1.线性不可分问题
线性回归:已知坐标的一部分,预测另一部分。
逻辑回归:已经完整的坐标,计算点和直线的相对距离。
分类问题中,线性模型会遇到对数据无法分类的问题,如何解决?(如下左图)
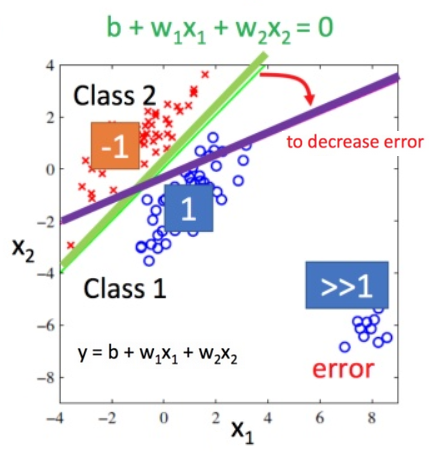
用回归方式解决分类问题,对类别偏离较远的error,分类线会发生偏移,导致效果不理想(如下右图)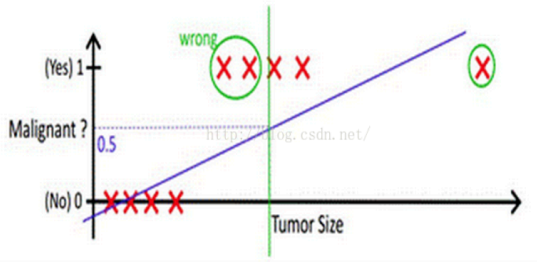
线性模型的y取值范围为: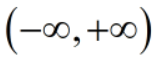 ,对于二分类问题(多分类问题也可以转为为二分类),
,对于二分类问题(多分类问题也可以转为为二分类),
可以从以下三个思路来思考解决线性模型无法分类的问题:
- 弃用线性模型,改为非线性模型;
- 将线性模型映射到高维空间【特征组合、扩维、特征分段】,例如,用超平面来分类;
- 使线性模型的预测值逼近真实值的衍生物,例如,
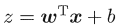 ,加入输出值在指数尺度上变化,则可以去逼近真实值的对数:
,加入输出值在指数尺度上变化,则可以去逼近真实值的对数: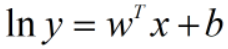
广义线性模型(generalized linear model)
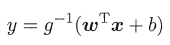
 称为联系函数(link function)。根据以上思路,假如能找到一个单调可微函数,可以将线性回归模型的预测值和分类问题中的真实标记y联系起来,就相当于用线性回归模型解决了二分类问题。
称为联系函数(link function)。根据以上思路,假如能找到一个单调可微函数,可以将线性回归模型的预测值和分类问题中的真实标记y联系起来,就相当于用线性回归模型解决了二分类问题。
对数几率函数(logistic function)就是满足要求的一个单调可微函数。
对数几率函数
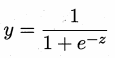
逻辑回归的意译为对数(logit)几率回归。根据以上思路,用线性回归模型的预测值去逼近真实标记的衍生物,即真实标记的对数几率(log odds 或 logit),几率表示样本为正例的可能性与反例的可能性的比值,几率取对数就得到对数几率: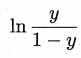
【问题】分段函数也可以用来做二分类,为什么联系函数不使用单位阶跃函数?
