1.Transformer
1.1 Transformer简介
Transformer模型就是加了自注意力机制(Self-attention)的Seq2seq。可以使用Seq2seq的地方,就可以使用Transformer。
Seq2seq网络结构中,Encoder和Decoder的主体都是RNN,计算是分时刻的,难以实现并行化;即便是用CNN网络替代,虽然可以并行化,但为了覆盖整个输入内容,需要叠加多层。
Transformer的出现,就实现了并行化计算,而且也不需要叠加多层。
1.2 Self-Attention层
所有可以用带注意力机制的RNN的地方,都可以用Self-Attention来替代。
使用Self-Attention层,不仅兼顾到了输入的整体信息,也实现了并行化计算。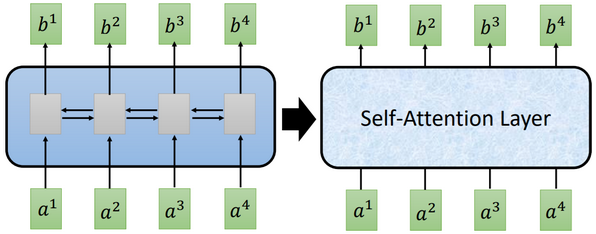
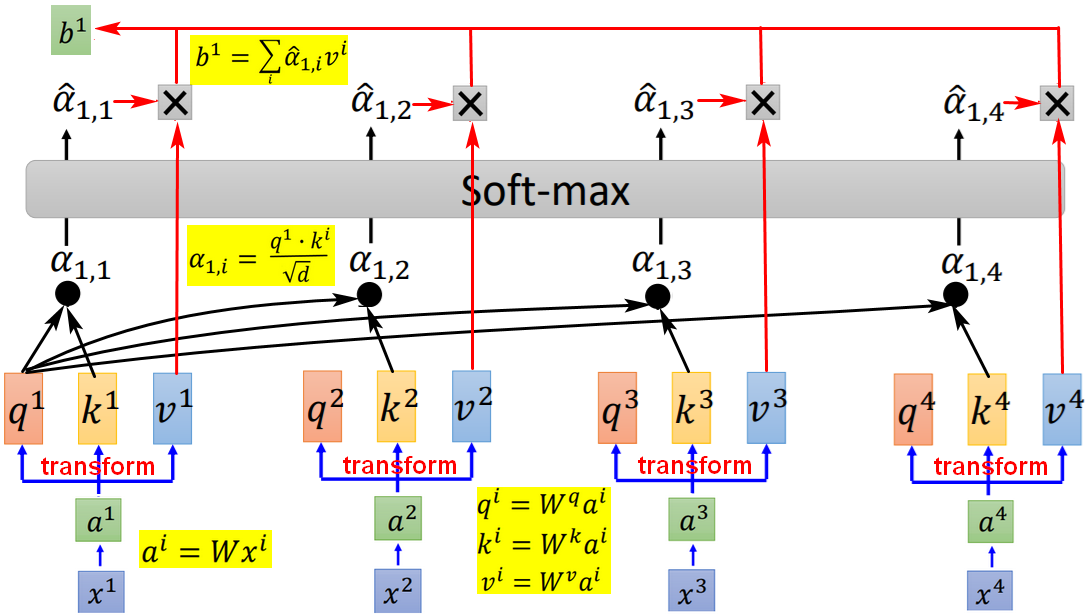
- q(query):用来匹配其他向量;
- k(key):用来被匹配;拿某个query对每个key做attention,表示注意力关注点。
- v:代表需要被抽取的信息。
- α:标量,代表注意力(Attention)。
 ,其中d是q和k的维度,因为维度越多,点积越大,除以维度的开方可以将注意力标量值归一化。
,其中d是q和k的维度,因为维度越多,点积越大,除以维度的开方可以将注意力标量值归一化。 - 【掌控全局】最终的输出
 考虑了原始输入的整个sequence。【可近可远】并且,通过对
考虑了原始输入的整个sequence。【可近可远】并且,通过对 的调节,self-attention最终的输出可以是看了最近的输入x,也可以是看了远处的输入x。
