1. CNN属性
1.1 CNN的用途
CNN常常被用来做影像处理。
当使用DNN 全连接来处理影像时,往往需要太多参数;而CNN就是用来简化这样的网络结构。因为,CNN处理影像数据时,是基于一些特性/属性的,可以利用更少的参数。
1.2 CNN的三个属性
Small region
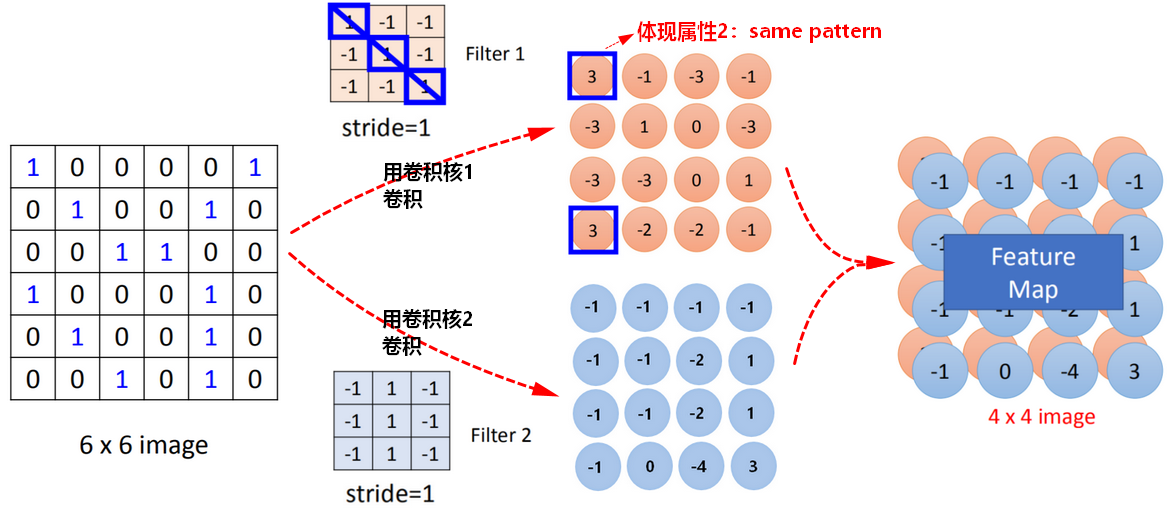
- (需要识别的)一些模式(Pattern)只是图片中的一小部分。>>>更少的参数!
对于人来说,并不需要看完整张图片才知道图中有什么、是什么;对神经网络来说,也是这样。即神经元只需要连接到某一个局部区域。
【实现】使用 Filter 进行卷积(convolution)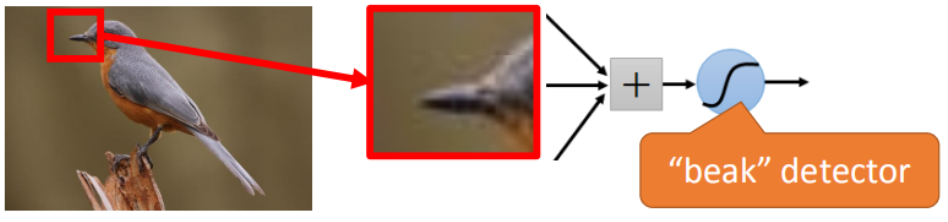
Same pattern
- 同样的模式(Pattern),会在不同的区域出现。>>>更少的参数!
