循環神經網絡(recurrent neural network)RNN是一類用於處理序列**數據**的神經網絡,即某一時刻的輸出結果會受到前面時刻的輸入的影響。
1.RNN拓扑结构
1.1基本的RNN结构
Simple RNN
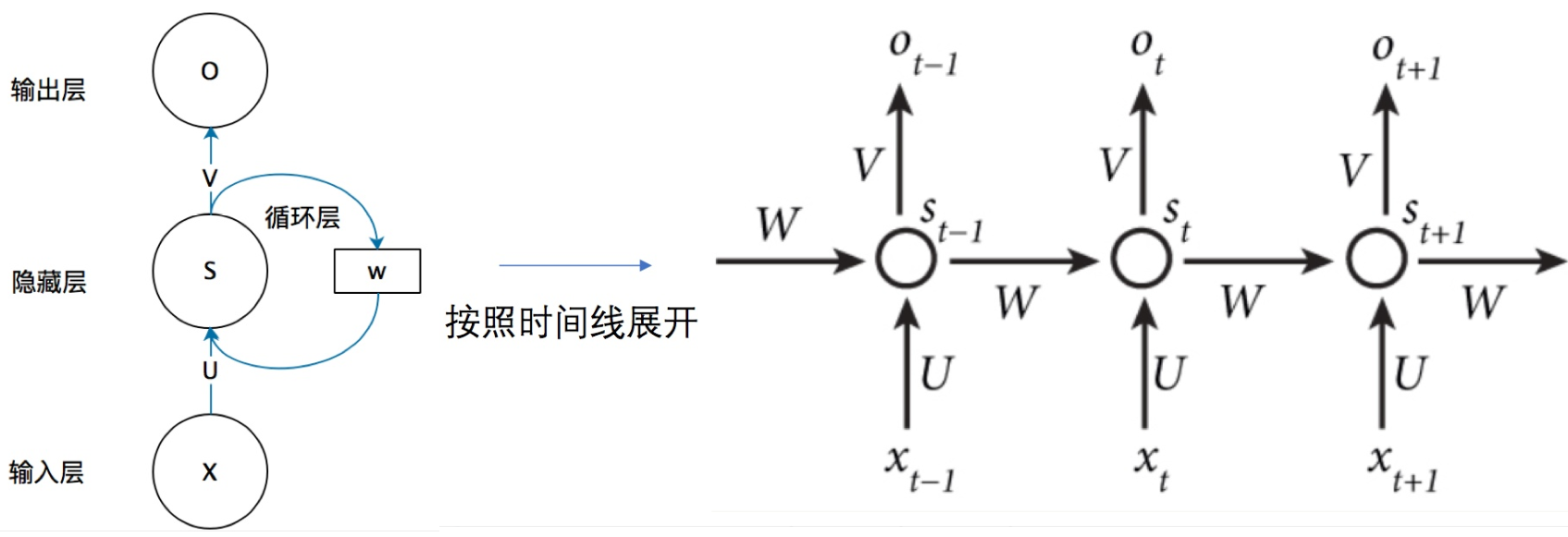

【注意點】
- t-1時刻的 hidden layer 和 t 時刻的 hidden layer之間是全連接(fully connected)
- 每一時刻的拓撲結構都是相同的,初始化時,U/V/W都是同一份矩陣。
- 正向傳播時,每一時刻都求得 Loss損失;反向傳播時,根據最後一個時刻的Loss推導調整 U/V/W,同時,之前每一時刻的 U/V/W也被調整。
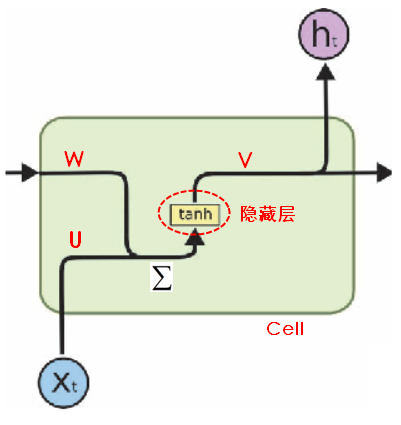
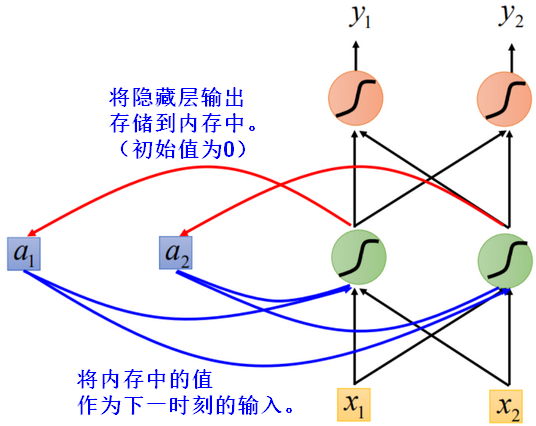
- 因为有上一时刻内存中的值作为输入,在RNN中即使是一样的原始输入,可能有不一样的输出。
