1.什么是机器学习?
1.1 机器学习的定义
机器学习的诞生来源于两个领域:
人工智能(artificial intelligence)。
ML是AI四象限中的一个(think optimal)。
人工智能主要包括机器学习和深度学习。深度学习是机器学习的一个分支。
数据科学(data science)。
机器学习(Machine Learning):根据已有的经验(数据),找(算法)出规律(模型),并用于预测未知的数据,重视模型的泛化generalization能力。即对于一个任务T,根据经验E,有一个表现的衡量P,随着E的增加,P在T上表现更好。
机器学习的技术定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
1.2 学习机器学习学科的忠告
- 机器学习可以理解为计算应用统计学;ML是关于归纳induction(特殊/具体到一般/抽象),而不是演绎deduction(一般/抽象到特殊/具体)或者 溯因abduction。
- 学习机器学习这门学科,主要是学习思想,公式和算法是对思想进行量化的工具。
- 数据(指做了数据预处理和特征工程的数据)决定了模型的上限,而算法只是逼近这个上限。
- 机器学习和深度学习的核心问题在于有意义的变换数据,即学习输入数据的有用表示(representation)。所谓“表示”,就是用不同的方式来查看数据(数据编码或表证数据)。所谓“学习”,就是寻找更好数据表示的自动搜索过程。
- 机器学习(尤其是深度学习)呈现出相对较少的数学理论,是以工程为导向,是一门需要上手实践的学科。