因为是同样的模式,意味着有同样的含义、形状等,使用相同的参数就可以把它检测出来。
Same pattern 说明了卷积神经网络具有平移不变性(translation invariant),即可以学习到局部模式,并在任意地方识别这个模式。
【联想】因为相同模式、高度通用模式的存在,所以深度学习模型本质上具有高度的可复用性,许多预训练(pretrain)的模型都可以拿来微调(fine-tuning),用于提取特征(extraction),构建强大的模型。
【实现】使用 Filter 进行卷积(convolution)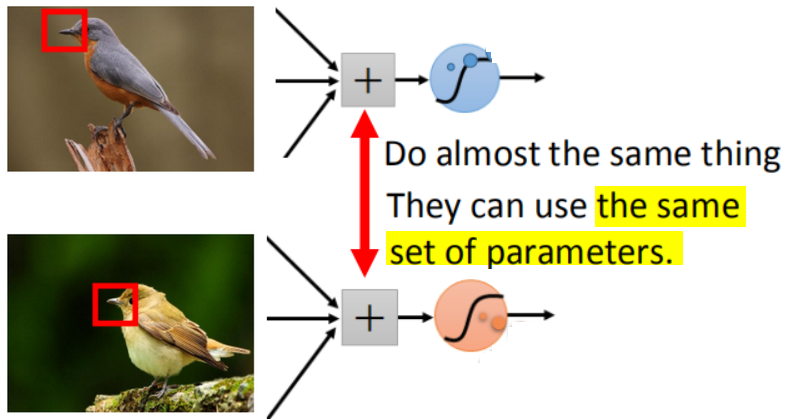
Subsampling
- 采样(subsampling)一些像素,不会影响到对象本身。>>>更少的参数!
采样一些像素,使图像变小,并不会影响到对图片的理解,但此时输入神经网络的参数变少了。
【实现】使用池化(例如:max pooling)
2. CNN网络
2.1 卷积(convolution)
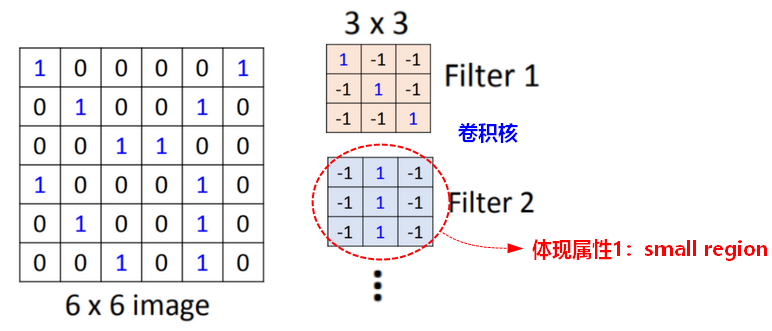
卷积核:Filter