- 单位阶跃函数的分类比较“暴力直接”,常常不符合实际业务的需求。
- 单位阶跃函数不连续,不单调可微,不能用作联系函数。
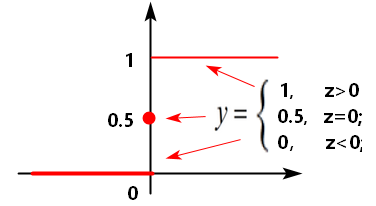
逻辑变换
将对数几率函数代入广义线性模型,得到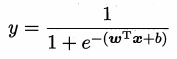 ;
;
用预测值逼近真实标记的对数几率,得到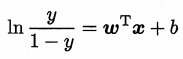 ,即。
,即。
通过逻辑变换,将线性回归的预测值从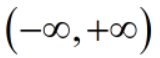 ,缩放到了(0,1),代表对分类类别的概率预测。
,缩放到了(0,1),代表对分类类别的概率预测。
逻辑回归也是广义线性模型的一种。
2.逻辑回归
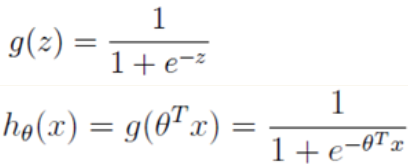 ,在坐标轴上表现如下:
,在坐标轴上表现如下: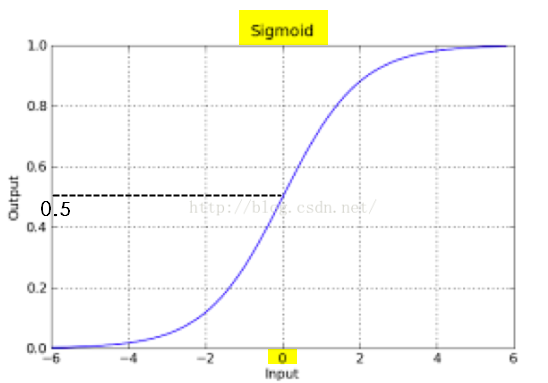
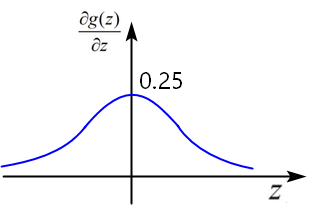
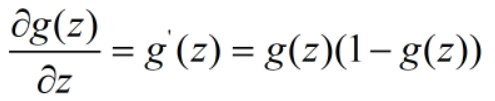 ,导数的函数图像呈现正态分布。
,导数的函数图像呈现正态分布。
Z越大,点距离划分分类界限的直线越远。
2.1逻辑回归公式的推导
推导1(广义线性模型、联系函数)
用线性回归模型去拟合真实值的对数,这个对数是对数几率:。
逻辑回归函数是广义线性模型的一种,对数几率函数是单调可微的,分类概率的分布呈现是平滑的。
推导2(贝叶斯、正态分布)
分类情景:样例(x,y),x表示身高,y表示性别分类,y=1时是男性,y=0时是女性。
【假设】对一个具体类别来说,它的特征符合正态分布,比如:身高符合正态分布。
则,身高为1.7米的男性的概率为: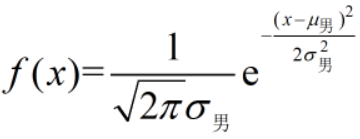 (x=1.7)
(x=1.7)
当已知特征,求分类类别时,例如:已知一个人的身高为1.7米,ta是男性的概率为多少?
根据贝叶斯公式,可知x=1.7米时,ta为男性的概率和为女性的概率分别为:
并且: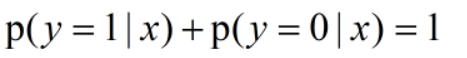
两者相除可得: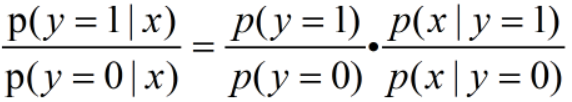 ,令
,令 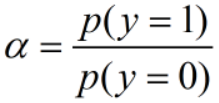 ,
,
p(y=0)和p(y=1)是先验概率,α 是一个常数项。
根据以上假设和概率密度函数可知: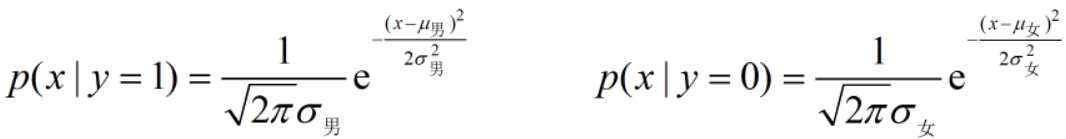