- 想要控制一件事物,首先需要能够观察它。对于机器学习来说,观察点就是损失函数(loss function)。
- 面对一个尚没有已知解决方案的新问题,可先尝试一种基于常识的基准(baseline)方法,它可以作为合理性检查,而更高级的机器学习模型需要打败这个基准才能表现其有效性。
1.3机器学习的历史
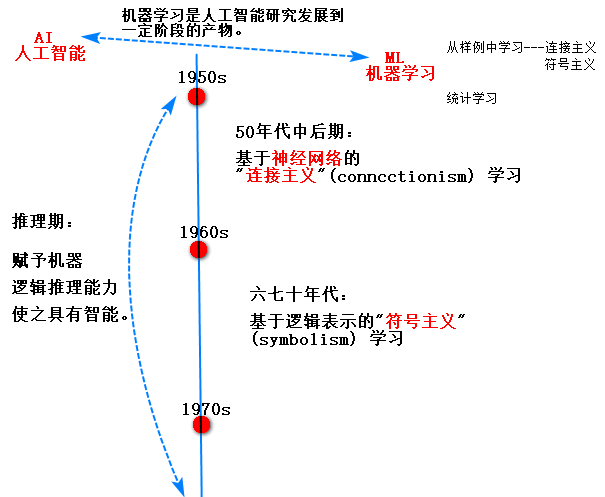
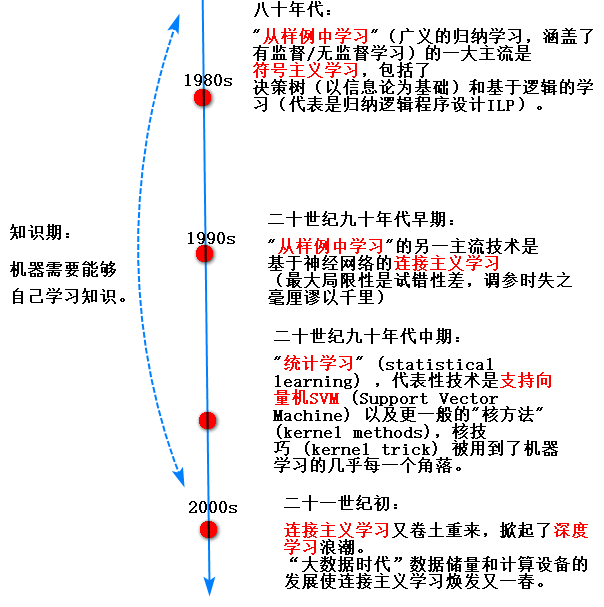
符号主义人工智能:硬编码的规则+数据——>程序设计——->给出答案
机器学习:输入数据+答案——->机器学习——->给出规律规则
1.4 归纳、演绎、溯因
归纳、演绎、溯因是推理的三种常见形式,而机器学习中任务是关于归纳的。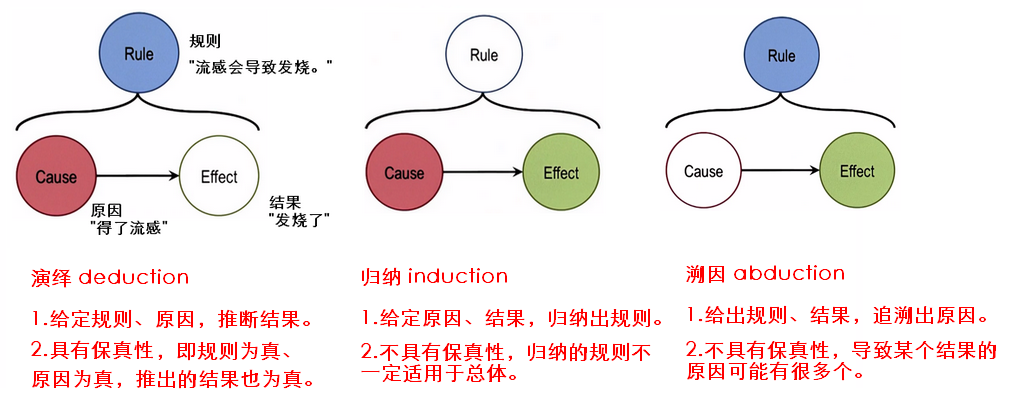
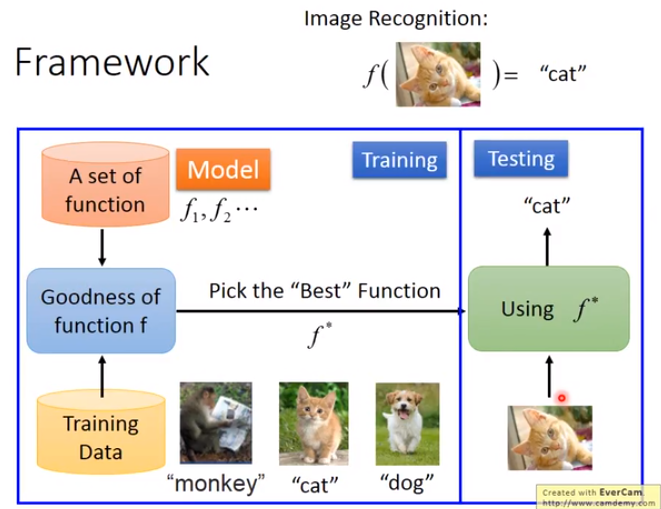
1.5 抽象理解
【模型假设】确定Model(funtion set)或者 假设空间(hypothesis space)>>>
【模型评估】确定评估Model的方法:衡量一种参数的好坏 L(w,b) >>>
【最佳模型】选出最佳模型:梯度下降
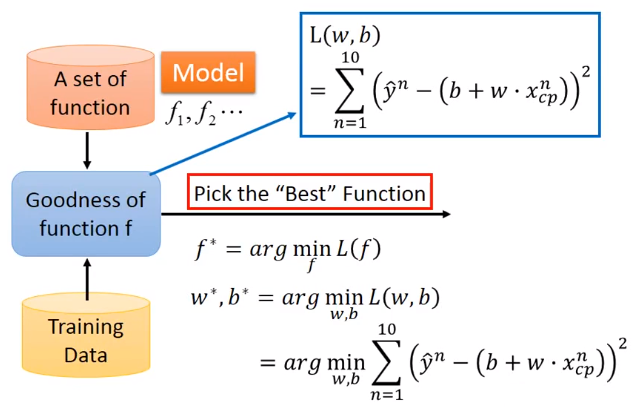
2. 机器学习中的三要素
2.1 统计学习特点
- 假设同类数据具有一定规律的统计规律性。
例如:监督学习中,假设输入变量X与输出变量Y符合联合概率分布,分布函数为P(X,Y).