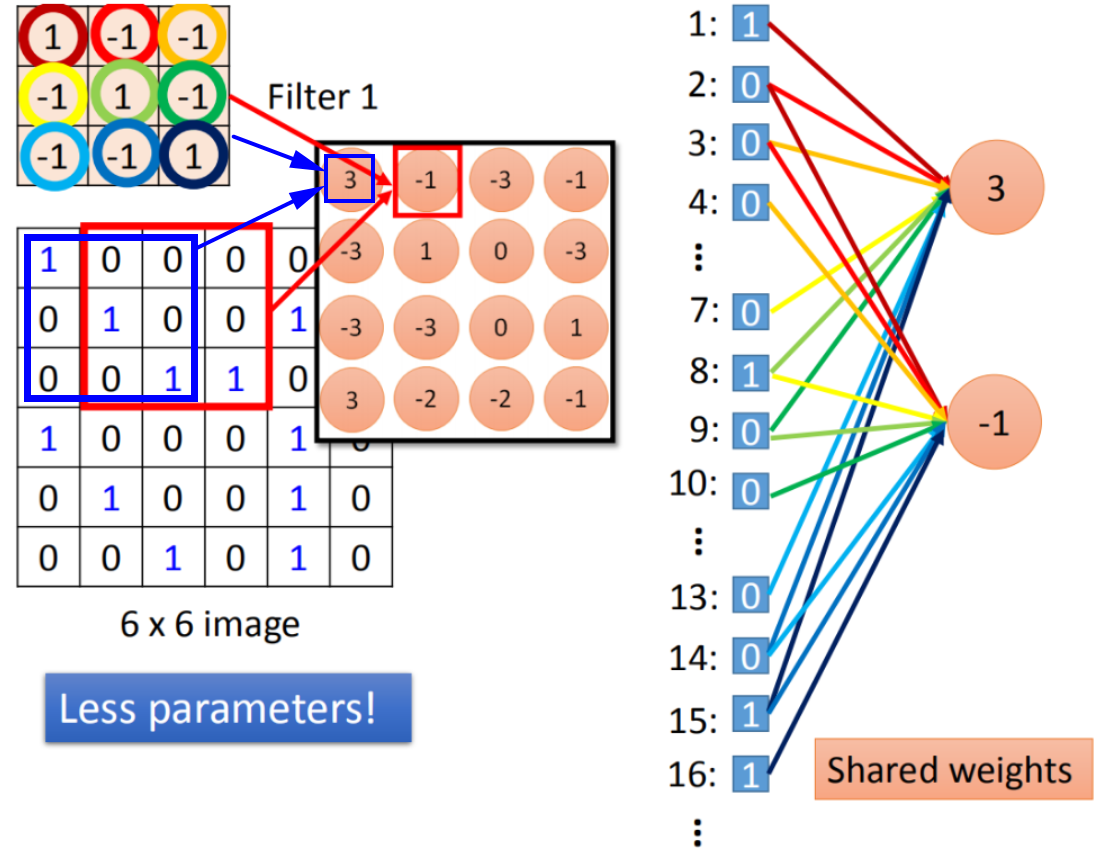
卷积核相当于神经网络中的神经元(neuron),
Filter矩阵中的元素就是网络中的参数W。
卷积核相当于是关于基本形状的模板,不同的识别任务对形状的提取是不同的,卷积模板也不一样。但卷积模板无法通过人为设定,需要学习出来。
一般的,经过卷积后,并不改变原始图像的大小(可能需要做填充padding),可以改变卷积后的频道channel。
【问题】卷积核为什么被称为过滤器?
卷积用于从原图中提取特定的结构形状,也就是去除了不想要的形状,所以卷积核称为过滤器。Filter相当于一个局部模式匹配器,如果匹配到了,表示被激活的程度(Activation Degree)最大。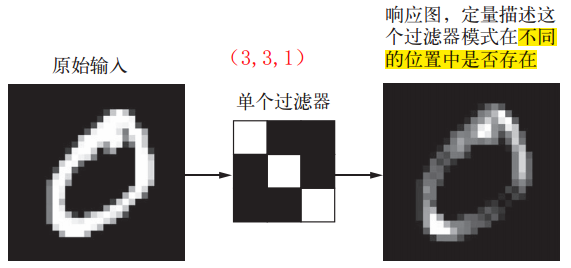
Feature Map
feature map的大小是由卷积核的大小和步长决定的;
有多少个Filter,feature map中就有多少个图像(image)。
feature map越多(即channel越多),提取到的形状越多。
【问题】卷积后的feature map的大小如何计算?
