BERT要解决的问题是,输入一些Character(e.g.英文单词、一个汉字),输出字符的Embedding。在BERT之前,one-hot编码、word Embddding也是用来做这件事,即提取特征,将Word转为向量。
对于文本,期望转成的向量,可以体现Word的语义以及Word之间的关联。
【问题1】一词(word type)多义(word token)的情况,如何更好的提取特征?
1.ELMO
ELMO(Embeddings from Language Model)是一个基于RNN的语言模型。
【输入】单词Character
【输出】预测单词的下一个词。
1.1Contextualized Word Embedding
【RNN隐藏层】完成输入输出的训练后,RNN隐藏层就是每个输入的单词对应的Embedding向量;这个Embedding的产生考虑了前文,所以即便是同一个词,在不同的文本中,也会产生不同的Embedding。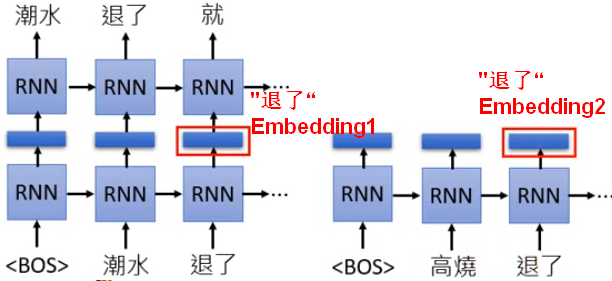
1.2ELMO网络结构
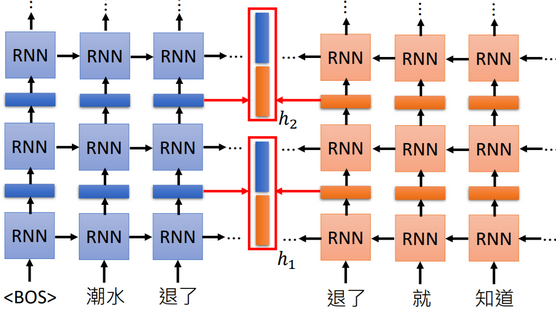
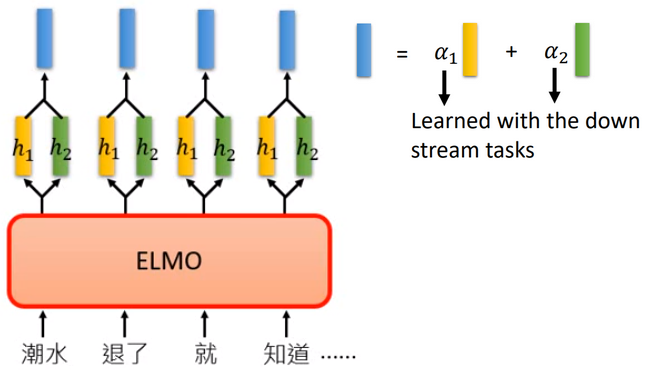
如果考虑上下文,就通过双向RNN共同生成Embedding(拼接起来),这样不同的上下文中,同样的词也会有不同的Embedding;多层双向RNN就生成了多个Embeddings(权重加和,生成最终的Embedding)。
e.g.“潮水 退了 就 知道 谁 没穿 裤子。”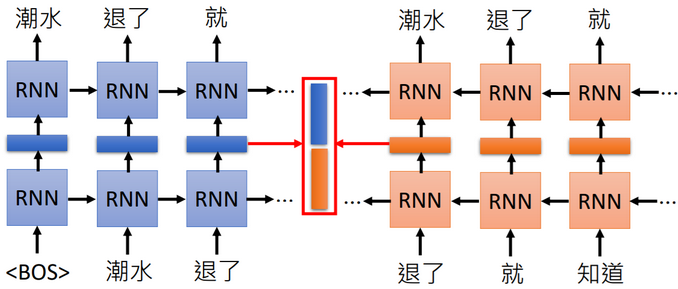
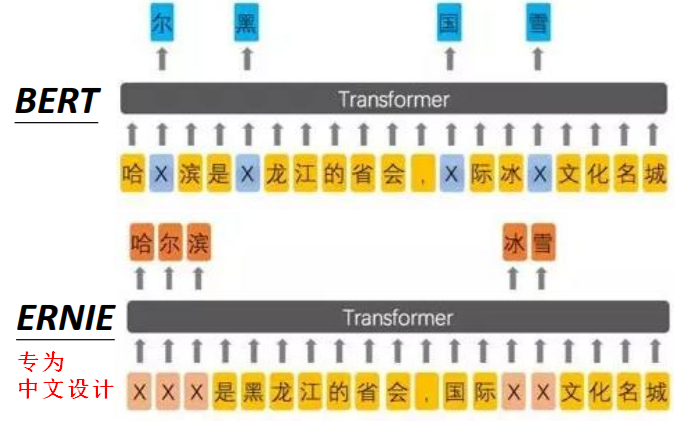
2.BERT
BERT(Bidirectional Encoder Representions from Transformers),BERT的网络结构就是Transformer的Encoder部分。
因为Transformer网络的任务是输入一个句子产生一个句子(Seq2seq),训练时需要给出真实的标注作为输出(e.g.机器翻译的训练需要给出答案),而BERT只是Encoder部分,训练时不需要给出标注,只需要学习一大堆文本。
【输入】单词Character(one-hot编码)。
【输出】单词对应的Embedding。
【问题2】如何训练,产生单词的Embedding?