- 数据(即变量)驱动,基于数据构建概率统计模型,用于预测与分析。
例如:监督学习的模型是概率模型或非概率模型,概率模型由条件概率分布函数 P(Y|X) 表示,非
概率模型由决策函数(decision function)Y=f(X) 表示。
-
2.2 统计学习方法的三要素
模型Model
确定所有可能的模型的假设空间,包括概率模型、非概率模型。
策略Strategy
确定模型选择的准则(损失函数、风险函数),以便用来评估模型。
算法Algorithm
根据策略,利用最优化算法求解出参数向量,寻找全局最优解,确定最优模型。最优化算法用于求
解最优化问题,这个问题可能有显式的解析解,多数情况需要用数值计算的方法求解。
3. 机器学习中的任务分类
(1)监督(supervise)学习任务:
- 定义:给定的数据中有明确的预测数据。获取打标签的数据集,获取信息,从而标记没有标签的数据。监督学习是关于函数逼近approximation。
回归(拟合):预测的数据是连续值的任务。损失函数是MSE。
算法:knn,线性回归,Lasso,Ridge,生存回归,保序回归,随机森林,
GBDT,xgboost,神经网络等
回归分为:标量回归(目标是连续标量值)、向量回归(目标是一组连续值)。分类(找分界):预测的数据是离散值的任务。大部分损失函数是交叉熵(cross-entropy).
算法:knn,逻辑回归,softmax,svm,朴素贝叶斯,决策树,随机森林,
GBDT,xgboost,神经网络等
分类包括:二分类、多分类、单标签分类、多标签分类(每个样本可以分配多个标签)。
(2)非监督(unsupervise)学习任务:定义:给定的数据中没有明确的预测数据。通过查看输入本身之间的关系推导出某些结构。非监督学习是关于描述description。如果非监督学习对类别有正确的描述,它可以有助于监督学习更好的进行函数逼近。
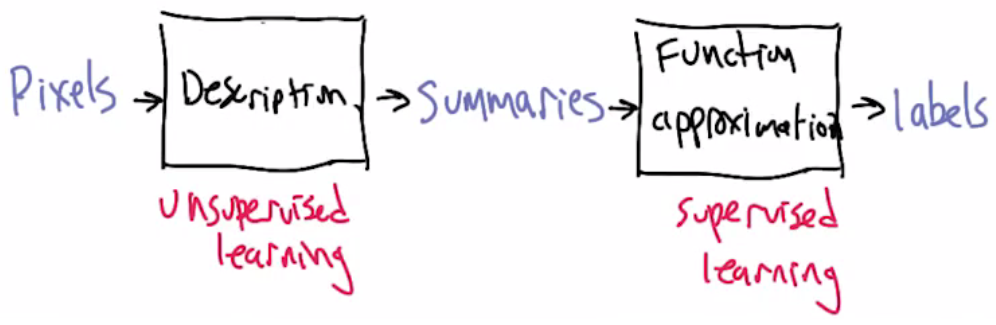