假设O是原始图像矩阵的大小,F是卷积核的大小,P是填充大小,S是步长(stride),
则Feature Map的大小 : 
下采样
步幅为N(N>1)的卷积叫做步进卷积(strided convolution),相当于对输入做了N倍下采样,实践中较少使用,为了下采样,一般使用池化。
多通道的卷积
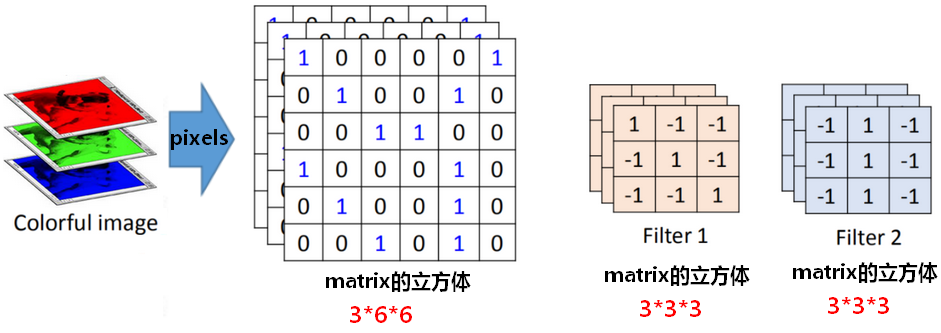
对于RGB三通道的彩色图片,卷积时,每个Filter内部也有三个和通道对应的矩阵,三个通道(channel)一起同步卷积。
卷积核Filter在卷积时,会考虑深度。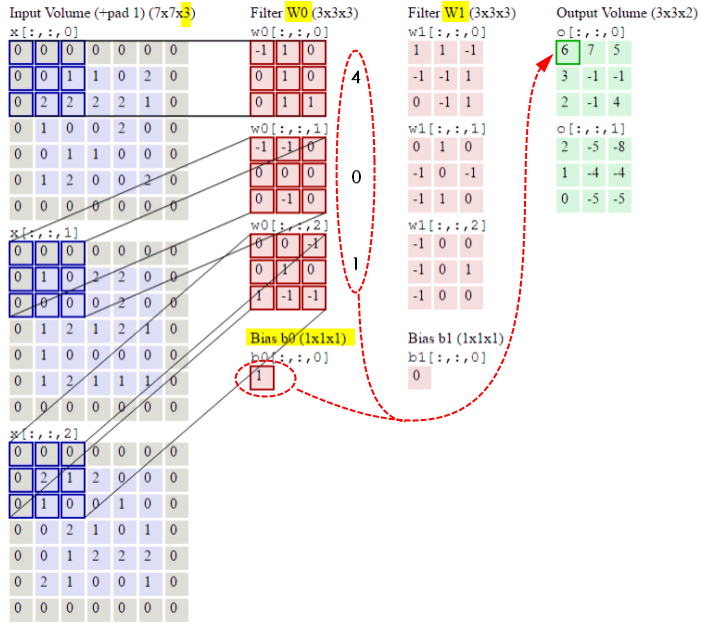
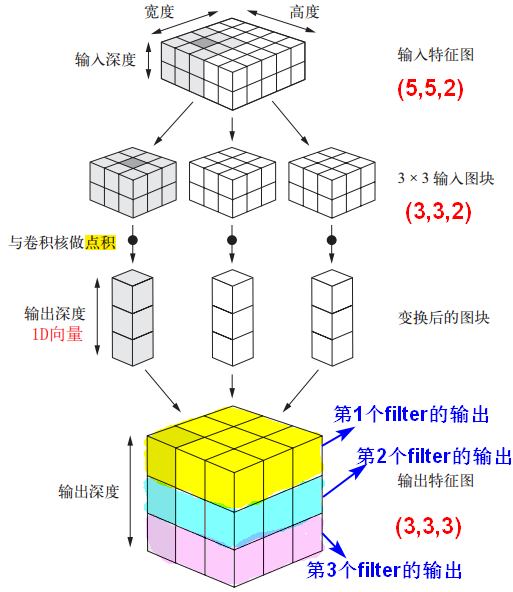
深度可分离卷积
SeparableConv2D:二维深度可分离卷积层。不同于普通卷积同时对区域和通道操作,深度可分离卷积先操作区域,再操作通道。即先对每个通道做独立空间卷积(先操作区域),再用逐点卷积(1x1卷积)跨通道组合(再操作通道)。这相当于将空间特征学习和通道特征学习分开。
参数个数 = 输入通道数×卷积核尺寸 + 输入通道数×1×1×输出通道数。深度可分离卷积的参数数量一般远小于普通卷积,运算速度更快。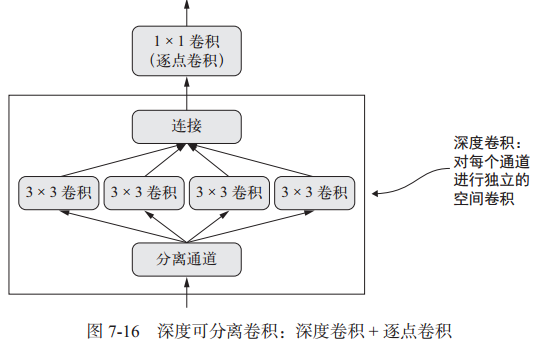