【假设】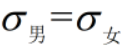 ,因为统计学上,对于同质的事物,各类别的特征分布的方差是基本一致的。
,因为统计学上,对于同质的事物,各类别的特征分布的方差是基本一致的。
代入以上式子可得: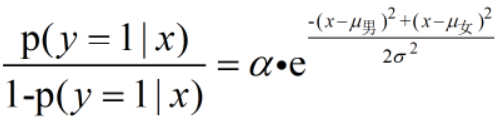 ,化简后,可得,这个身高1.7的人是男性的概率为:
,化简后,可得,这个身高1.7的人是男性的概率为: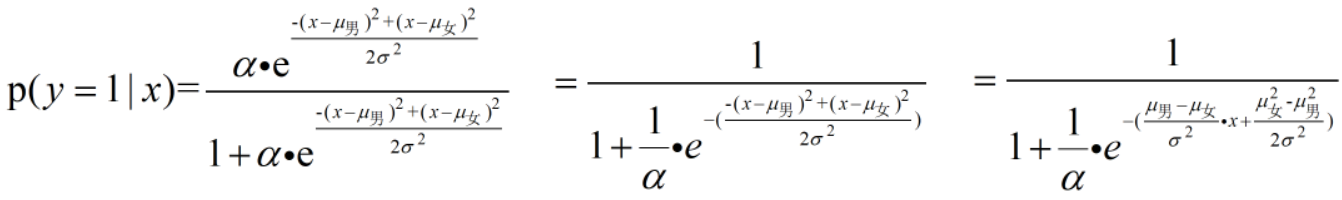
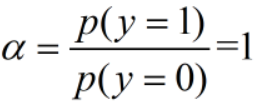 ,
,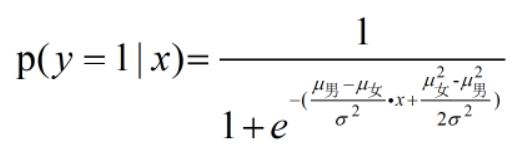
逻辑回归的默认假设前提
由以上逻辑回归表达式推导的过程,可总结使用逻辑回归时的前提假设:
- 对一个具体类别来说,它的特征符合正态分布。
- 对于同质的事物,各类别的特征分布的方差是基本一致的。
- 每个类别对应的样本数量(大致)相同,即出现的概率相同。(也能解释:样本不均衡时,需要下采样、上采样)
判别式模型
从以上逻辑回归表达式推导的过程可知,参数为: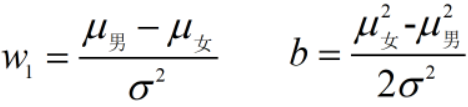
因此,参数和数据集总体各类别的均值和方差有关,根据求值得出参数,并计算概率。
由此可以说,逻辑回归模型是一个判别式模型。2.2误差
假设分类的真实概率分布为 Y,预测的概率分布为 f,Y 与 f 之间的分布差异就是误差。
要减小误差,就要让全部预测正确的概率越大越好;
或者估计模型与真实概率分布之间的差异越小越好。2.3 损失函数
损失函数的推导1(概率、似然估计)
确定了一组w 或 theta 就确定了 z,确定了z 就确定了 g(z) 的输出, 那么g(z) 也可以写成 g(w,x)。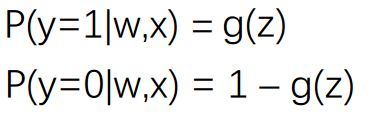 ,进而表示如下(二项分布或伯努利分布):
,进而表示如下(二项分布或伯努利分布):
根据最大似然估计(训练模型,就是要找到一组参数w,使得逻辑回归函数输出既定概率的可能性最大),为了模型预测有最高的准确率,即找到一组theta值,使似然估计的L(theta)有最大值。为了将乘积展开,等式两边取对数,而且对数函数最大时(单调递增),L(theta)也最大。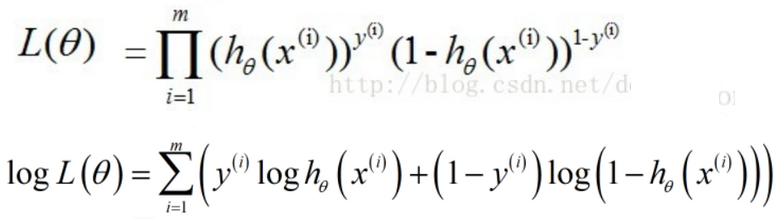
损失函数: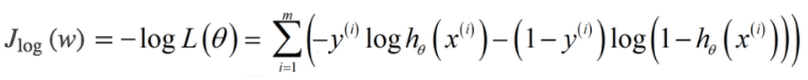
以上损失函数又叫交叉熵损失函数(Cross Entropy Loss)。损失函数的推导2(KL距离)
假设分类的真实概率分布为 Y,预测的概率分布为 f。由KL距离(相对熵)公式: 可得:
可得: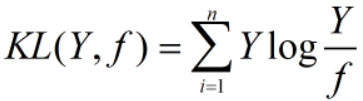