聚类:将原始的数据分为多个组。
算法:kmeans,kmeans++,canopy,dbscan,谱聚类,GMM等
降维:把原始数据的特征数减少。
算法:PCA,LDA,SVD
(3)半监督学习任务:定义:给定的数据中有部分有明确的预测数据,有部分没有。
(4)增强(reinforce)学习
- 定义:通过延迟奖赏(delayed reward)进行学习。举例:下五子棋,监督学习会告诉你走的每一步是好是坏,增强学习不会告诉你,直到最终判断是赢是输。
阿里巴巴算法专家华校专对机器学习的分类如下:
台湾大学李宏毅定义的分类如下: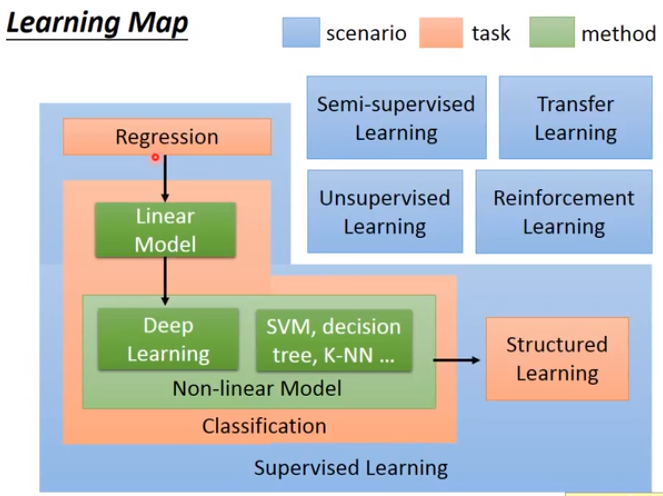
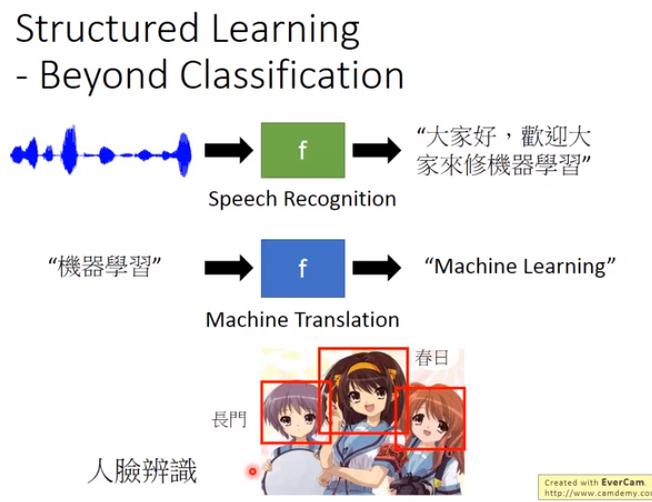
4. 机器学习项目的流程
4.1 整体流程
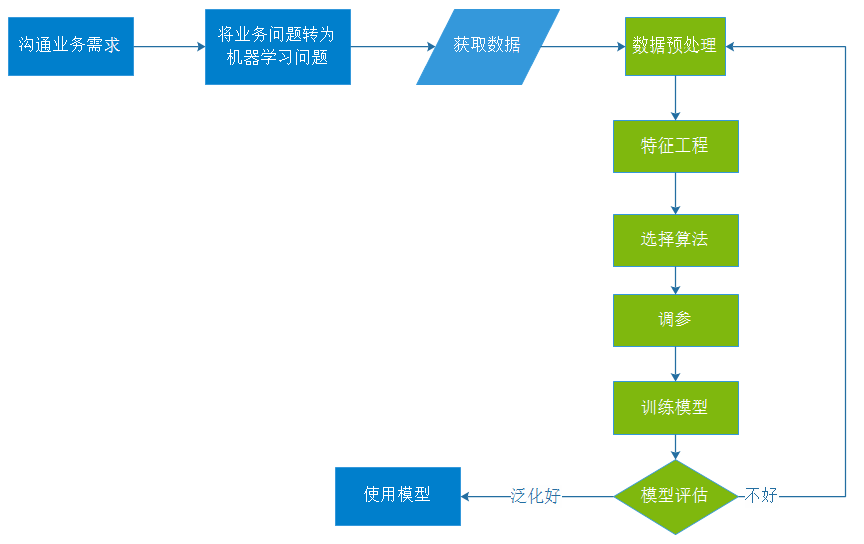 实际项目中有2/3的时间在处理数据。
实际项目中有2/3的时间在处理数据。
特征工程:提取特征;在已有特征的基础上,增加特征,或减少特征。
要想使模型有更好的泛化能力,总体上,可以从数据和算法两个角度去改变:
4.2 训练/学习流程
对于有监督的学习,学习流程如下:
- 随机给出一个参数w,计算模型输出;
- 计算模型输出和真实值之间的差异,得到损失函数;
- (通过求导)不停的调整参数w,让损失函数变小。
5. 机器学习中的专业术语
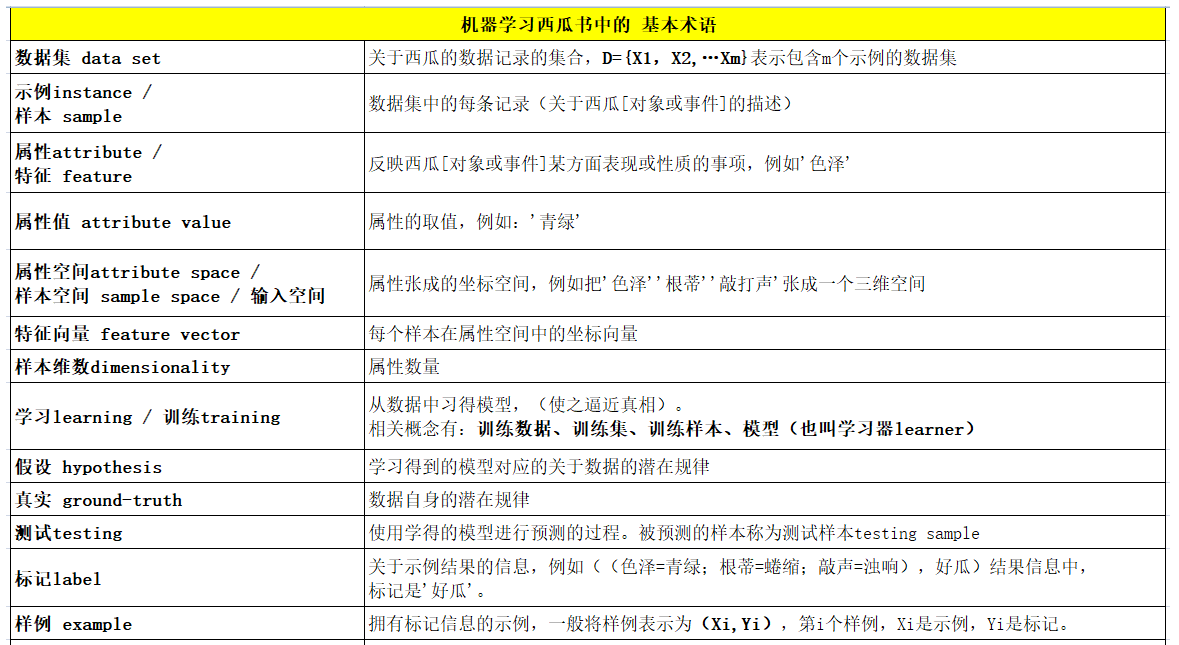
- 样本sample:样本就是一条记录,或者一条数据。
- 样本集 sample set:多个样本的集合。又叫数据集。
- 训练集training set:用于训练模型的数据集。通常是原始数据集的2/3~3/4
- 测试集 test set:用于评估模型的数据集。
- 输入数据:就是样本中除去预测的值那一列。用大写X表示