卷积的总结
- 卷积之后输出特征图的每个空间位置都对应输入特征图的相同位置。在Fast R-CNN网络中,从特征图上提取候选框,就是利用了相对空间位置的不变性。
-
卷积与全连接
卷积(convolution)相对于全连接(fully connected):
卷积相当于是全连接中去掉一些权重weight,所以卷积操作中用到的参数变少了,不需要两两之间都做连接。CNN就是DNN,卷积的本质是对全连接进行了剪枝。
- 【权值共享】卷积操作中,权重weight是共享的,这也使得用到的参数变少了。
2.2 池化(e.g. Max pooling)
- 池化有最大值池化、均值池化。
- 池化一般使用不相交池化。
池化后得到的图像变得更小了,“图像”的深度(频道channel)不变。
一般,经过卷积和池化后,希望频道越来越多(卷积决定),图像尺寸越来越小(池化决定)。
卷积池化层的个数越多,提取到的形状越复杂。

为什么需要池化?
池化就是下采样,池化的结果是特征图大小变小了,好处有:
- 减少了需要处理的特征图的元素的个数。例如,在最后的全连接层,如果不池化,参数量可能有千万级别或更多,会有过拟合的风险。
缩小了特征图,意味着卷积层的观察窗口覆盖原始输入的比例会越来越大,可以学到原始数据的整体信息,学到模式的空间层次结构,不会错过或淡化重要特征。
