1.生成句子
1.1句子生成流程(文本)
句子(Sequence)是由单词、字符、n-gram组成的,要生成句子,就是要生成单词、字符或n-gram,最后组成句子。
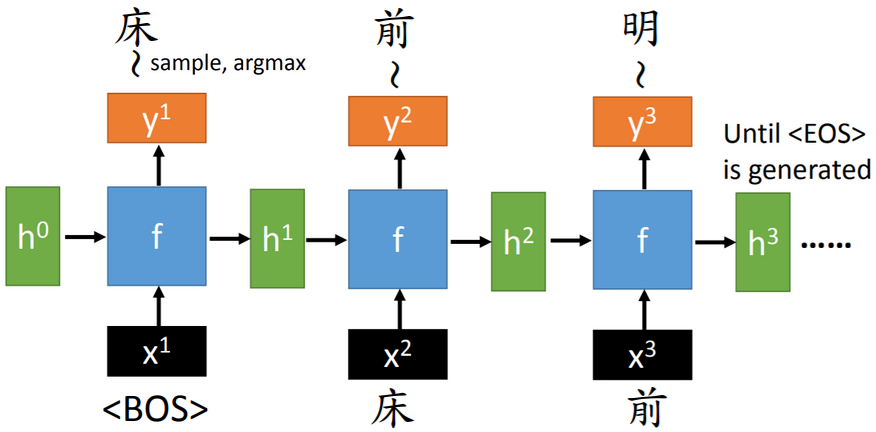
【思路】使用RNN,每一时刻,生成一个单词或字符。可以将RNN看成一个生成器(generator)。
【training输入】单词、字符的特征编码(e.g.one-hot编码)。BOS(begin of sequence)是一个标识开始的符号(token)。
【training输出】单词、字符。输出会有一个单词的可能分布,从中选取一个可能性最大的(argmax),或者采样(sample)输出。
【training损失】输出是一个二分类,即期望输出的单词与其他单词,计算交叉熵。

1.2句子生成流程(图片)
图片是由像素(pixel)组成的,要生成图片,就是要生成一个个的像素。
【思路】使用RNN(PixelRNN),每一时刻,生成一个像素。考虑到相邻的像素具有相似性的可能更大,所以生成顺序需要调整。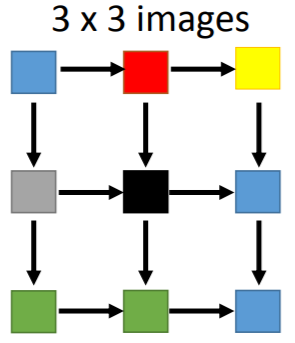
2.有条件的生成句子
给定
如果给定一个条件(condition),按条件进行生成,则生成过程就不再随机。
2.1条件生成(图片)
e.g.生成图片说明(Caption):
【条件】需要被说明的图片(在整张图片上提取的特征向量)。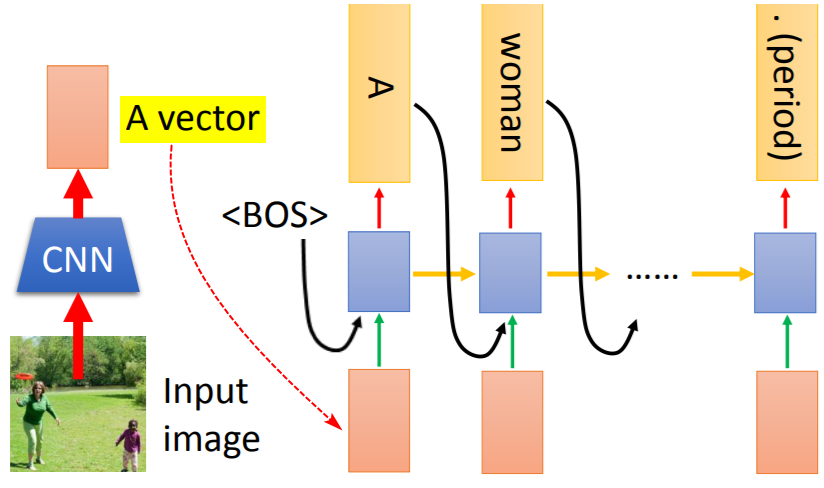
2.2条件生成(文本):Seq2seq
e.g.机器翻译、聊天机器人
【条件】输入的整个句子(在整个句子上提取的特征向量,即只保留最后一个输出)。
