见“集成学习:GBDT,XGBoost”】
Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向。这句话有一点拗口,损失函数(loss function)描述的是模型的不靠谱程度,损失函数越大,则说明模型越容易出错(其实这里有一个方差、偏差均衡的问题,但是这里就假设损失函数越大,模型越容易出错)。如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其梯度(Gradient)的方向上下降。
4.XGBoost
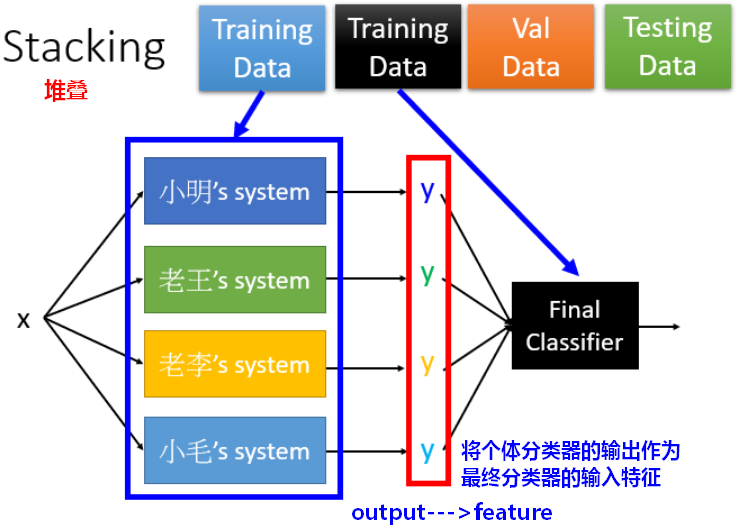
四、Stacking
1.Stacking思想

若有收获,就点个赞吧
0 人点赞