Global pooling
Global pooling,包括GlobalAveragePooling、GlobalMaxPooling,Global的意思是池化窗口的大小和整张feature map一样大,如果Feature Map大小为
 ,Global Pooling之后就会变成
,Global Pooling之后就会变成 。
。
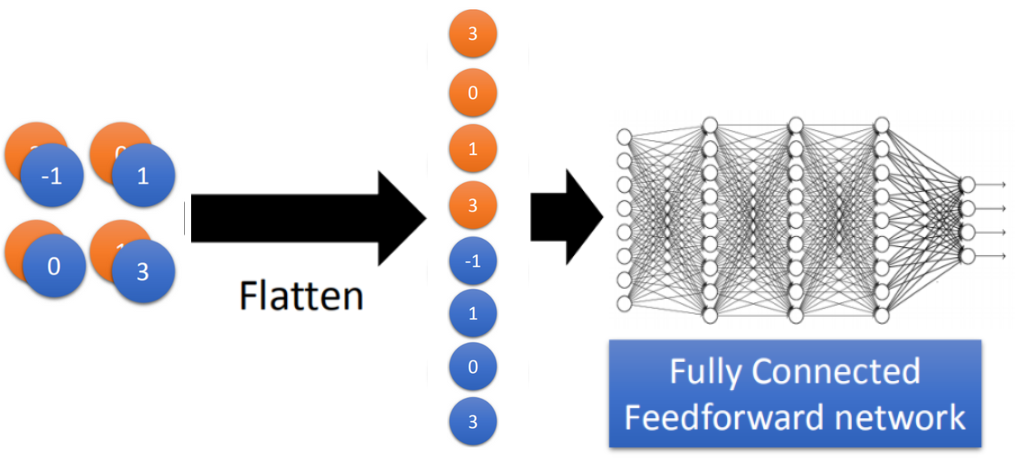
2.3 Flatten
3. CNN网络分析
3.1 Filter分析
以手写数字辨别的任务为例,输入是28x28像素的手写数字图片,输出是0~9十个类别。
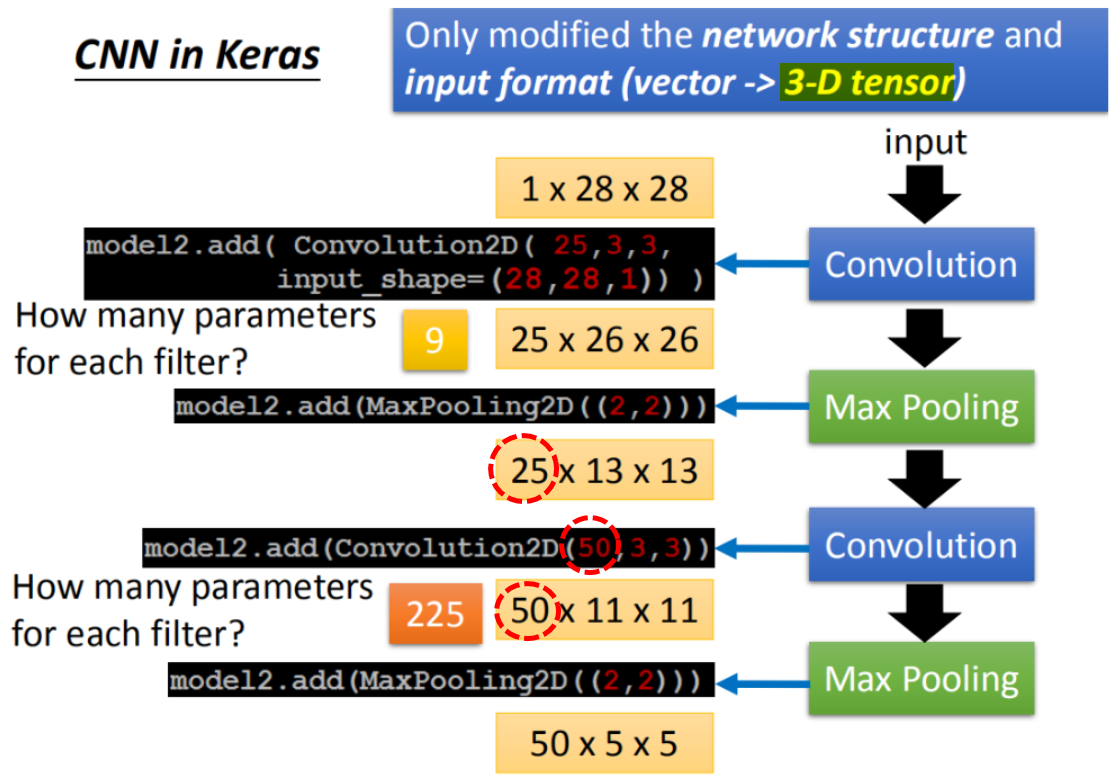
分析每个Filter到底学到了什么。Activation Degree
输入的图像对CNN中第k个Filter的激发程度(activation degree),是指经过该Filter卷积之后的feature map(也就是该Filter的输出output)中各元素加和。
可以将Filter理解为模板,通过模板来检测图像的形状,图像和模板按位相乘,结果相加,结果越大,说明图像和模板越吻合。输出的feature map代表原始图像某位置符合模板的强度。
【问题】我们想要搞清楚第k个Filter的作用是什么?如何来考察?