的调节,self-attention最终的输出可以是看了最近的输入x,也可以是看了远处的输入x。
e.g.机器翻译中,输入单词的两两之间都构成Attention,线条越粗,Attention weight越大。Attention联系的远近,可通过Multi-Head Attention中不同组的q,k,v来实现。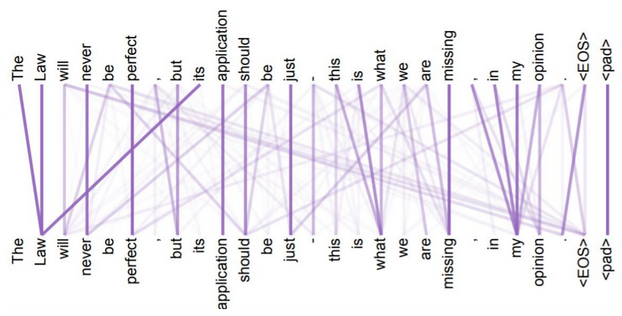
并行计算
Self-Attention层从输入到输出,是一堆可以并行的矩阵乘法,用GPU可以加速。
(注意:权重的共享!)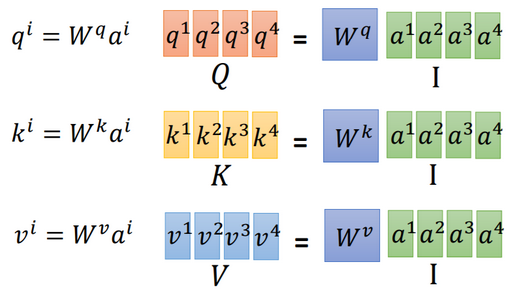

Multi-head Self-attention
多个head,就是对输入做多次变换(transform)。不同的head(即一组q,k,v),关注点不一样。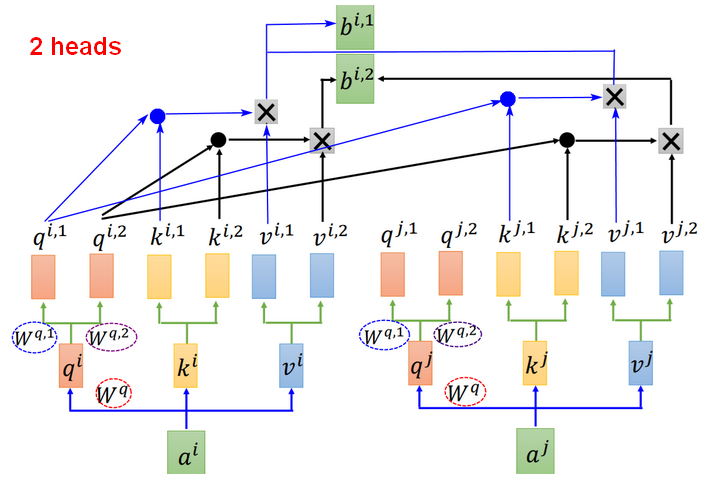
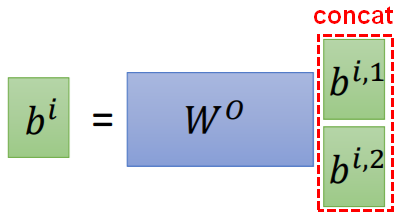
位置编码Position Encoding
Self-attention中因为输出是考虑了输入的整体sequence,输入sequence的顺序并不影响输出,此时Self-attention没有考虑位置信息,这是有问题的。例如:机器翻译中,必须考虑语序。
【思路】在输入中加入位置信息。
每个输入的位置都有一个独一无二的位置向量  (不需要从数据中学习),使用
(不需要从数据中学习),使用  表示带位置信息的输入。
表示带位置信息的输入。
【问题】为什么位置编码是和输入相加,而不是相乘?