以下两种训练方式可以同时使用。
2.1训练方式一:预测Masked Word
掩盖(Mask)住原始输入内容中的部分单词,通过输出后接线性分类器进行预测。
线性分类器是一个弱模型,BERT就充当了强模型,只有BERT部分提取出好的特征(更好更有用的表示),才能在分类时更准确。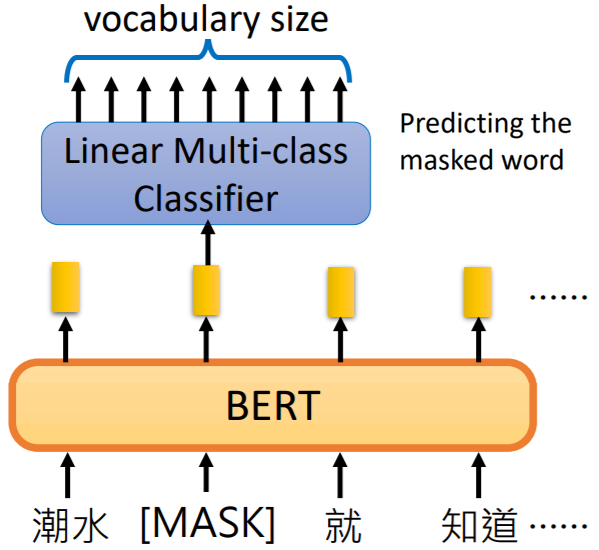
2.2训练方式二:预测句子
预测两个句子是不是可以被放在一起,放在一起后可以表达一个合理的意思。
【问题3】为什么CLS要放在网络的开始?
BERT是Transformer中Encoder的部分,内部使用了Self-Attention结构,而Self-Attention可以兼顾到整个输入(远处近处都可以兼顾到),所有CLS放在开头并没有影响。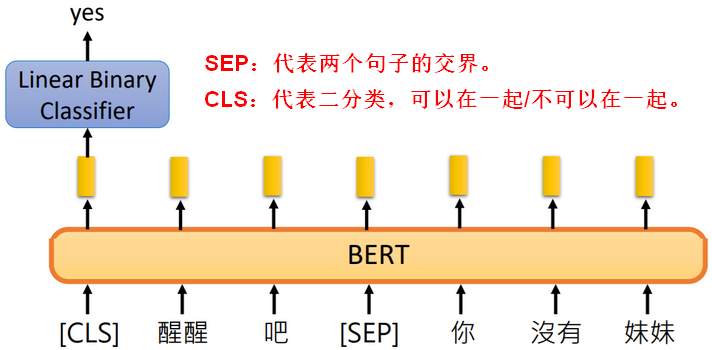
2.3BERT的应用
2.3.1文本分类
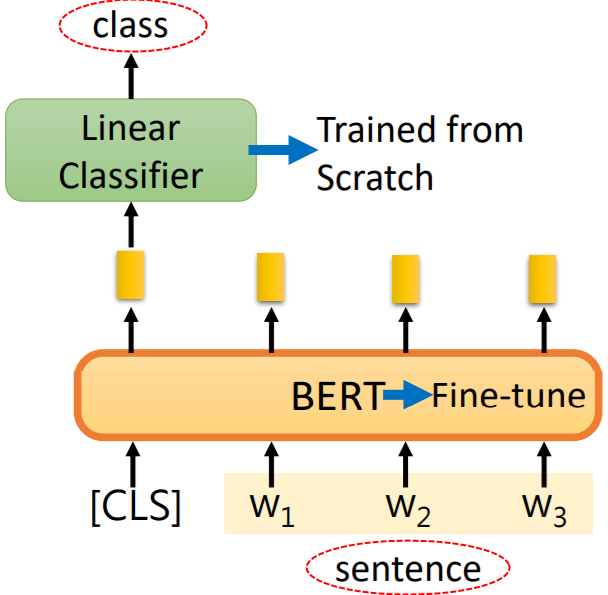
2.3.2词分类
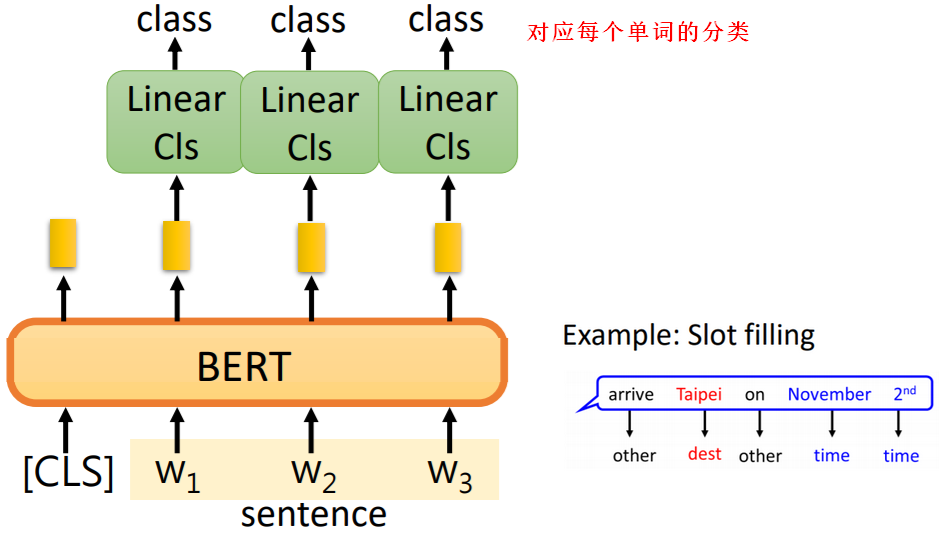