假设对于输入X,可以使第k个Filter被激发的程度(activation degree)最大。我们以此来考察这个Filter的作用。
现在在这个task里面,model的参数是固定的,我们要让gradient ascent(梯度上升) 去update这个X,可以让这个activation function的Degree of the activation是最大的。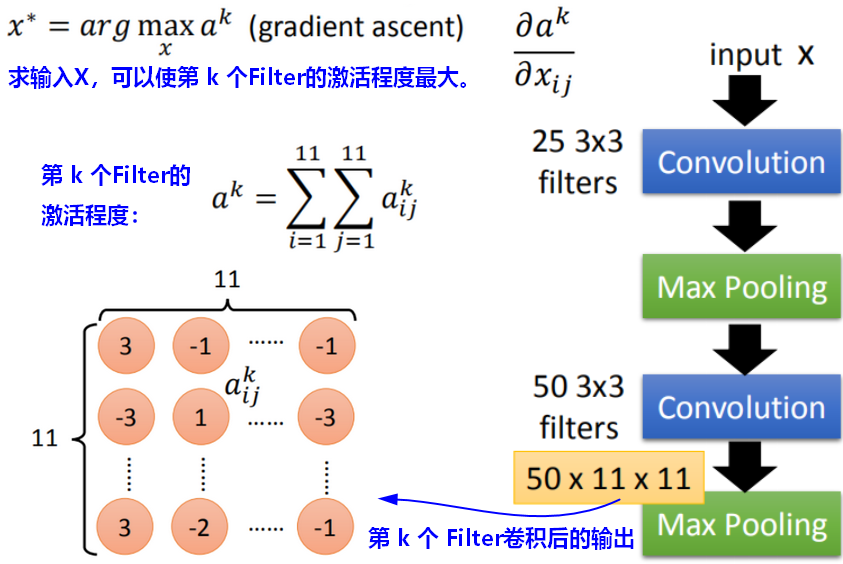
Small region侦测
因为有50个Filter,对应有50个输出output,使用梯度上升后,可以找到50个image(input X)使得对应的Filter的输出最大(被激发的程度最大)。如果图中出现某个pattern,这个小范围就能被Filter侦测出来。卷积过程中,每个Filter只是负责侦测图像中的小范围内的pattern,即small region中的pattern。

模式的空间层级结构
模式的空间具有层次结构(spatial hierarchies of patterns),网络逐层学习,第一个卷积层学习较小的局部模式,第二个卷积层学习由第一层特征组成的更大的模式,以此类推,从局部模式到更大模式,越来越复杂和抽象。
【说明】模型中更靠近底部的层提取的是局部的、高度通用的特征图(如视觉边缘、颜色),更靠近顶部的层提取的是更加抽象的概念(比如“猫耳朵”或“狗眼睛”)。
所以,卷积后的特征图描述了两种信息:第一,通用概念/模式在图像中是否存在;第二,模式的空间位置信息。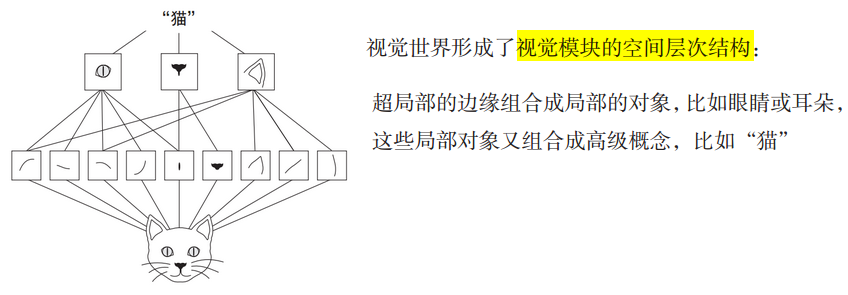
3.2全连接层neuron分析
【问题】在全连接(fully connected)部分,每一个神经元(neuron)的作用是什么?
