1.图像检索
1.1图像检索的分类
- 基于文本的图像检索技术TBIR(Text-based Image Retrieval):利用文本来描述图像的特征,如绘画作品的作者、年代、流派、尺寸等。(20世纪70年代出现)
- 基于内容的图像检索CBIR(Content-based Image Retrieval):对图像的内容语义,如图像的颜色、纹理、布局等进行分析和检索的图像检索技术。(20世纪90年代出现)
1.2图像检索的应用
图像检索系统具有非常大的商业价值,从搜索引擎的以图搜图,到人脸验证和识别系统,到一些搜索排序系统(比如基于美学的摄影图库)。由于图像特征的学习是一个通用的研究方向,因此更多的在于设计高效的检索系统。2.CBIR
2.1传统方法的CBIR
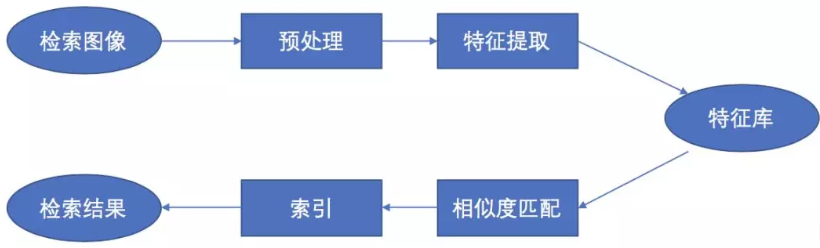
传统方法在检索时逐个与数据库中的每个点进行相似性计算然后进行排序,这种简单粗暴的方式会随着数据库的大小以及特征维度的增加其搜索代价也会逐步的增加。2.2深度学习方法的CBIR
分类问题:
各个类别互斥(互斥:有且仅可能属于一个类别)时,用softmax进行分类;
各个类别不互斥时,用逻辑回归进行分类,每一类单独进行“是非”判断。
需求分析:
手写数字识别(OCR)中,0~9个数字,输出一共分成11类(十个数字:0~9+一个拒绝类:其他)。
如何产生拒绝类?
1.分析产品形态,收集拒绝类的数据。例如:拿该类产品容易出现的其他图片作为拒绝类。
2.随机生成拒绝类。例如:生成雪花图片。
3.从已有训练样本中随机截取拼接成拒绝类。例如:随机截取两个类别中的图片,拼接成一个新图片。
因为拒绝类很多,无法穷尽,所以应该尽量使用多种不同的方式生成拒绝类。
模型训练中的注意事项:
理解需求:任务目标是什么,损失是什么
1.先用简单的模型训练,再根据效果逐步增加复杂性。(奥卡姆剃刀)
2.先用小量数据训练,观察loss下降的情况,以此判断模型是否合理。
3.数据反馈系统:模型上线后,定期收集bad case(即用户对模型识别任务对错的判断),进行二次学习。
对于个别无明显规律的badcase,收集它们作为训练样本,fine-train模型。
对于有规律的错误(例如:3和8的识别),就针对这些错误额外训练分类器,当主模型预测结果为容易出错的结果时(例如:主模型预测为3或8),就使用额外的分类器再次进行预测。
4.考虑(数据、模型)长期更新的问题。
模型训练过程中需要Shuffle么?
Shuffle即在每一轮次(epoch)前打乱训练数据,是一种训练的技巧,因为机器学习其假设和对数据的要求就是要满足独立同分布。所以任何样本的出现都需要满足“随机性”。所以在数据有较强的“人为”次序特征的情况下,Shuffle显得至关重要。
但是模型本身就为序列模型,则数据集的次序特征为数据的主要特征,并且模型需要学到这种次序规律时,则不可以使用Shuffle。否则会将数据集中的特征破坏。
Shuffle为什么重要? 1.Shuffle可以防止训练过程中的模型抖动,有利于模型的健壮性 假设训练数据分为两类,在未经过Shuffle的训练时,首先模型的参数会去拟合第一类数据,当大量的连续数据(第一类)输入训练时,会造成模型在第一类数据上的过拟合。当第一类数据学习结束后模型又开始对大量的第二类数据进行学习,这样会使模型尽力去逼近第二类数据,造成新的过拟合现象。这样反复的训练模型会在两种过拟合之间徘徊,造成模型的抖动,也不利于模型的收敛和训练的快速收敛。 2.Shuffle可以防止过拟合,并且使得模型学到更加正确的特征
NN网络的学习能力很强,如果数据未经过打乱,则模型反复依次序学习数据的特征,很快就会达到过拟合状态,并且有可能学会的只是数据的次序特征,缺乏泛化能力。
3.为使得训练集,验证集,测试集中数据分布类似。
以图搜图
方案:
1.计算图片像素之间的相似度(计算距离)。
问题:很容易受图中物体位置、噪声、风格的影响,而且计算量大。
2.转换成分类问题:图库中一个图片一个类,N个图片N个二分类,对输入图片的分类结果求相似度得分。
问题:类别过多,在线负担重;训练样本收集成本太高。
3.非深度学习的做法:
图像分割成若干小区域,统计每个区域的几何特征。
缺点:需要很强的领域知识,不同的领域需要有不同的统计特征的方法,不像深度学习那样可以进行特征的自动学习,所以深度学习也叫自动特征提取器。
4.深度学习对图像编码
噪声:对图像进行有损压缩(这会尽量留住图像最重要的信息),压缩后的结果含有噪声会大大减少。
好的压缩:
保留了原图最重要的信息;将压缩后的结果恢复到原图大小后,和原图的差距最小。
encoder-decoder,用有监督学习的方式完成了无监督学习,decoder是为了辅助训练encoder而存在的,decoder进行有损恢复。
避免硬匹配,这样可以对所有匹配的结果做出排序。
annoy python
编码
无损:源码编码之后生成的结果是唯一的,结果还原之后可以得到唯一的源码。
有损:无损之外的情况,例如多个源码编码后得到的结果信号是一致的
通信领域,要求信号无损传递,传递过程中可以抵抗噪声干扰。信号可理解为是几乎没有噪声的。编码只考虑自身信息。
机器学习领域,希望是有损编码,通过编码进行特征提取,消除信息量少的东西。信号本身是有噪声的,通过有损编码将噪声损失掉。机器学习中,编码需要考虑全局信息(考虑自身信号和其他信号数据,例如onehot,encoder等),要求有一定的数据量,当数据变化时,需要重新编码。
以图搜图:
重视准确率时,encoder进行降维,提取关键特征。
重视召回率时,encoder进行升维,是为了充分展现特征,除了原来的特征,还包括了特征组合。
升维的问题:升的太高,可能就变成单纯的特征复制,为了约束,可加入L1正则,使得生成的高维向量是一个稀疏向量;这样一张图片就只在这个稀疏向量的部分维度上有较大的值,于是得到图片特征的正排索引。
图片特征的正排索引:将图片编码为索引值,给出索引的地方特征值较大,其他没给出索引的地方特征值为0(L1正则化之后特征为0)。
为上述正排索引的图片建立倒排索引,将用户给出的图片encoder之后,得到正排索引,然后根据之前建立的倒排索引去搜索出相似的图片。

若有收获,就点个赞吧
0 人点赞