- 输出数据:样本中的预测值那一列。用小写y表示。
- 特征:数据的属性在机器学习中被称为特征。
- 特征向量:多个特征组合在一起被称为特征向量。
- 维度:指特征的数量。
- 二分类:预测的结果只有2个,这类问题被称为二分类问题。在二分类的问题中,关注的类别被称为正类(positive),不关注的问题被称为负类(negative)
- 拟合:指找出模型去接近原始数据规律的过程
- 过拟合(over fiting):过分的学习数据的原始/一般特征,将数据的特有特征也学习到了。
- 欠拟合:数据的一般特征都没有学习好。
- 泛化:模型应用于新样本的能力。
- 预测值:新样本根据模型预测得到的值。用
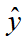 表示,y_hat。
表示,y_hat。 交叉验证:将原始数据分成n份,称为n折交叉验证;每次取出1份作为测试集,其他用来训练,最终生成n份模型,n次模型评估,取一个最佳的模型。除了交叉验证,还有留出法(数据集中70%训练,留出30%测试)。
输入空间input space/输出空间output space:(监督学习中)输入与输出所有可能取值的集合。
- 特征空间feature space:示例通常由特征向量表示,所有特征向量存在的空间就是特征空间。
- 假设空间hypothesis space:模型属于从输入空间到输出空间的映射集合,这个集合就是假设空间。
- 参数空间parameter space:假设空间通常是一个由参数向量决定的函数族/集合,参数向量的取值范围称为参数空间。
- 回归regression:输入变量与输出变量均为连续变量的预测问题称为回归问题。
- 分类classification:输出变量为有限个离散变量的预测问题称为分类问题。

参考:
1.《机器学习》周志华
2.《机器学习》李宏毅
3.《统计学习方法》李航

若有收获,就点个赞吧
0 人点赞