为了使KL距离尽量的小,结合对KL距离非对称性的分析可知:
当Y=1时,f 也应该拟合1;
当Y=0时,此时 f 的取值对距离影响不大,无法从缩小KL距离的目标中学习到。
因此,为了在两种分类情况中,预测概率都可以进行有效的学习,可令: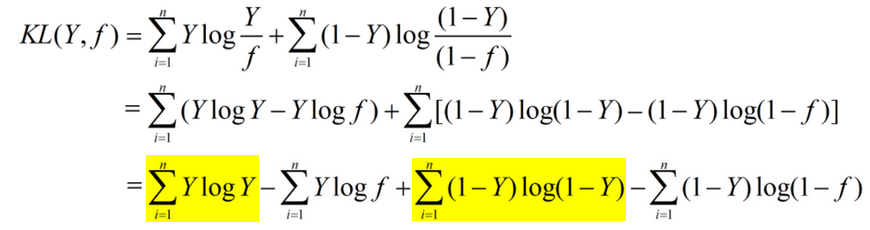
Y是真实概率分布,是已知值,为常数项,忽略上述两项,得到损失函数如下:
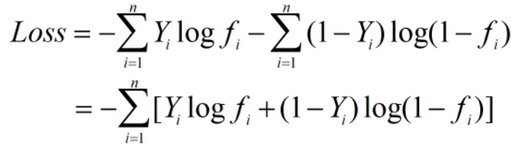
交叉熵和MSE
【问题】能够用MSE作为逻辑回归的损失函数?
不能。
- 第一,参数w无法通过学习来更新。
假设分类的真实概率为y,预测的概率为 f。如果使用MSE,替代交叉熵作为损失函数,则: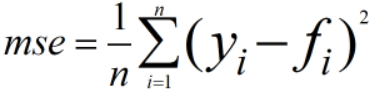 ,其中
,其中 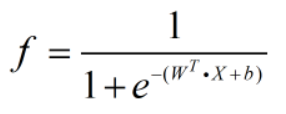 ,
,
为了得到mse极小值,求导如下: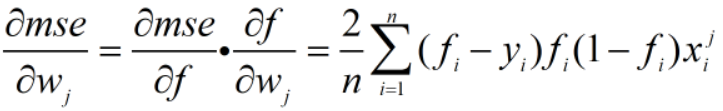
由sigmoid函数曲线变化可知,预测值 f 容易趋近于0 或 1,此时,导数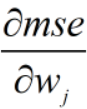 的值趋近于0,
的值趋近于0,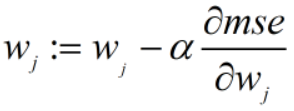 , 参数 w 初始值较大时,导数趋近于0,还没有正确分类就无法继续学习了。
, 参数 w 初始值较大时,导数趋近于0,还没有正确分类就无法继续学习了。
- 第二,上述的MSE函数不是凸函数,有多个局部极小值,通过学习可能得到的是局部极小值。
局部极小值的数量和维度的平方成正比,很难选择到合适的初始出发点进行梯度下降。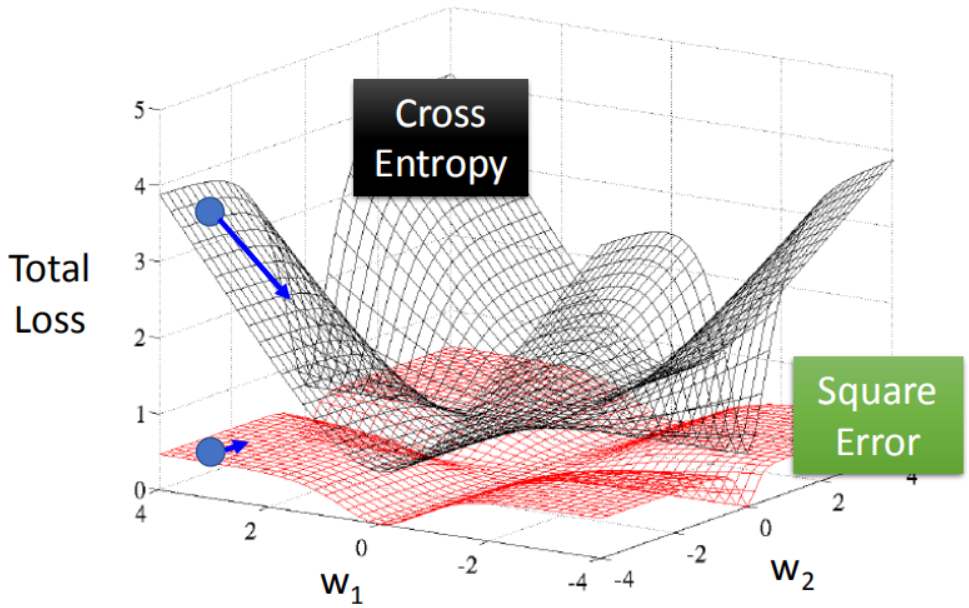
2.4 交叉熵
熵 (entropy) 这一词最初来源于热力学。1948年,克劳德·爱尔伍德·香农将热力学中的熵引入信息论,所以也被称为香农熵 (Shannon entropy),信息熵 (information entropy)。熵代表的是随机变量或整个系统的不确定性,熵越大,随机变量或系统的不确定性就越大。
一条信息的信息量大小和它的不确定性有直接的关系。可以认为,信息量的度量就等于不确定性的多少,不确定的多少可以用概率分布来表达,信息的量度应该依赖于概率分布 p(x)。
信息量
如果有两个不相关的事件 x 和 y,那么两个事件同时发生时获得的信息量应该等于观察到事件各自发生时获得的信息之和: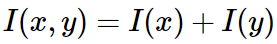 ,两个事件是彼此独立的:
,两个事件是彼此独立的: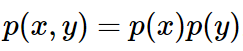