内存中的值在每一个时刻都会被“清洗掉”(重新赋值)。
理论上,在时刻t,simpleRNN应该能够记住之前0~(t-1)个时间步见过的信息,但实际上因为梯度消失问题,随着层数的增加,网络变得无法训练,实际上不可能学到这种长期依赖。LSTM和GRU就是为了解决这个问题而设计的,可以携带信息跨越多个时间步。
RNN中同一个网络在不同的时刻被反复使用。
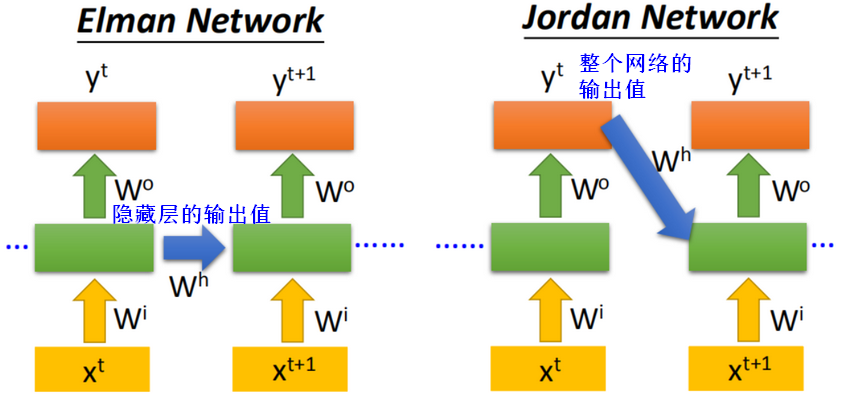
- RNN的网络结构可以任意设计,比如:多层、双向、Elman、Jordan等。
Deep RNN

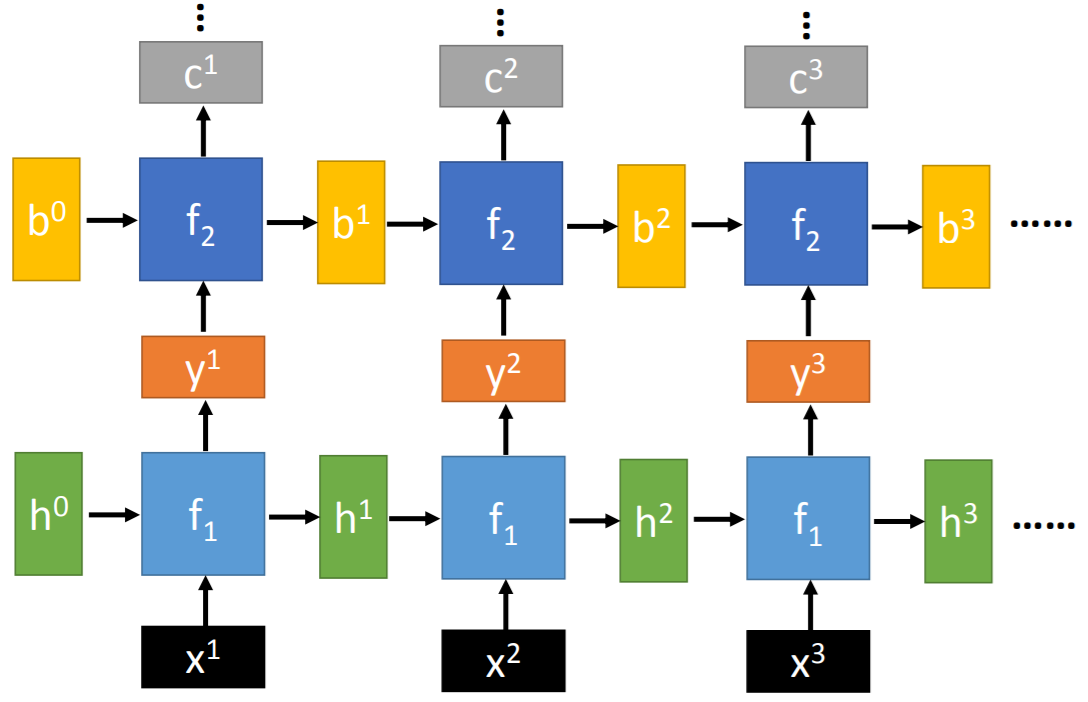
Elman、Jordan
双向RNN
双向(Bidirectional)RNN在每个输出的时刻,看到数据的范围更广,表现可以更好。
1.2 LSTM
梯度消失/爆炸问题
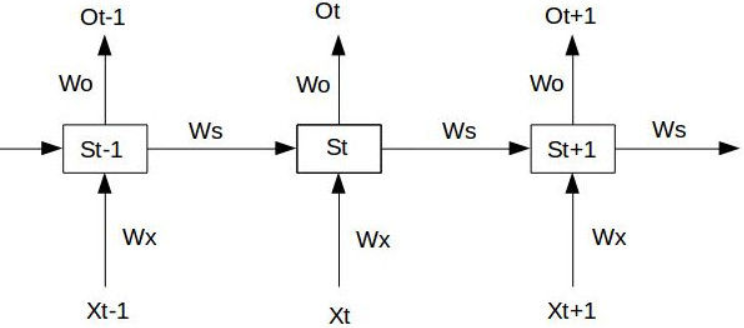
