【问题引入】输入一个词,如何预测这个词后面最可能出现哪些词?
1.语言模型
语言模型:判断一句话是否合理的概率,即词按一定顺序组合在一起的概率。
语言模型(language model):标记(token)通常是单词或字符,给定前面的标记,能对下一个标记的概率进行建模的任何网络都叫做语言模型。语言模型能够捕捉到语言的潜在空间(latent space),即语言的统计结构。
1.1n-gram模型
文本可以拆分成单词、字符,n-gram是从句子中提取的N个连续单词或字符的集合(n-gram之间可以重叠),每个词出现的概率仅仅由它前面的n个词所决定。
例如:句子“我爱北京烤鸭”,从中提取的2-gram集合(即二元语法袋)为:
{“我”,“我爱”,“爱”,“爱北”,“北”,“北京”,“京”,“京烤”,“烤”,“烤鸭”,“鸭”}。
n元语法袋、词袋
n-gram的集合被称为n元语法袋(bag),这只是一个集合,而不是序列,即集合中的标记没有特定顺序,舍弃了句子的总体结构。这种分词方法叫做词袋(bag-of-words)。
n-gram的缺点
- n-gram模型舍弃了句子的总体结构,因此往往只用于轻量级的浅层的语言处理模型,而不是深度学习模型。
n-gram模型中单词出现的概率计算不准。当语料库小时,一些小概率情况没有出现,计算概率为0,但实际不为0(即小概率的情况被低估),而概率高的情况,容易被高估。
【解决】:一共有V个词,假设每个词出现c次(即用均匀分布的方式将语料库变大),在计算概率时加入先验概率。
句子出现概率的计算复杂度高。1-gram计算复杂度
 ,2-gram计算复杂度
,2-gram计算复杂度 。NLP领域,考虑到性能,一般最多做到2-gram。
。NLP领域,考虑到性能,一般最多做到2-gram。 例如:有4个单词w1,w2,w3,w4,1-gram的情况时,根据贝叶斯公式,有:

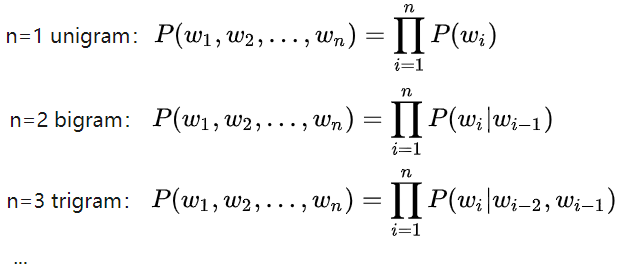
【解决】:将词通过one_hot编码,输入神经网络,输出为下一个要预测的词。1.2神经网络语言模型:Word2vec
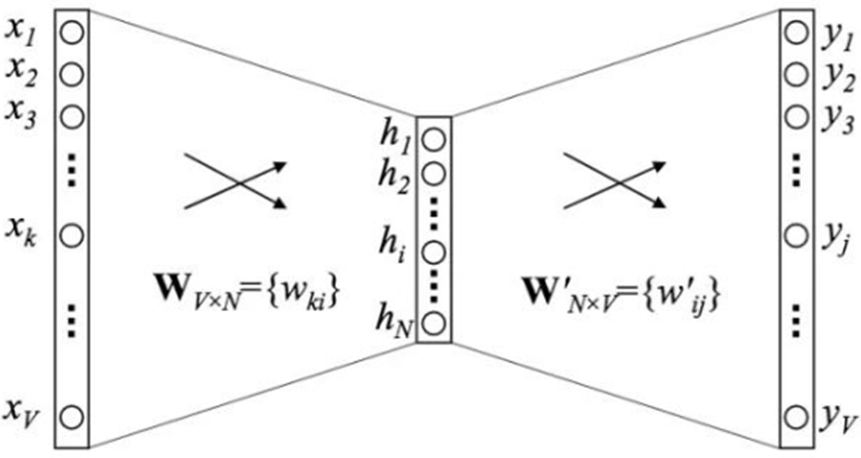
V代表词表中词的数量。Word2vec就像一个编码器(encoder),将词转为(稠密)向量。词向量:从稀疏到稠密
将词通过one_hot编码,输入NN,输出为下一个要预测的词;假设每个词one-hot编码之后的维度为V,输出为V维的词向量。
2-gram中,输入向量维数为 ,(在只有一个中间层时)参数总量为
,(在只有一个中间层时)参数总量为 ,计算复杂度由降到了。
,计算复杂度由降到了。
【问题1】对词进行one-hot编码,是一种稀疏编码,导致所有词向量之间的距离都是一样的,无语义表达;而且网络中的参数多,最后softmax输出的类别也多,计算量大。
【解决】用稠密向量代替one-hot编码之后得到的稀疏向量:将每个词的稀疏向量,从V维变为128维的稠密向量,输出仍然为V维向量,这样NN的参数为: (2-gram)。这样部分解决了稀疏向量的问题,而且也降低了参数量。
(2-gram)。这样部分解决了稀疏向量的问题,而且也降低了参数量。
词向量:按位相加
【问题2】神经网络中的参数量能否进一步降低?