I(x) 也被称为随机变量 x 的自信息 (self-information),描述的是随机变量的某个事件发生所带来的信息量。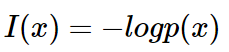

熵
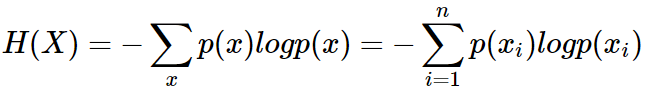
H(X) 被称为随机变量 x 的熵,表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。从公式可得,随机变量的取值个数越多,状态数也就越多,信息熵就越大,混乱程度就越大。当随机分布为均匀分布时,熵最大,且 0≤H(X)≤logn。
交叉熵
现在有关于样本集的两个概率分布 p(x) 和 q(x),其中 p(x) 为真实分布, q(x) 非真实分布。
用真实分布 p(x)来衡量识别别一个样本所需要编码长度的期望(平均编码长度)为: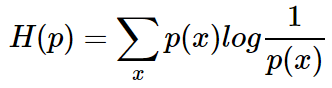
使用非真实分布 q(x)来表示来自真实分布 p(x) 的平均编码长度,则是: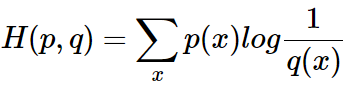
此时就将H(p,q) 称之为交叉熵。交叉熵用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出成本的大小。
交叉的字面意思在于:真实分布与非真实分布的交叉。给定一个方案, 越优的策略, 最终的交叉熵越低,具有最低的交叉熵的策略就是最优化策略。
交叉熵的概念用以衡量估计模型与真实概率分布之间的差异,代表两个分布之间有多接近。当交叉熵最低(等于训练数据分布的熵)时,就相当于学到了最好的模型。
逻辑回归的损失函数中,体现了交叉熵的概念: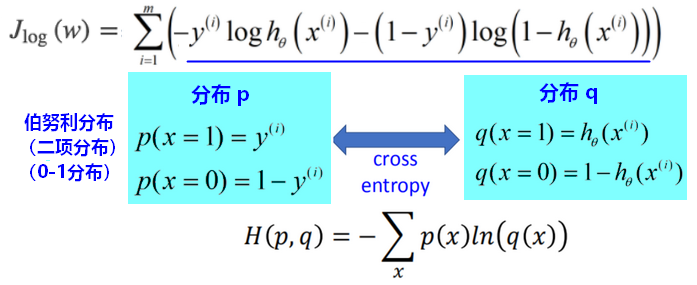
2.5 梯度下降
损失函数:
通过梯度下降,最小化损失函数:(以下的theta就是 w,代表参数)
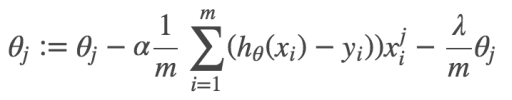
从以上求导的过程可以看出:模型预测值距离target越远,导数值就越大,参数更新的越快。
2.6 逻辑回归 vs 线性回归

3.分类中的问题
3.1数据倾斜问题
unbalance数据倾斜问题:数据的类别分布极不均匀。此时,可能导致分类器虽然正确率很高,但是分类没有意义,并不能正确分类。
分类阈值为0.5时,分类器规则为:若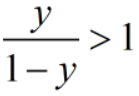 ,则为正例。此时,当类别不平衡时,分类器容易偏向数量更多的类别,正确率虽高,但分类器没有价值。
,则为正例。此时,当类别不平衡时,分类器容易偏向数量更多的类别,正确率虽高,但分类器没有价值。
【问题】如何解决分类中的数据倾斜问题?