如图中的SimpleRNN网络中,对于前3个时刻(暂不考虑激活函数),中间状态S和最终输出O:
在 时刻,假设损失函数为:
时刻,假设损失函数为: ,总体的损失为每一时刻的累加值
,总体的损失为每一时刻的累加值 ,
,
在时刻,对参数求偏导:
由上述求导过程可以看出,对 求导没有长期依赖,但对
求导没有长期依赖,但对 求导会随着时间序列产生长期依赖。
求导会随着时间序列产生长期依赖。
对于任意时刻t,有一般化结论: ,代入激活函数,则
,代入激活函数,则 ,
,
由于 ,当
,当 很小时,连乘趋近于0,当很大时,连乘趋近于无穷,于是造成了梯度消失、梯度爆炸。
很小时,连乘趋近于0,当很大时,连乘趋近于无穷,于是造成了梯度消失、梯度爆炸。
造成梯度消失/爆炸的关键是 ,如果令
,如果令 ,就能解决这个问题。LSTM就是通过遗忘门,控制了中间状态的输出,解决了梯度消失/爆炸问题。
,就能解决这个问题。LSTM就是通过遗忘门,控制了中间状态的输出,解决了梯度消失/爆炸问题。
LSTM: Long Short-Term Memory Unit 长短时记忆单元,表示长时间(long)的短期记忆(shor-term),在基本的RNN网络结构中,内存中的值在每个时间点会被重新赋值,每个时间步(timestep)是循环在t时刻的输出,包含时间步0~t的信息,即关于过去的全部信息。在LSTM中,因为有forget gate,短期记忆(short-term)可以得到长时间(long)保存。
LSTM单元的作用:允许过去的信息稍后重新进入,从而解决梯度消失/爆炸问题。
LSTM神经元
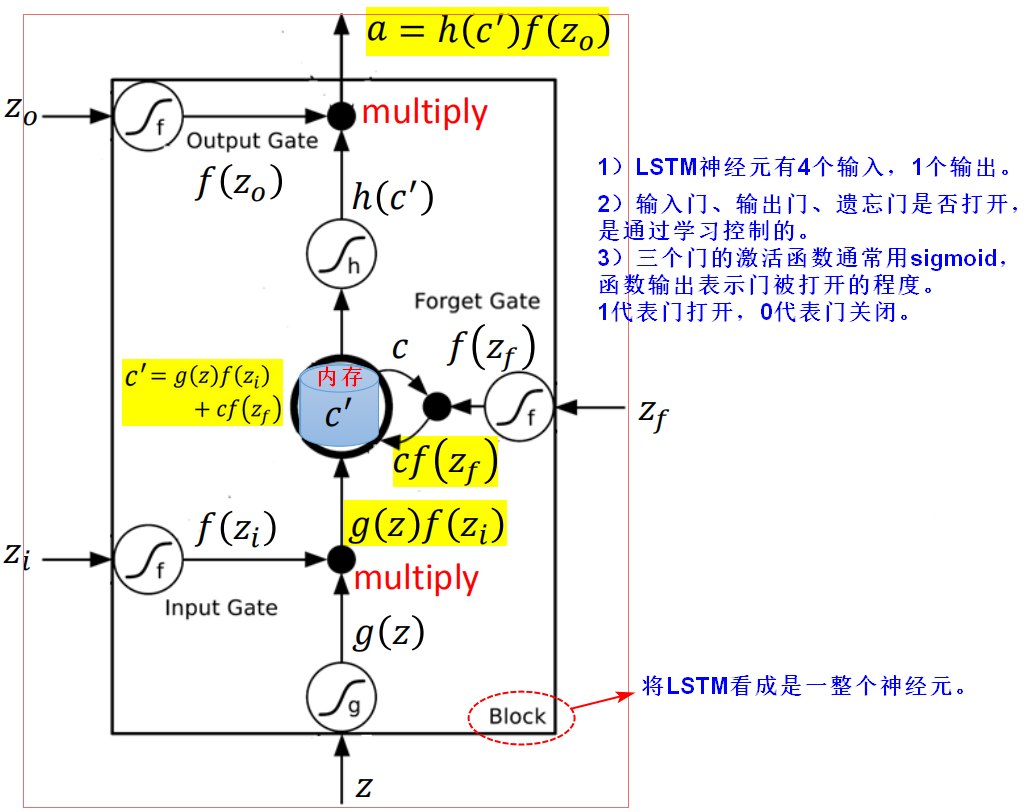
线性变换
input(x1,_x_2)会乘以不同的weight当做LSTM不同的输入,即乘以不同的weight去操控input gate、forget gate,output gate。
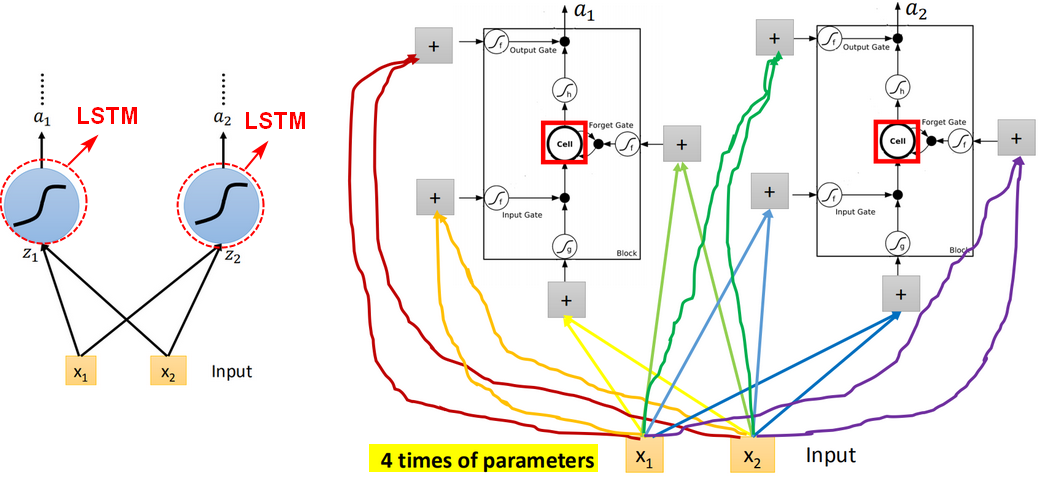
【问题】普通神经元到LSTM神经元,输入从1个变成4个,具体如何操作呢?