【解决】2-gram中,将输入的两个128维的词向量按位相加,结果变成1个128维向量。输出仍然为V维向量,这样NN的参数为: ,而且不论n-gram中n为多少,NN的参数都是。
,而且不论n-gram中n为多少,NN的参数都是。
虽然减少了参数量,但是也有信息折损的代价(例如:输入的两个词不一样,但向量相加之后得到的结果向量可能是一样的);丧失了部分语义(例如:改变两次词的先后顺序,因为词没变,所以按位相加得到的结果向量是一样的)。词向量:上下文信息
【问题3】不一定是某个词前面的词可以帮助预测,它后面的词也会有助于预测。
【解决】假设根据上下文一共找到N个词(由于词向量原本是V维,N<=V)用于预测,每个词向量的维数都是128,这些128维的词向量本身也会在训练NN时一并被训练(最开始先随机初始化赋值),这样NN的参数量变为:(维数词数)+(全连接层的参数量)。
(词向量原本是one-hot编码的V维稀疏向量,可以将这个稀疏向量作为原始输入向量,稀疏向量经过全连接,变成128维的词向量,训练出来的全连接中的128个参数就是维数简化后的128维词向量中的元素。) 矩阵中,每一行都是一个词向量,一共有V个词向量,每个词向量是*N维(N=128)。
矩阵中,每一行都是一个词向量,一共有V个词向量,每个词向量是*N维(N=128)。
二分查找、Huffman树
【问题4】接着上述分析,NN的参数量为:
(维数词数)+(全连接层的参数量)。还能否将参数量继续减少?(维数词数)已经是无法再继续优化了,但全连接层的参数量可以优化,在语言模型中,需要softmax分类的类别太多了,计算速度慢。
【解决】可以用多个逻辑回归来替代softmax,即将一个多分类拆解为多个二分类,使用二分查找进行多个逻辑回归的训练(平衡二叉树分类),对应的运算量级从 降到
降到 。
。
另外,根据长尾分布理论(在中文中,每个词的词频的差异性很大,高频词出现的次数比低频词高几个数量级),对二叉树进行改造:高频词放在树的浅层,低频词放在树的深层,进一步减少运算量。
因此,考虑使用Huffman树,节点的权是词频,不同的词频构成,对应不同的Huffman树。Huffman树,也叫“最优二叉树”,是指用n个节点(都作为叶子节点且有自己的权值)构建的一棵二叉树,树的带权路径长度(WPL:从根节点到目标节点的路径长度与目标节点的权的乘积)最小。为了使WPL最小,需要遵循一个原则:权重越大的节点离树根越近。
训练样本的形成与Huffman树的建立:
- 对语料进行分词;
设置滑动窗口,如果窗口为n,就取出某个词前n个词和后n个词,来预测这个词。
整体语料会根据窗口拆解成多个训练样本。<br /> 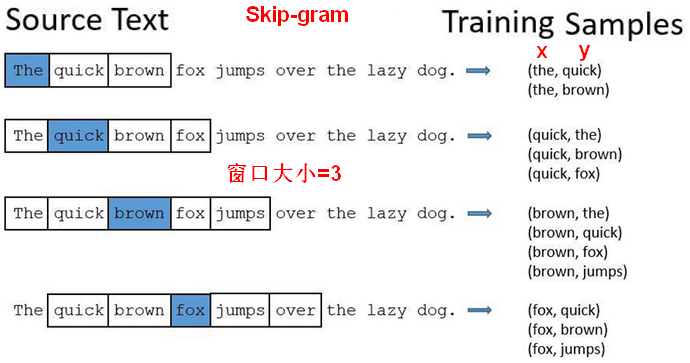
训练之前,从语料样本中统计词频,建立Huffman树。
整体语料的各个词频,决定Huffman树的结构,不同的语料对应不同的Huffman树,同一语料中所有训练样本使用同一棵Huffman树。
-
负采样(negative sampling)
【问题5】:如果不使用Huffman树,还有什么方法可以降低NN的参数量?