解决:数据平衡手段。
- (上采样)将类别占少数的样本复制多份,直到数量相当。
不能简单的对占少数的样本进行重复采样,否则会导致过拟合。
上采样的代表性算法:SMOTE(对样例进行插值来产生额外的样例)。
- (下采样)减少类别占多数的样本数据量,使之分布均匀。生产中,一般使用上采样。
下采样也不能随机丢弃,否则会丢失一些重要信息。
下采样的代表性算法:EasyEnsemble(利用集成学习,将样例划分为多个组供不同的学习器使用)。
再缩放。就基于原始训练集进行学习,但在使用分类器进行预测时,进行阈值移动,即对预测值进行缩放(rescaling)。再缩放的前提是:假设训练集是真实样本总体的无偏采样,即训练集观测几率就代表真实几率。
3.1.1 再缩放
【假设】训练集是真实样本总体的无偏采样,即训练集观测几率就代表真实几率。
如果观测几率是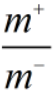 ,分类器的预测几率是
,分类器的预测几率是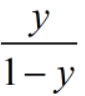 ,只要
,只要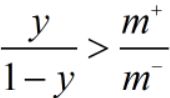 ,则预测为正例。
,则预测为正例。
当类别不平衡时,对预测值进行调整: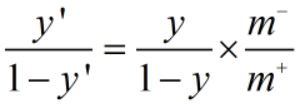 ,这样,当基于
,这样,当基于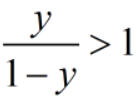 决策时,实际是执行了。
决策时,实际是执行了。
3.2多分类问题
多分类问题的解决思路:
将n分类转成n个2分类 ,训练出n个逻辑回归的模型 ;
把n分类变成n个二分类,可以灵活应对生产中的分类变动。
-
3.2.1 softmax表达式**
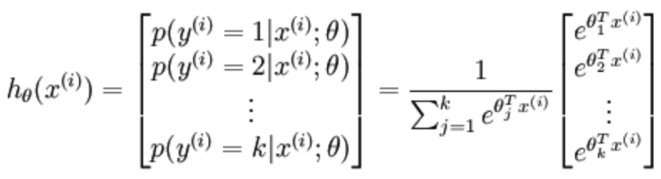
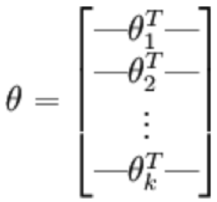
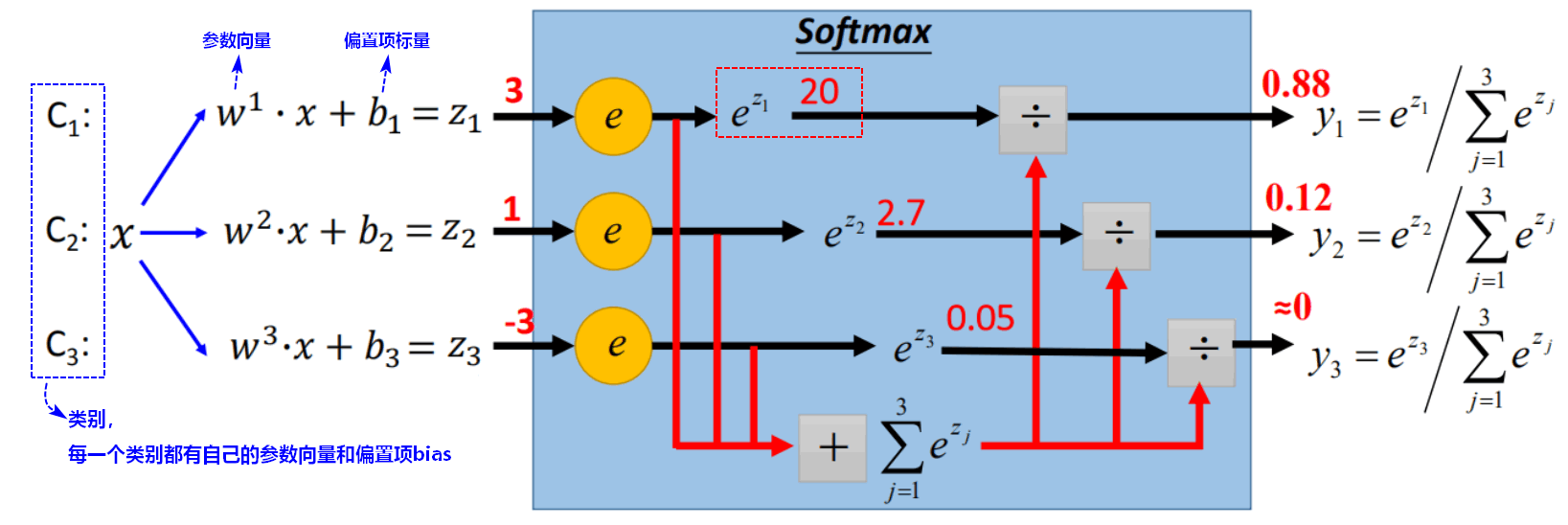
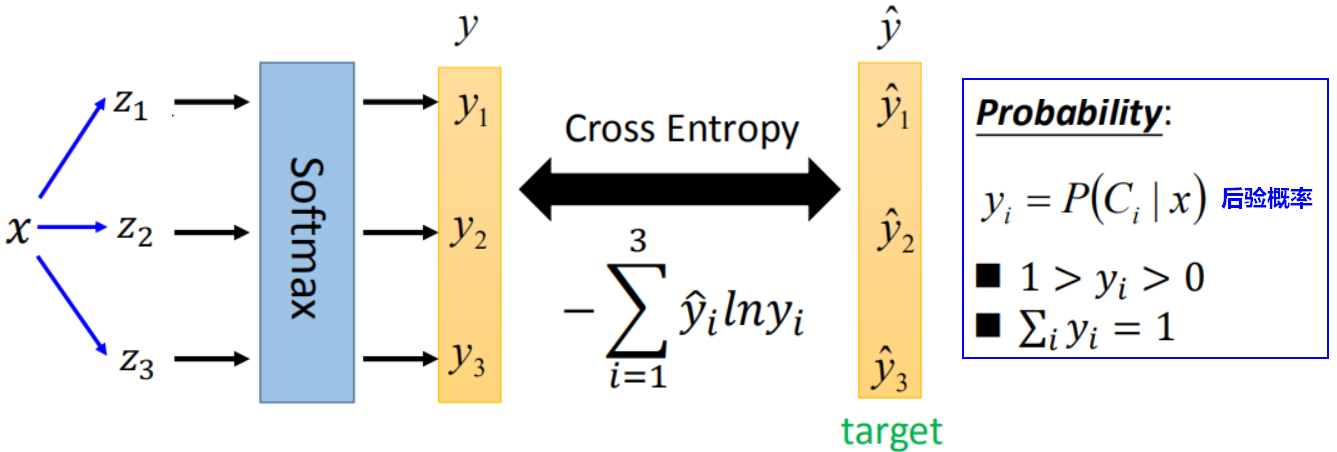
3.2.2 softmax损失函数
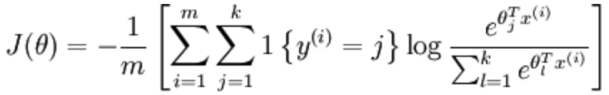
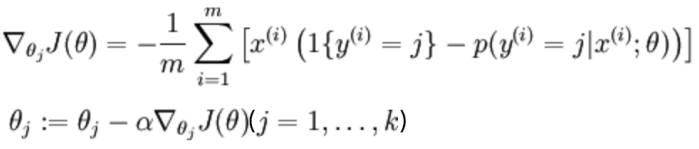
3.3 逻辑回归的限制
3.3.1 异或问题
【问题】以下样例,使用逻辑回归能否正确分类?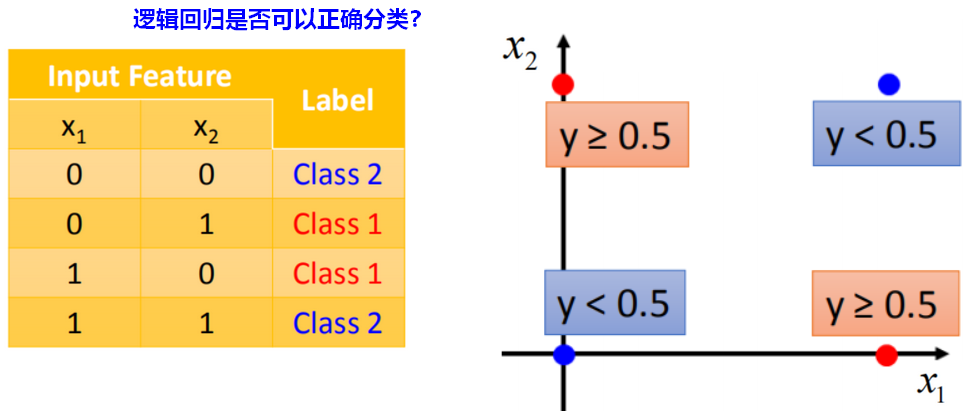
