推荐系统本质上是为了解决信息过载问题。
广告和搜索业务也可以套用推荐系统的架构。
1.推荐系统
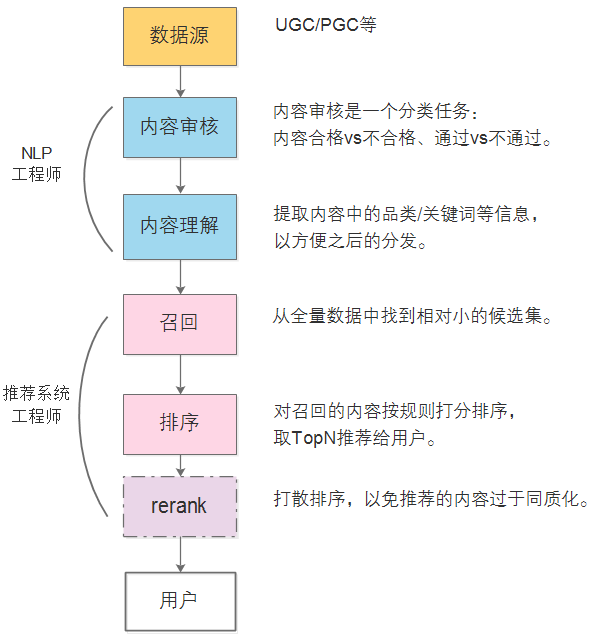
1.1推荐系统的架构
1.2推荐系统的评价指标
点击率
点击率CTR(Click-Through-Rate)即点击通过率,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数(严格的来说,可以是到达目标页面的数量)除以广告的展现量(Show content)。
仅仅重视CTR指标,会导致容易出现三俗内容,而且不同的产品形态有不同的推荐系统,仅比较CTR没有意义。
用户点击率

当CTR高,但Uctr低时,说明推荐系统对资深用户友好,同时有大量的用户流失。
覆盖度
覆盖度=被曝光量/内容总量。
通过覆盖度指标,在内容推荐上,可以知道小众的内容不容易被曝光,推荐系统会进入信息茧房;UGC的内容如果长时间不被消费,可能意味着生产者的流逝。
与产品形态相关的指标
1.3推荐系统的实验方法
AB测试
AB测试是一种在线评测算法的实验方法。AB测试中,将用户按规则随机分成若干组,对不同组的用户采用不同的算法,然后通过统计各个组之间的各种评测指标来比较不同的算法的性能。AB测试可以公平的获得不同的算法实时在线时的性能指标。
桶(bucket):将召回(粗排)或排序(精排)的架构称为一个桶,生产中,一个推荐系统有一般有20多个桶。
分组:为了公平性,每个桶接收的用户应该大体一致,因此需要使用和用户属性无关的内容进行用户分组,例如用户使用设备的ID。
AB桶:A代表基线桶,桶中放置目前已经证实的效果较好较稳定的算法;B代表测试桶,桶中先放置了和基线桶中一样的算法,这是稳定生成的保证,也是AB测试比较算法的基础,再放置新的需要测试的策略。
AAB:为了提高AB测试的可靠性,尽量排除偶然因素对测试结果的影响,可以设置两个基线桶(A),一个测试桶(B),如果通过比较评测指标, ,则证明新增的策略是有效的。
,则证明新增的策略是有效的。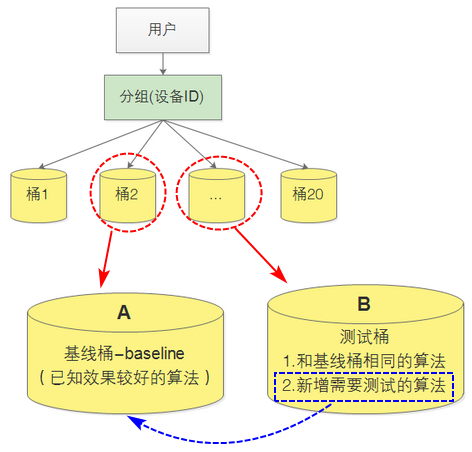
- 经过AB测试,如果测试桶中新增的算法/策略被证明较好,可以把实验后的这个算法/策略放入基线桶;如果新增的策略不能带来评测指标的进步,说明策略是冗余的,适当的冗余可以提高推荐系统的稳定性。
-
2.数据源
做内容推荐的,例如:文章推荐,内容可能来源于UGC,PGC。
做商品/物品推荐的,数据包括物品的元数据(物品属性)等。
数据还包括用户的属性信息、用户对物品/信息的偏好;用户偏好体现在用户反馈中,包括显式的用户反馈(评论、打分等)和隐式的用户反馈(购买、查看等)。3.内容审核
内容审核本质上是一个分类任务,分出可以通过的内容和不能通过的内容。
例如:机器对文本进行分类,对于时效性强的内容,需要人工运营审核的参与。4.内容理解
提取内容中的品类/关键词等信息,便于之后的内容分发;以文本为例,可使用word2vec提取关键词。用算法找出的关键词通常存在的问题是准确率(accuracy)低,召回率(recall)高。
4.1关键词提取方法
TF-IDF
TF-IDF(词频-逆文档频率)是一种统计方法,用以评估一个单词在一个文档集合或语料库中的重要程度。TF-IDF的各种改进版本可用作在给定用户查询时对文档的相关性进行评分和排序。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率高(即TF高),并且在其他文章中很少出现(即IDF高),则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- 关键词表
产品经理根据领域指定关键词表,词表是动态更新的(依赖于“新词发现”)。新词发现就是每天对新文章提取关键词,统计每个关键词出现的文章数,把不在词表里的关键词交给PM审核。
-
5.召回
实践中,往往采用多路召回(各路召回结果取并集),需要人为的设定各路召回的比例权重。
“召回”相当于粗粒度的排序(粗排),“排序”相当于细粒度的排序(精排);“召回”和“排序”两个步骤可以合并,即如果数据量较小,可以直接进行精排,如果对推荐结果的要求不高,可以只做粗排。
5.1基于行为的召回
基于行为的召回,就是通过用户大量的点击来确定对象之间的相似度/关联。
可以认为一个session(即短时间内的一系列连续行为)内,用户的点击意图基本是保持一致的。
【算法】
协同过滤:基于用户的协同过滤。
【问题】行为类召回对新用户、新产品的表现较差。
行为类召回,采样时需注意降低噪声。例如:对于非常热门的item,如果是正样本,应该降低采样次数,如果是负样本,应该提升采样次数。
相似度计算
首先将待推荐的对象转为向量,例如,可以认为用户浏览过并较长时间停留查看的商品是用户感兴趣的商品(positive)、用户浏览却几乎没有停留的商品是用户不感兴趣的商品(negative)、用户不仅浏览而且转发或留言咨询的商品是用户非常喜欢的(love),将它们都表示为向量:

根据向量的内积计算相似度(similar),令
且两个对象向量的内积和它们之间的相似度成正比。
那么用户感兴趣的商品和非常喜欢的商品之间的相似度应该尽量的大,不感兴趣的商品和非常喜欢的商品之间相似度应该尽量的小。(以非常喜欢的商品作为比较基准是因为这类数据通常比较确定可靠)对上述商品进行采样,计算损失: ,令
,令 ,则:
,则: ,
,
基于所有m个用户的所有行为,有:
【问题】对多个用户来说,同一商品可能既是感兴趣的,也是不感兴趣的或者非常喜欢的,如何进行向量化?
划分向量空间,例如:假设用户感兴趣(positive)的对象所在向量空间为 ,用户不感兴趣(negative)的对象所在向量空间为
,用户不感兴趣(negative)的对象所在向量空间为 ,用户非常喜欢(love)的对象所在的向量空间为
,用户非常喜欢(love)的对象所在的向量空间为 。
。
训练使用分离:中对应的向量才是最后实际使用的(因为该空间的用户行为最精准),和 空间对应的向量只是在训练时辅助使用。训练数据时,使用itemID关联item数据,因为是基于行为的召回,并不关心item的内容。训练的结果就是得到空间的一批item向量,例如keras中Embedding层训练之后可以得到一个item“字典”,可以根据索引取出某个item的向量。
空间对应的向量只是在训练时辅助使用。训练数据时,使用itemID关联item数据,因为是基于行为的召回,并不关心item的内容。训练的结果就是得到空间的一批item向量,例如keras中Embedding层训练之后可以得到一个item“字典”,可以根据索引取出某个item的向量。
5.2基于内容的召回
基于内容的召回,就是从内容中抽取标签/关键词,通过内容之间的标签/关键词进行推荐。
【算法】文章相似度召回:使用LDA、Word2vec等算法分析词语、文章的相似度。
- 用关键词做召回:1)根据用户浏览文章的历史和文章的关键词信息得出用户画像(短时用户画像+长时用户画像),再根据用户画像中的关键词信息,召回含有这些关键词的文章列表,推荐给用户。2)两篇文章如果有共同的关键词,可以由一篇文章推荐另一篇文章,关键词/贡献词最好带有权重,这样可以对推荐的多篇文章进行排序。
【问题】
- 内容类召回,做内容理解的成本有时会比较高,例如对视频类内容的召回。
信息茧房(Information Cocoons)问题,即基于内容的相似度做推荐,导致推荐的内容类型越收越窄,信息偏食,内容单一化。
6.排序
排序就是对召回的结果进行曝光过滤,对曝光过滤后剩下的进行打分排序,取TopN推荐给用户。
打分排序实质上是根据要推荐的内容的特征(热度、属性及关键词等)和用户画像训练一个分类模型,二分类为用户会点击、不会点击。
6.1分类模型
在深度神经网络DNN出现之前,用逻辑回归(Logistic Regression)训练分类模型,之后,用DNN训练模型。
实践中,分类模型训练这一部分通常非常消耗计算资源,因为需要响应大量用户,例如通过点击率预估用户是否会点击,通常只能动态计算。7.推荐系统举例
7.1Airbnb房源推荐
分析数据,并定义正负样本。
booking:用户实际预订的房子。
讨厌房源:在预订的地理周边但没有被用户点击过的房子。
正样本:一个session内用户点击过的房子。
负样本:全局随机抽取一些房子。
来源: 1.《深入解读Airbnb推荐算法》https://blog.csdn.net/Zhangbei_/article/details/87821401

若有收获,就点个赞吧
0 人点赞