【问题】使用Encoder的特征向量,由Decoder/Generator生成一个句子时(例如:机器翻译),每个时刻的生成结果,并不需要整个句子作为输入,特别是当原始输入的句子很长时,Decoder时,只需要注意(attention)到部分内容(例如:要输出‘machine’只需要关注“机器”。)
【注意】Decoder中的输入包括三部分:Encoder中输出的向量、Decoder中上一时刻的结果输出、Decoder中上一时刻的隐藏层输出。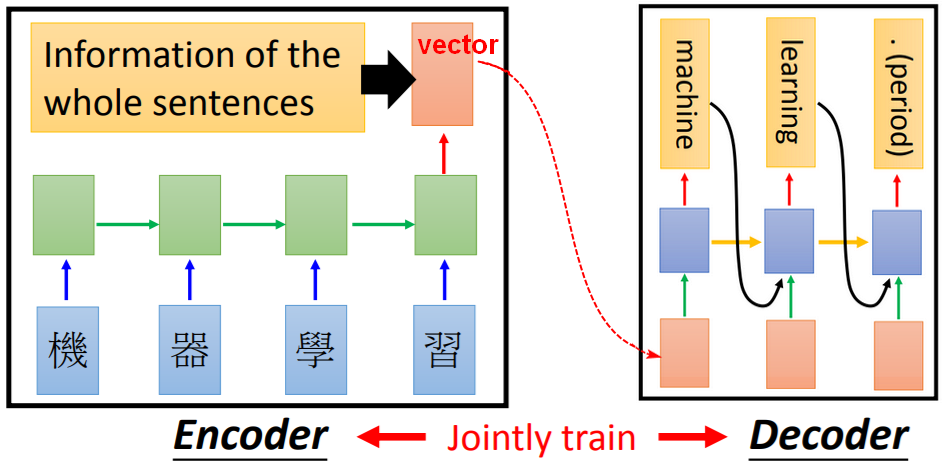
2.3带注意力机制的条件生成(文本)
【思路】
基于注意力(Attention)的模型:通过Encoder生成条件(Condition)时,每个时刻生成的条件是动态(dynamic)变化的,以提醒Decoder在每一个时刻,把注意力(Attention)放在不同的关注点上。
【问题】如何表示注意力的变化?
将Encoder的输出附上权重(注意力权重:Attention weights),每次只关注权重大的组成部分(component)。
注意力权重
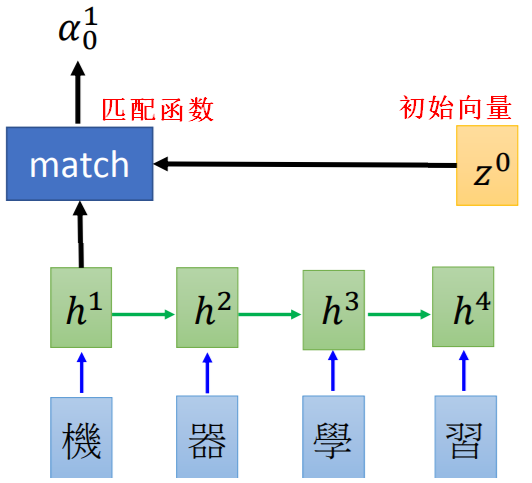
【Encoder部分】
给定一个初始向量 ,
, 代表RNN网络输出,计算和Encoder中第一个输出的匹配分数
代表RNN网络输出,计算和Encoder中第一个输出的匹配分数 。
。 像是一把钥匙/关键词(key),用来找出哪些内容是需要被注意的,是需要被学习出来。
像是一把钥匙/关键词(key),用来找出哪些内容是需要被注意的,是需要被学习出来。
匹配(match)函数的设计方式:
- 使用余弦相似度。
- 使用神经网络,输出标量分数:

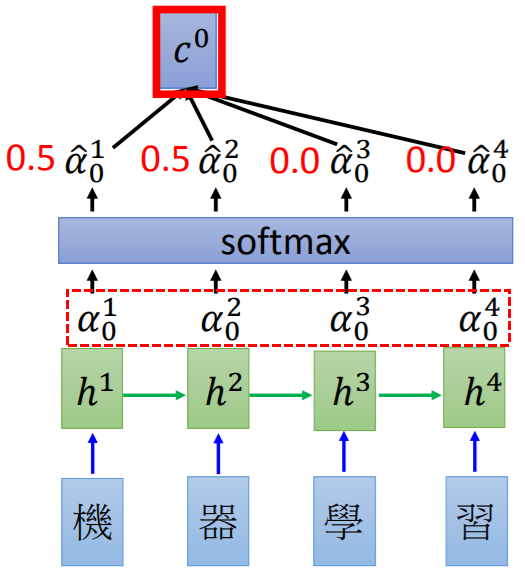
同样,依次计算出与 的匹配分数
的匹配分数 ,匹配分数就是注意力权重(Attention Weight),代表注意力的大小。
