- we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A top-down architecture with lateral connections is developed for building high-level semantic feature maps at all scales. This architecture, called a Feature Pyramid Network (FPN), shows significant improvement as a generic feature extractor in several applications.
- Recognizing objects at vastly different scales is a fundamental challenge in computer vision.
Fast R-CNN [11] and Faster R-CNN [29] advocate using features computed from a single scale, because it offers a good trade-off between accuracy and speed. 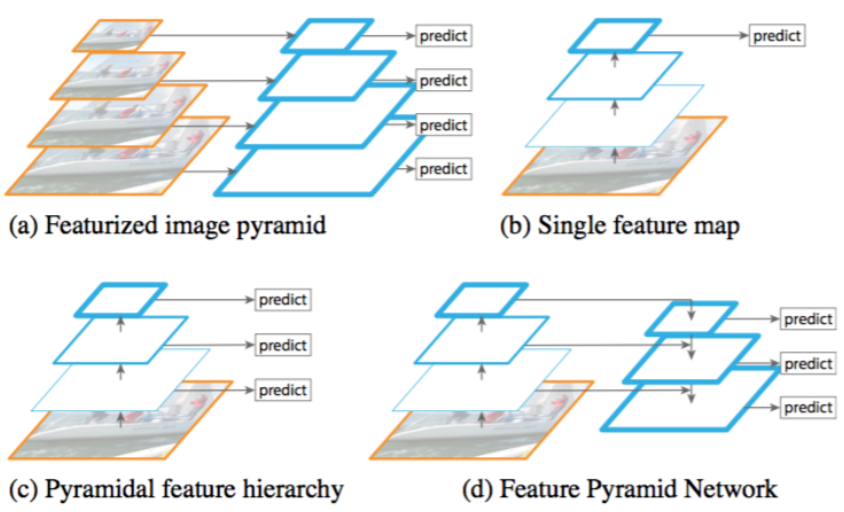
(a) Using an image pyramid to build a feature pyramid. Features are computed on each of the image scales independently, which is slow.The principle advantage of featurizing each level of an image pyramid is that it produces a multi-scale feature representation in which all levels are semantically strong, including the high-resolution levels.【特征化的图像金字塔】
(b) Recent detection systems have opted to use only single scale features for faster detection.
(c) An alternative is to reuse the pyramidal feature hierarchy computed by a ConvNet as if it were a featurized image pyramid.
FPN
(d) Our proposed Feature Pyramid Network (FPN) is fast like (b) and (c), but more accurate. In this figure, feature maps are indicate by blue outlines and thicker outlines denote semantically stronger features.
- FPN:we rely on an architecture that combines low-resolution, semantically strong features with high-resolution, semantically weak features via a top-down pathway and lateral connections (自顶向下的路径和横向连接)without sacrificing representational power, speed, or memory..【特征金字塔】
- FPN:our method leverages the architecture as a feature pyramid where predictions (e.g., object detections) are independently made on each level.
- our pyramid structure (FPN) can be trained end-to-end with all scales and is used consistently at train/test time, which would be memory-infeasible using image pyramids.
FPN Structure
Our method takes a single-scale image of an arbitrary size as input, and outputs proportionally sized feature maps at multiple levels, in a fully convolutional fashion. This process is independent of the backbone convolutional architectures (e.g., [19, 36, 16]), and in this paper we present results using ResNets [16]. The construction of our pyramid involves a bottom-up pathway(自下而上的路径), a top-down pathway(自上而下的路径), and lateral connections(横向连接), as introduced in the following.
Bottom-up pathway. The bottom-up pathway is the feed-forward computation of the backbone ConvNet.There are often many layers producing output maps of the same size and we say these layers are in the same network stage. For our feature pyramid, we define one pyramid level for each stage. We choose the output of the last layer of each stage as our reference set of feature maps, which we will enrich to create our pyramid. This choice is natural since the deepest layer of each stage should have the strongest features.
Top-down pathway and lateral connections. The top-down pathway hallucinates higher resolution features by upsampling spatially coarser, but semantically stronger, feature maps from higher pyramid levels. These features are then enhanced with features from the bottom-up pathway via lateral connections. Each lateral connection merges feature maps of the same spatial size from the bottom-up pathway and the top-down pathway. The bottom-up feature map is of lower-level semantics, but its activations are more accurately localized as it was subsampled fewer times.
With a coarser-resolution feature map, we upsample the spatial resolution by a factor of 2 (using nearest neighbor upsampling for simplicity). The upsampled map is then merged with the corresponding bottom-up map (which undergoes a 1×1 convolutional layer to reduce channel dimensions) by element-wise addition. This process is iterated until the finest resolution map is generated. To start the iteration, we simply attach a 1×1 convolutional layer on C5 to produce the coarsest resolution map. Finally, we append a 3 × 3 convolution on each merged map to generate the final feature map, which is to reduce the aliasing effect of upsampling. (减少上采样的混叠效应)(在统计、信号处理和相关领域中,混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。)
Because all levels of the pyramid use shared classifiers/regressors as in a traditional featurized image pyramid, we fix the feature dimension (numbers of channels, denoted as d) in all the feature maps. We set d=256 in this paper and thus all extra convolutional layers have 256-channel outputs.Applications
Our method is a generic solution for building feature pyramids inside deep ConvNets.FPN for RPN
In the original RPN design, a small subnetwork is evaluated on dense 3×3 sliding windows, on top of a single-scale convolutional feature map, performing object/non-object binary classification and bounding box regression. This is realized by a 3×3 convolutional layer followed by two sibling 1×1 convolutions for classification and regression, which we refer to as a network head. The object/non-object criterion and bounding box regression target are defined with respect to a set of reference boxes called anchors [29]. The anchors are of multiple pre-defined scales and aspect ratios in order to cover objects of different shapes.
We adapt RPN by replacing the single-scale feature map with our FPN. We attach a head of the same design (3×3 conv and two sibling 1×1 convs) to each level on our feature pyramid. Because the head slides densely over all locations in all pyramid levels, it is not necessary to have multi-scale anchors on a specific level. Instead, we assign anchors of a single scale to each level.(特征金字塔的每一层只需分配单尺度大小的锚点)
We assign training labels to the anchors based on their Intersection-over-Union (IoU) ratios with ground-truth bounding boxes as in [29].
We note that the parameters of the heads are shared across all feature pyramid levels.FPN for Fast R-CNN
Fast R-CNN [11] is a region-based object detector in which Region-of-Interest (RoI) pooling is used to extract features. Fast R-CNN is most commonly performed on a single-scale feature map. To use it with our FPN, we need to assign RoIs of different scales to the pyramid levels.(为特征金字塔的每层分配不同尺度的RoI)
Formally, we assign an RoI of width w and height h (on the input image to the network) to the level Pk of our feature pyramid by:
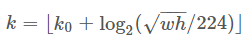
Here 224 is the canonical ImageNet pre-training size, and k0 is the target level on which an RoI with w×h=224^2should be mapped into. Analogous to the ResNet-based Faster R-CNN system [16] that uses C4 as the single-scale feature map, we set k0 to 4. Intuitively, Eqn.(1) means that if the RoI’s scale becomes smaller (say, 1/2 of 224), it should be mapped into a finer-resolution level (say, k=3).(更小的RoI尺度映射到更精细的分辨率级别)

若有收获,就点个赞吧
0 人点赞