假设用一个向量(one-hot编码)来表示每个输入的位置信息,该向量的第 i 维表示第 i 个输入。拼接到输入上,则,矩阵乘法经过拆分,可表示成加法的形式,即 。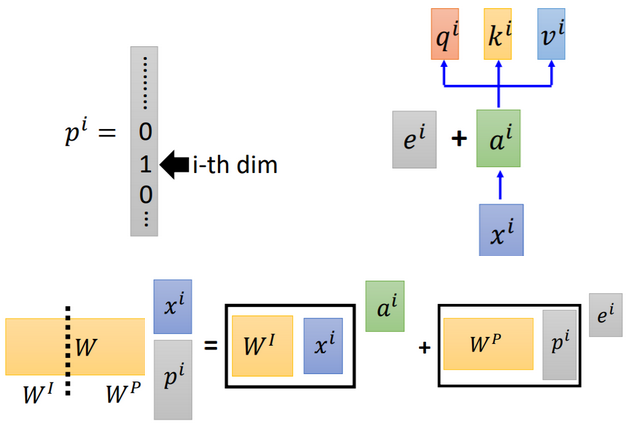
1.3 Transformer架构
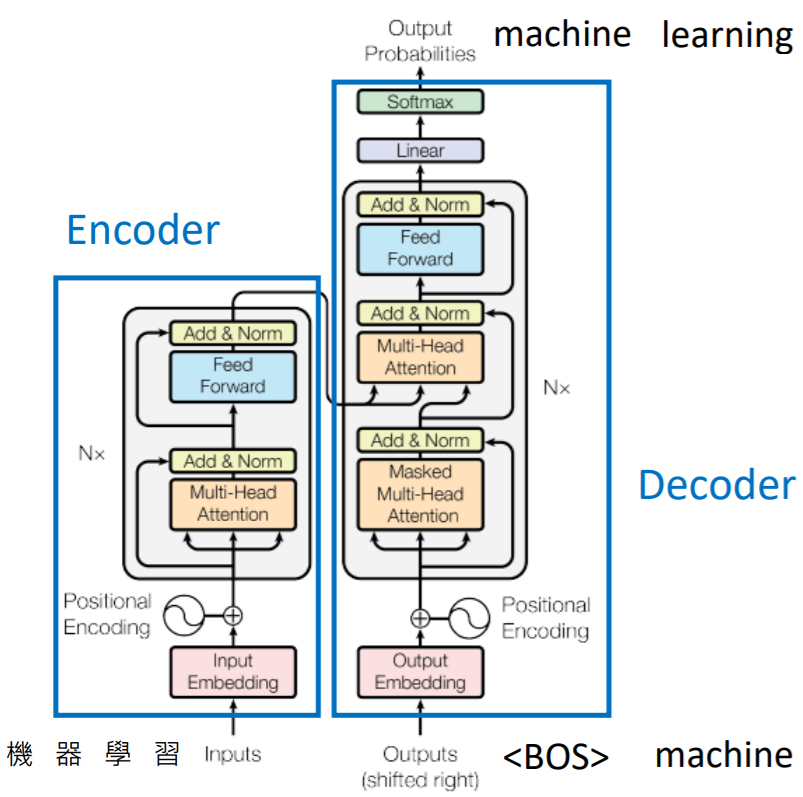
Nx:表示对应的block重复N次。
Multi-Head Attention:表示Self-Attention层。
Add:表示将其前面网络层(例如Multi-Head Attention)的输入和输出相加。
Norm:表示将Add的结果做Layer Normalization(单独对batch中的每个样本做该样本所有维度上的归一化),LN适用于RNN网络。
来源: 1.李宏毅《机器学习》2019:https://www.bilibili.com/video/BV1Gb411n7dE?p=60

若有收获,就点个赞吧
0 人点赞
