1.问题引入
1.1 文章主题分类
【问题】如何对一篇文章进行主题分类?
假设 表示某篇文章,
表示某篇文章, 表示某个主题,
表示某个主题,  表示某个词。
表示某个词。
首先进行数据的向量化,将每篇文章通过词袋模型,转成一个个向量。
方法一:K-Means对文章向量进行聚类。但问题是,两篇文章的词不同,类别却可能相同,或者一篇文章可能有多个主题。所以使用K-Means聚类并不是好的选择。
方法二:LDA迭代计算。分析如下:
1.2 隐主题
如果知道某篇文章的主题的概率分布,就能取出概率的Top N作为该文章主题类型;而各个主题有各自对应的词的分布,因此可以根据文章和词,提取对应的主题及概率。
提取的这个主题仅表示概率分布意义上分类的主题,并不对应到实际中的主题,这叫隐主题。
一篇文章可以有多个(隐)主题,不同主题的词的差异性很大。
- 一个词在不同的文章中所对应的(隐)主题可以不一样。
- 具体到某一个(隐)主题时,一个词只能由一个主题产生。
由于主题是未知的,可以直接分析的是文章和文章中出现的词。可以通过词对应的主题分布,以及文章中词的分布,来推导文章的主题分布。
2.LDA的原理
2.1 前提条件
- 词袋模型:由于文章太长,或者性能原因,词袋模型中放弃了词的顺序信息。
one-hot编码:如果一个字典中有N个词,那么一篇文章就可以表示为一个N维向量,文章中出现了哪个词,就将N维向量中该词索引位置处设置为1。
2.2 LDA迭代过程
对每篇文章中的每一个词随机一个主题。
计算主题中词出现的概率为: ,
,
这是用频率替代概率,其中, 为先验概率,防止计算的概率为0(因为样本有限,实际可能并不为0),
为先验概率,防止计算的概率为0(因为样本有限,实际可能并不为0), 为所有文章中词(去重)的总数。
为所有文章中词(去重)的总数。
计算每篇文章所对应的主题概率分布为: ,其中
,其中 为文章中所有的主题个数。
为文章中所有的主题个数。
- 知道了文章-主题
 (某文章中某个主题出现的概率)和主题-词
(某文章中某个主题出现的概率)和主题-词  (某主题中某个词出现的概率),可求词-主题(某个词对应的主题分布)
(某主题中某个词出现的概率),可求词-主题(某个词对应的主题分布) 。
。
计算某个主题的某篇文章中出现某个词的概率为:
其中 是根据业务场景做的简化,即只通过主题就可以判断词的分布。
是根据业务场景做的简化,即只通过主题就可以判断词的分布。
词对应的主题分布:
因为分母 和主题无关,所以
和主题无关,所以 ,成正比关系。
,成正比关系。
- 知道了词对应的主题分布,对词按概率进行随机采样,得到每个词对应的主题,重复第二第三步骤,直到文章-主题、主题-词的分布趋于稳定。
例如: ,归一化除以1.8之后得到
,归一化除以1.8之后得到 ,对词
,对词 按归一化后的概率进行随机采样。
按归一化后的概率进行随机采样。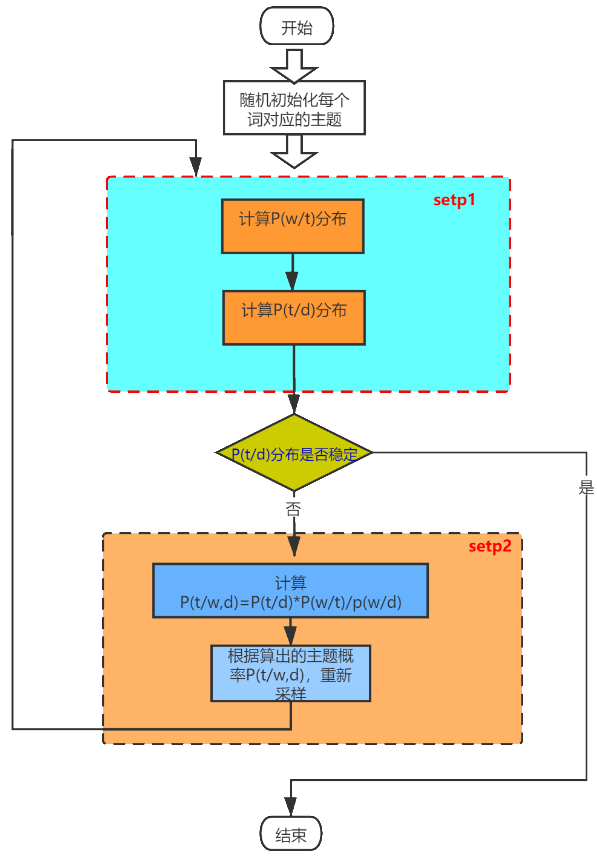
3.LDA的应用
3.1计算文章的专业性(文章-主题)
越专业的文章,它的主题越明确,而不是主题分布比较分散。对每篇文章,可以利用文章的主题分布,计算信息熵(entropy),信息熵越小,文章的专业性越强。 ,其中,为文章的主题。
,其中,为文章的主题。
3.2计算文章之间的相似度(文章-主题)
求出了每篇文章的主题分布,可以将主题分布概率表示为向量的形式,即: 两个向量应该具有同样的维度/长度。
两个向量应该具有同样的维度/长度。
计算向量内积,可求得相似度,可用于给用户推荐相似的文章。
3.3文章主题分类(文章-主题)
求出了文章的主题分类,可用于用户行为分析、推荐系统冷启动时的推荐。
3.4计算每个词的专业性(词-主题)
专业性越强的词,它的主题越明确。对每个词,可以利用词的主题分布,计算信息熵,信息熵越小,词的专业性越强。 ,其中,为词的主题。
,其中,为词的主题。

若有收获,就点个赞吧
0 人点赞