,匹配分数就是注意力权重(Attention Weight),代表注意力的大小。
softmax层不是必须要有的,只是为了归一化:
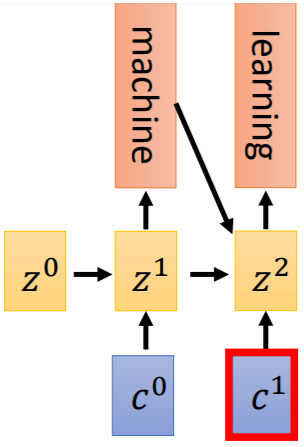
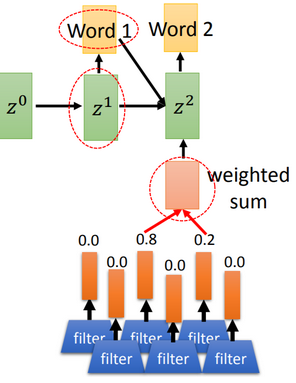
【Decoder部分】
Encoder的输出 作为Decoder的输入,Decoder RNN输出生成的单词和下一把钥匙
作为Decoder的输入,Decoder RNN输出生成的单词和下一把钥匙 ,用于找出下一时刻的注意力权重并输出
,用于找出下一时刻的注意力权重并输出 ,直到遇到句子结束的标识(EOS)。
,直到遇到句子结束的标识(EOS)。
钥匙 的设计比较灵活,可以是Decoder RNN的一个输出,也可以是Encoder的输出变换而来。
的设计比较灵活,可以是Decoder RNN的一个输出,也可以是Encoder的输出变换而来。
组成部分Component
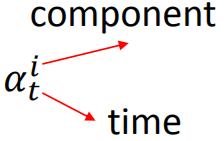 注意力权重,就是在原始输入的各个组成部分(Component)上的权重,每个时刻的组成部分都是一样的。
注意力权重,就是在原始输入的各个组成部分(Component)上的权重,每个时刻的组成部分都是一样的。
组成部分代表了从原始输入中提取了多少组特征。
2.4带注意力机制的条件生成(图片)
将注意力模型用于图片说明(即看图说话),流程、loss计算,和生成文本时一样。
将一张图片划分为多个子区域(Region),这些子区域就是图片的组成部分,注意力将被分散到这些组成部分上。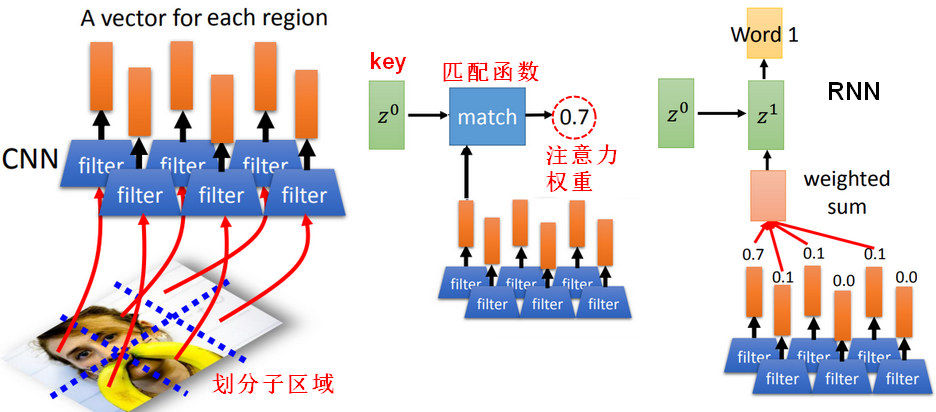
3.生成模型中的问题
3.1注意力问题(Bad Attention)