假设词汇表含有10000个单词,输入的一个词向量为128维,有一个中间层,则输出为10000维,全连接层的参数量为128*10000(百万级)。
【解决】使用负采样(negative sampling)进行优化。负采样即负样本采样。
softmax训练中,V类中,正确的类的概率应该更大(接近1),剩下V-1类的概率应该更小(接近0),这V-1类对应的单词被称为negative words,从negative words中随机挑选几个作为负样本来更新对应的权重。
假如采样10个负样本,则只用更新11个输出所对应的权重,全连接层的参数量为128*11。对于小规模数据集,建议选5~20个negative words,对于大规模数据集,建议选2~5个negative words。
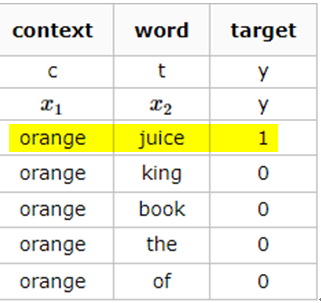
【举例】文本:I want a glass of orange juice to go along with my cereal 。
使用Skip-gram模型,滑动窗口为3。
正样本:采样得到一个上下文词和目标词。先在文本中随机选择一个上下文词,然后在滑动窗口的词距内随机选择一个作为目标词。上下文词-目标词就作为正样本,标签为1。
负样本:使用和正样本一样的上下文词,目标词从字典中随机选择。目标词即使选到了词距内的词,仍然为负样本,标签为0。
每个正样本都有K个负样本来训练一个二分类模型,损失函数为给定样本单词对的情况下的概率。
1.3Word2vec
Word2vec是2013年Google开源的一款用于词向量计算的工具。该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。语言模型的本义是预测词的概率(用周边词预测一个位置出现词的概率),但副产品是输入向量一并被训练了,而且输入向量之间的距离可以表示语义。
例如:我 喜欢 吃 美味的 鸡腿。我 中意 吃 美味的 鸡腿。如果任务都是根据输入词预测出现“鸡腿”的概率,最终训练之后,输入词向量的训练结果会很接近,即“喜欢”和“中意”两个词128维的向量之间的距离很近,这表示两者的词义是接近的。Word2vec的应用
对单词进行向量化,可以寻找近义词;
对文本进行向量化(把词的向量进行相加,得到文本的向量)。Word2vec的四种变体
输入角度的变体:CBOW模型(Continuous Bag-of-Words),Skip-gram模型。具体使用哪个,需要看需求。如果使用时需要将多个向量相加,例如文本向量化,则使用CBOW。如果使用时是单个向量,例如找近义词,用Sikp-gram。原则:使用过程和训练过程越一致,效果越好。
CBOW:从上下文(context)对目标词(target word)的预测中学习词向量的表达。<br />Skip-gram:从目标词(target word)对上下文(context)的预测中学习词向量的表达。<br />例如:五个单词按顺序组成一句话为:,取出语料训练样本的滑动窗口大小为2。则CBOW:; Skip-gram:<br />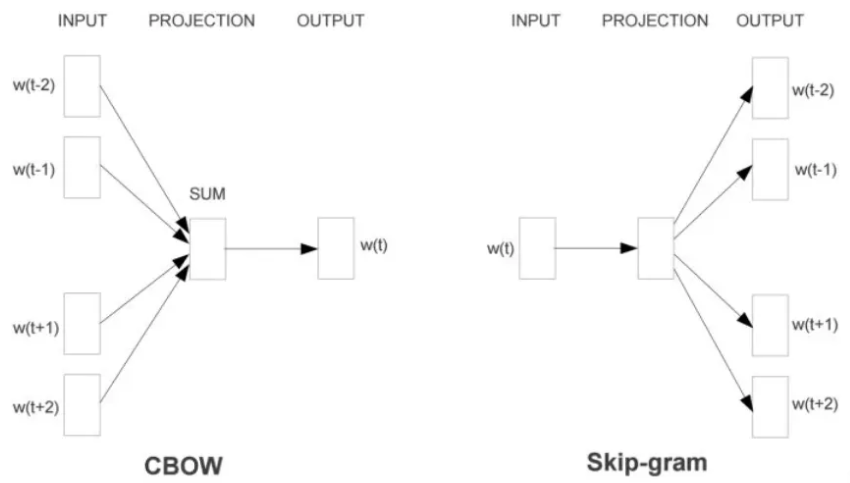
输出角度的变体:Huffman树、负采样NS(negative sampling)。
Word2vec的注意事项
每次训练出来的词向量都在单独的语义空间,不同语义空间的词向量,不具有可比性。
例如:同一个语料,第一次训练会生成一批词向量,第二次训练也会生成一批词向量,这两批词向量是不同的,在不同的语义空间。所以word2vec的词向量只能全量训练,即以整体语料进行训练。
孤岛效应。孤岛效应的本质原因是整体语料是由一些不相关的语料或弱相关的语料组成,导致计算两个不相关的子语料中词的相似度没有意义,差别很大,原本不相似的词会一起出现。Word2vec无法解决这个问题,只能在样本选择时尽可能选择彼此相关的训练样本。
- Word2vec无法解决一词多义的问题。
一词多义问题的解决思路:根据对数据的宏观理解,人为找出一词多义的词,找到词的各个语义对应的上下文;对文本进行替换,把具有多个语义的同一单词变成多个词;然后经Word2vec转成词向量。
例如:
我 买 了 苹果 手机。—->我 买 了 苹果1 手机。
我 在 水果店 买 了 苹果。—->我 在 水果店 买 了 苹果2。
Word2vec的实现工具
- Google原生
- Gensim
- Fasttext(Facebook2016年开源的文本分类器,使用python实现,缺点是对内存消耗大)

若有收获,就点个赞吧
0 人点赞