假设有4个LSTM神经元,输入向量为X,将X乘以一个矩阵完成一次线性变换(transform),将X进行4次不同的线性变换之后,得到4个向量Z,每个向量Z的维数都和LSTM神经元的数量一致,每个向量Z分别作为LSTM的4个输入。c表示携带(carry),即携带着跨越时间步的信息。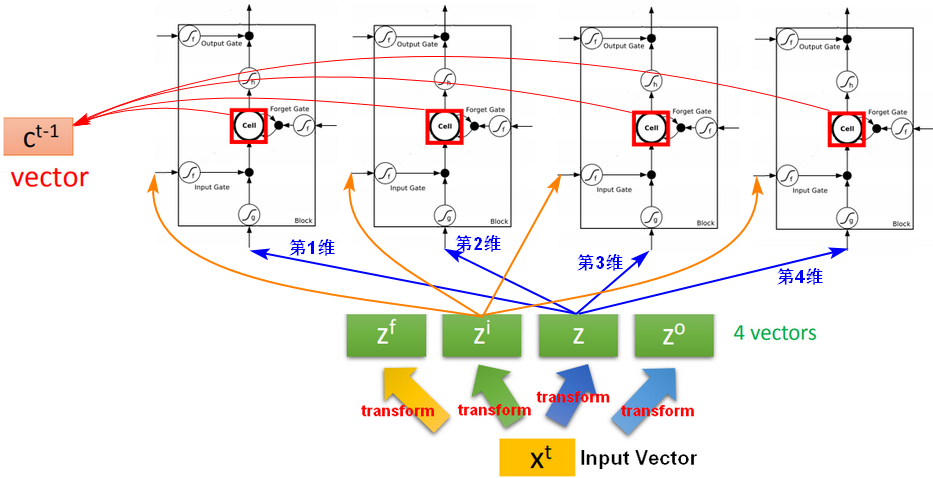
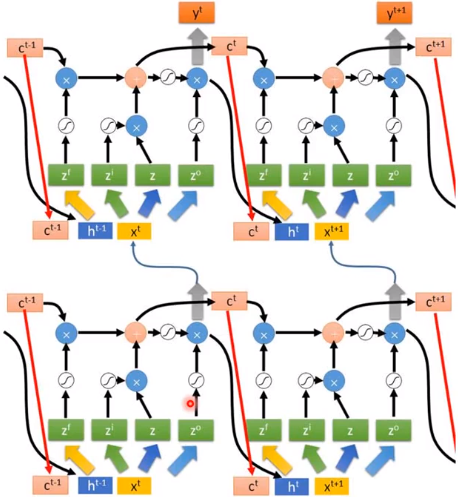
LSTM最终形态(单层)
- 没有peephole
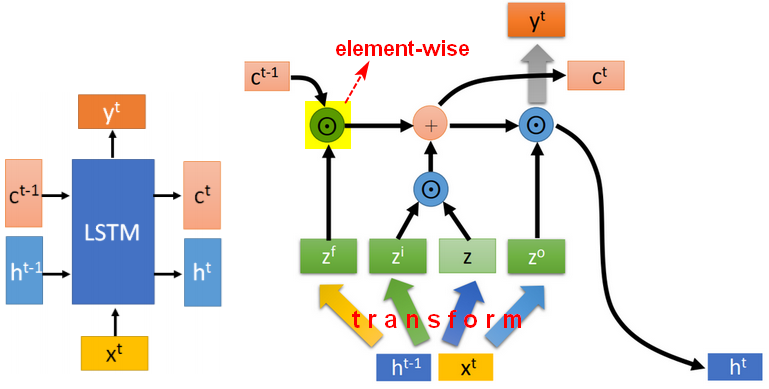
遗忘门、输入门和输出门,使用sigmoid函数是为了控制门的开启和关闭。