看图(视频中的每一帧)说话中,期望模型关注到原始输入的各个部分,否则不同的时刻可能关注点相同,生成了重复的描述文字。
【解决思路】:每个输入的部分都应该有大致相同的的注意力权重;在损失函数中限制不同部分在各个时刻的权重总和的大小(设定一个相同的上限),使之不相上下。
3.2曝光误差(Exposure bias)
曝光误差(Exposure Bias):是在RNN(递归神经网络)中的一种偏差,即 RNN 在训练(training) 时接受的标签是真实的值(ground truth )或者叫正确参考(reference);但测试 (testing) 时却接受自己前一个单元的输出(output)作为本单元的输入(input),这两个setting不一致会导致误差累积,即在测试的时候,如果前面时刻的输出已经是错的,这个错的输出作为下一单元的输入,会造成“一步错,步步错”。
【问题1】曝光误差的原因是什么?
Decoder中的输入包括三部分:Encoder中输出的向量(即条件Condition)、Decoder中上一时刻的结果输出、Decoder中上一时刻的隐藏层输出。
训练时样本数据不可能覆盖所有情况,有一些cases是测试时模型没有看过的,测试时的输入,并不像训练时那样有一个Ground Truth或Reference,当上一时刻的输出出现误差时,就导致之后的输出都有误差。
例如:训练时正确输出是“ABB”,测试时如果第一时刻输出“B”,整体结果可能变成“BAA”。
例如:机器翻译时,在给定条件下,原本期望翻译结果输出为“ABB”,假如只有两个单词,测试时的实际输出就有 种可能结果。
种可能结果。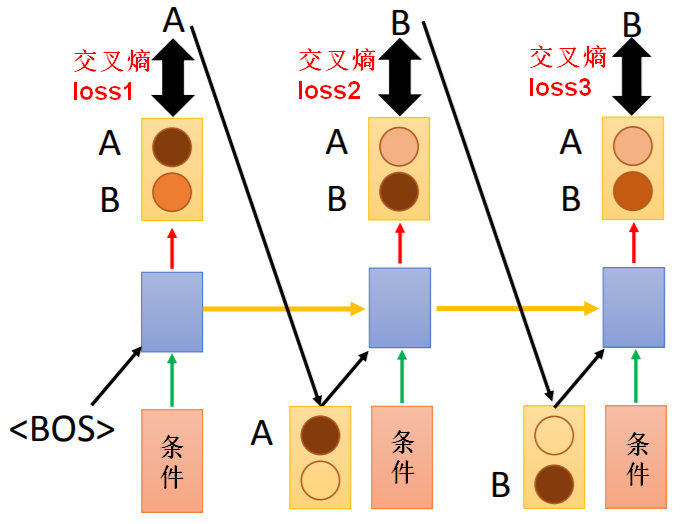
(整体损失是每一时刻交叉熵损失之和: )
)
【问题2】如何解决曝光误差的问题?