【解决1】特征转换(Transformation):将原本的输入统一使用某种方法转换,使得可以做出分类。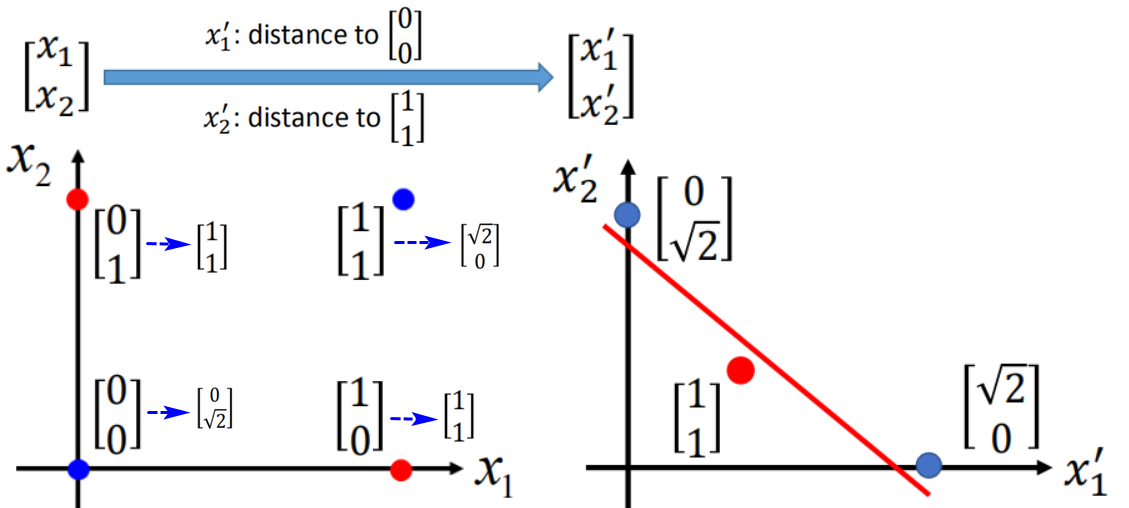
【解决2】级联模型:神经网络
特征转换的方法并不是很容易找出,而且是人工的将问题变得可分,我们期望机器自己找出分类的方法。将很多个逻辑回归模型级联在一起,就可以自动完成特征转换。每个逻辑回归单元就是神经网络中的神经元(Neuron)。
3.3.2 特征耦合
逻辑回归的输出是用来估算后验概率(Posterior Probability):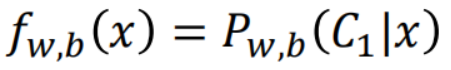 ,
,
输出的推导中,假设了特征符合正态分布,正态分布中特征项是耦合的,所以逻辑回归中样本的各个特征项也是耦合的: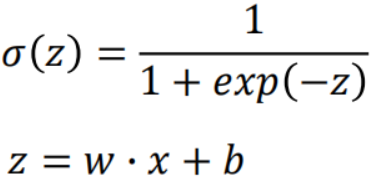 若每条样本有 x1,x2,x3三个特征项,如果缺少一个,则无法计算概率。
若每条样本有 x1,x2,x3三个特征项,如果缺少一个,则无法计算概率。
【解决】将特征项之间解耦>>>>朴素贝叶斯
1.台湾大学李宏毅教授《机器学习》 2.周志华《机器学习》

若有收获,就点个赞吧
0 人点赞