2.3.3语言推理(Inference)
【输入】e.g.句子1:前提 + 句子2:结论
【输出】两个句子搭配在一起,是否成立。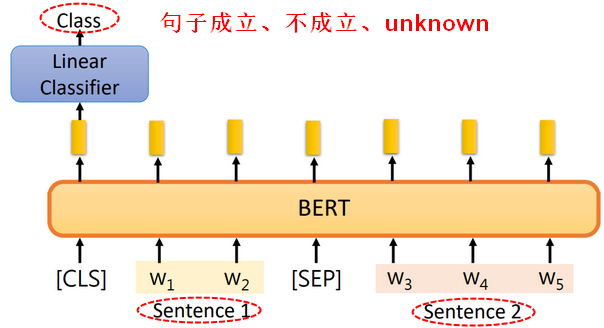
2.3.4问与答
机器读一篇文章,然后回答问题,假设问题的答案都可以从原文中找出。
【输入】问题和文章的单词。
【输出】每个单词对应的Embedding。
在训练过程中,加入两个向量一起学习,一个用于预测答案开始的单词索引s,一个用于预测答案结束的单词索引e。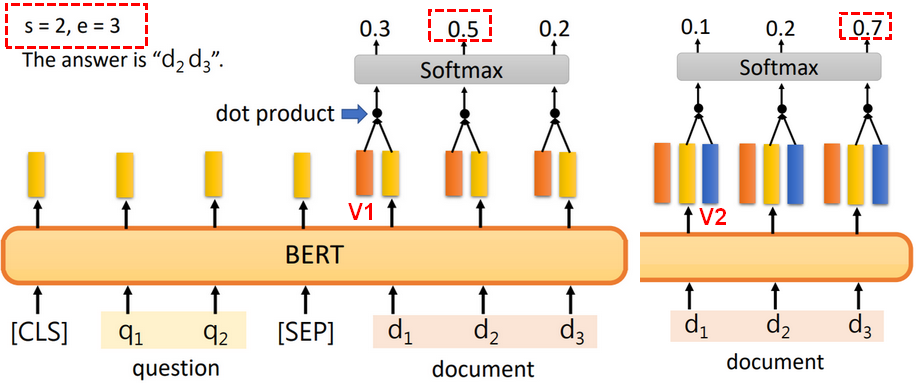
3.GPT
GPT(Generative Pre-training)网络内部使用了Self-Attention结构: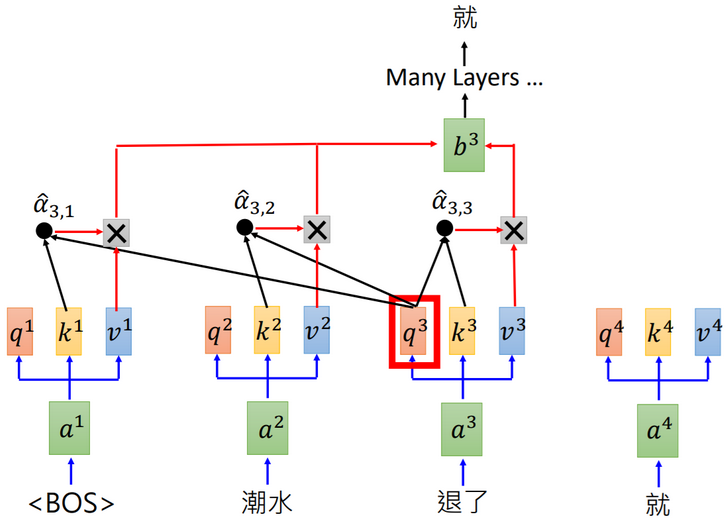
3.1模型参数对比
| 模型 | 参数大小 |
|---|---|
| ELMO | 94M |
| BERT | 340M |
| GPT-2 | 1542M |
来源: 1.台大李宏毅《机器学习》2019

若有收获,就点个赞吧
0 人点赞