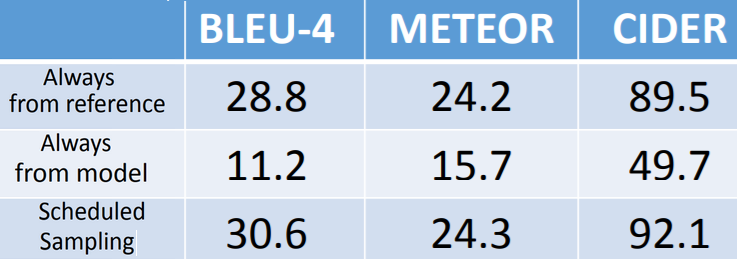
思路:改变Decoder训练时的流程,在训练时,让模型多学一些样本(Scheduled Sampling);在测试时,让模型在几种可能性较大的输出中做选择(Beam Search);或者减少Decoder的输入,不再把上一时刻的最终输出作为当前时刻的输入。
Scheduled Sampling
Scheduled Sampling用于训练阶段。
训练阶段,每一时刻最终结果的输出,用于下一时刻的输入时,除了参考ground truth,还允许模型做选择(sampling),这样等同于在训练时看到了更多的可能路径。
为了不把模型训练坏,训练时,先以reference作为下一时刻的输入,保证将模型训练好(在训练数据上收敛更好);再以model随机的选择采样作为下一时刻的输入。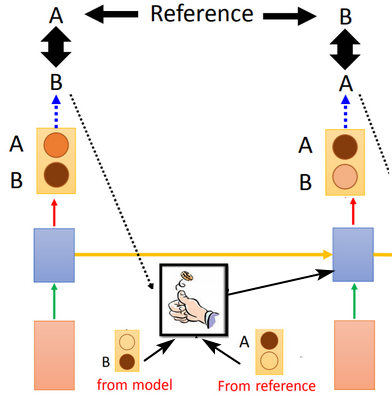
Beam Search
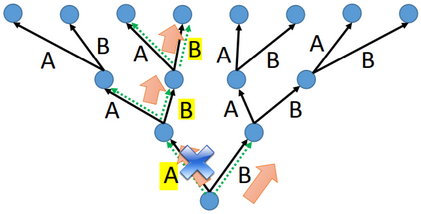
由于曝光误差问题,(假设只有AB两种情况,一共三个时间步)测试时的可能输出一共有种。
暴力穷举:穷举所有可能,然后选择整体上可能性最大的(全局最优),但计算量大,是不明智的。
贪心搜索(Greedy Search):贪心算法每一步选择中都采取在当前状态下最好或最优的选择,通过这种局部最优策略期望产生全局最优解。虽然不能保证最终的结果一定是全局最优的,但是相对穷举搜索,搜索效率大大提升。
Beam Search:Beam Search用于测试阶段。测试阶段,当束宽(beam size)为K时,每个时间步长都保留K个可能性最大的输出,下一个时间步长,在前K个可能输出的基础上,再从所有可能输出中保留K个最大可能输出。Beam Search的搜索空间比贪心搜索大,是对贪心搜索的改进,当beam size=1时,就成了贪心搜索。Beam Search并不能保证全局最优。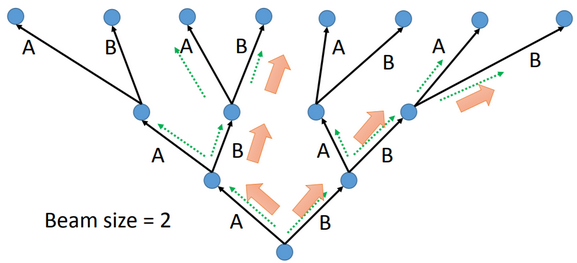
来源: 1.李宏毅《机器学习》2017秋季:https://www.youtube.com/watch?v=T8mGfIy9dWM&feature=youtu.be

若有收获,就点个赞吧
0 人点赞