相邻时刻的状态C变化时较慢较小的,相邻时刻的输出h的变化是较快较大的。

- 有peephole
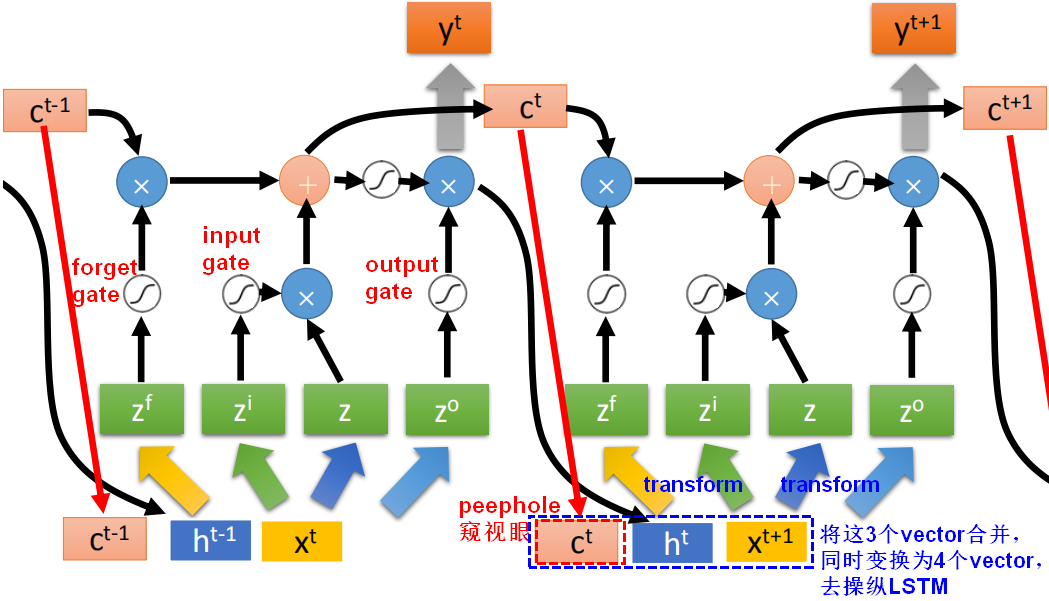
LSTM最终形态(多层)
1.3 GRU
LSTM实验
GRU: Gated Recurrent Unit:相比LSTM的3个门,GRU变成了2个门,但performance跟LSTM差不多(少了1/3的参数,也是比较不容易overfitting)。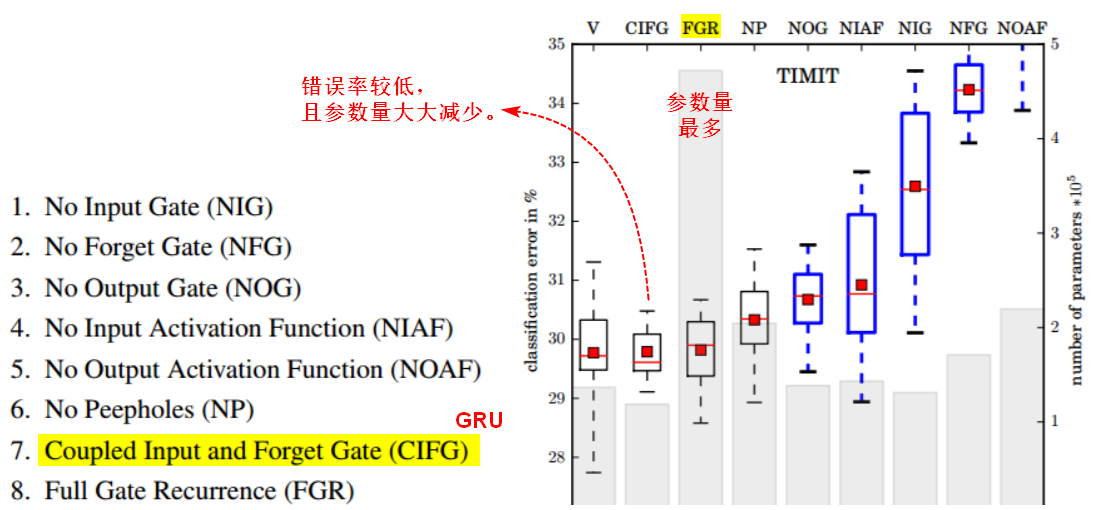
GRU结构
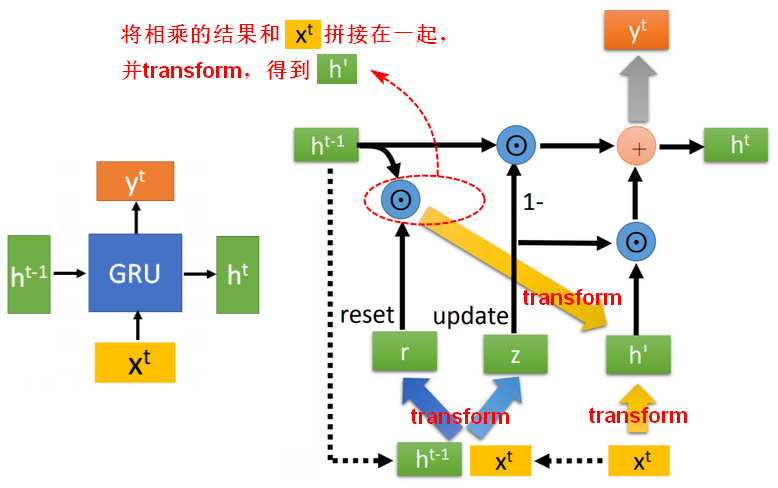


GRU使用更新门(Update gate),通过缩放到(0,1)来决定是否将上一时刻的  传递给当前时刻的
传递给当前时刻的 ;使用reset gate来控制我们需要的哪一部分参与运算。
;使用reset gate来控制我们需要的哪一部分参与运算。
2.RNN的应用
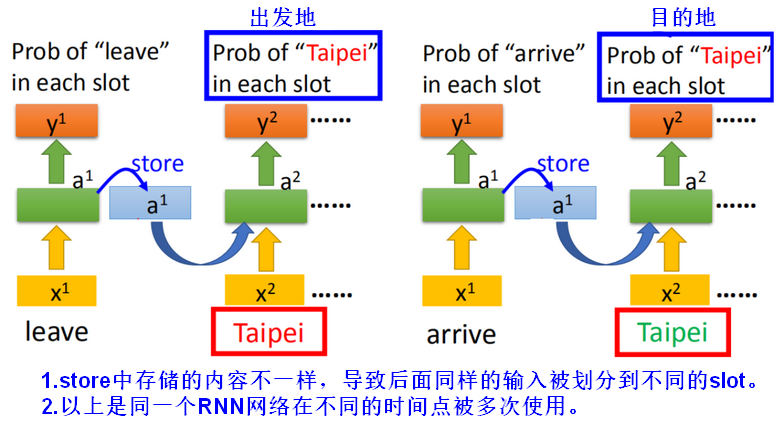
2.1Slot Filling
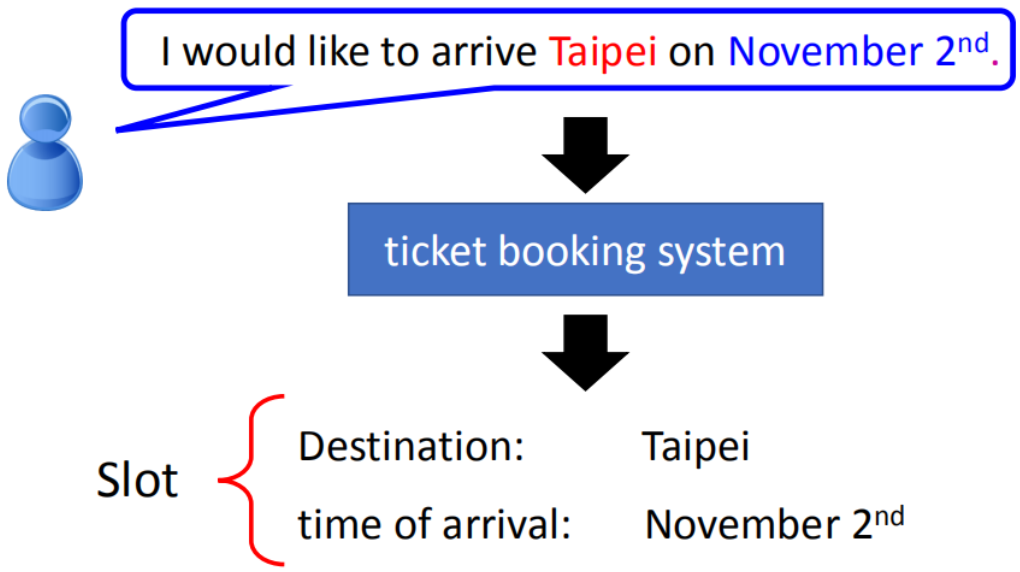
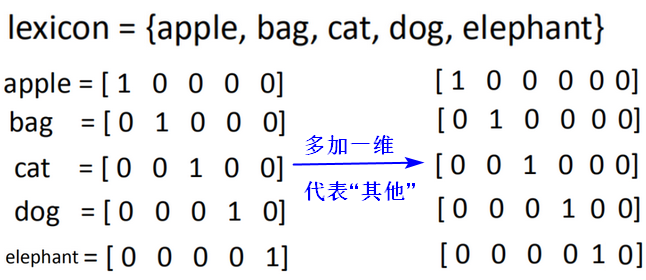
词向量的表示
- 1 of N encoding
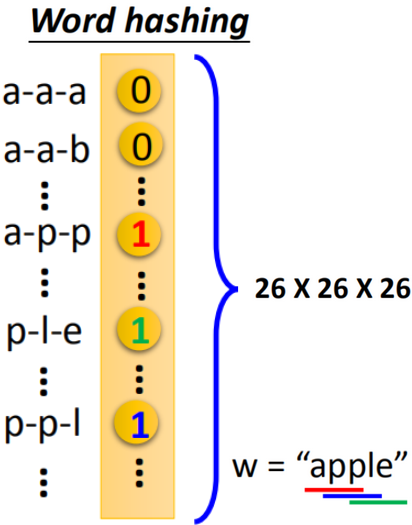
- word hashing
来源: 1.https://medium.com/@saurabh.rathor092/simple-rnn-vs-gru-vs-lstm-difference-lies-in-more-flexible-control-5f33e07b1e57 2.https://jhui.github.io/2017/03/15/RNN-LSTM-GRU/ 3.https://zhuanlan.zhihu.com/p/30844905 4.李宏毅《机器学习》2017 5.RNN梯度消失和爆炸的原因:https://zhuanlan.zhihu.com/p/28687529

若有收获,就点个赞吧
0 人点赞