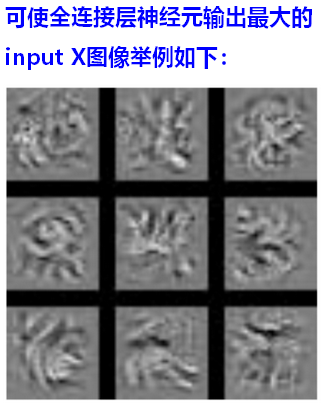
和分析卷积层第k个Filter的功能类似,我们找到全连接层的某个神经元,反推,找出一个输入图像image,可以使得该神经元的输出output最大(被激活)。
此时,全连接层的每个神经元负责一整张图片,而不是图片的一小部分。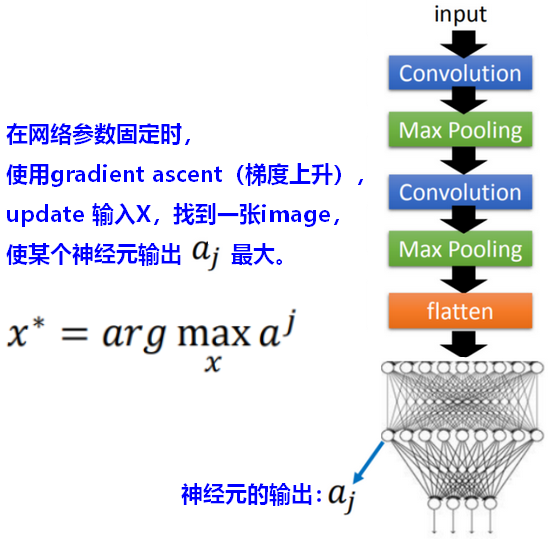
3.3输出分析
类似于Filter功能分析、全连接层neuron分析,在输出分析时(手写数字识别中输出有10维),反推,找到一个输入图像,使得某一维的输出最大。我们期望在找出的图像里有相应的手写数字形状。
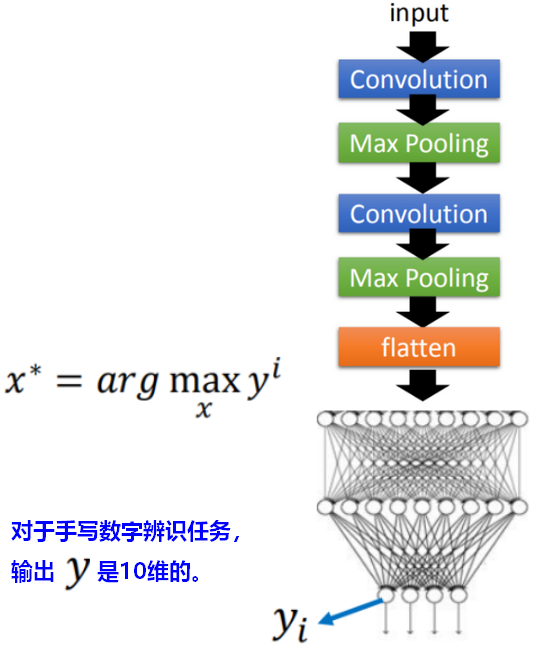
反推找到的输入图像image举例如下:直接按照最大化输出y 求解X,此时image是人类无法辨识的。但输入网络,CNN认为它们就是数字,即CNN网络被欺骗(fooled)了。
- 为了得到期望看到的数字形象,加入约束(constrain)。例如:手写数字只是图片中的小部分,大部分像素(pixel)是空白的,因此,图片所有像素的加和应该尽量小。

3.4 Deep Dream:视觉夸大
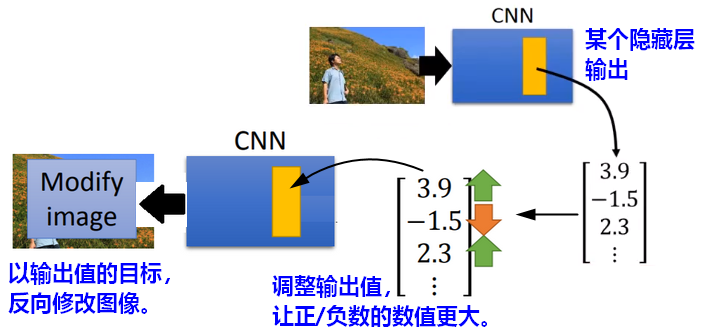
参照Filter分析、全连接层neuron分析和输出分析,当修改某个隐藏层的输出,让它作为学习图像时的目标,反向修改图像后,CNN会夸大自己看到的事物。

3.5 Deep style:风格迁移
风格迁移的目标是明确的,需要寻找/生成一张图片,同时具有和目标的内容(content)相关性以及风格(style)相关性。
所谓相关性/相似度,就是卷积时Filter的输出output是相关的。所以,目标就是找到一张新的image,输入CNN,使得可以同时最大化(maximize)左边和右边的图。
使用梯度上升(gradient ascent)来完成。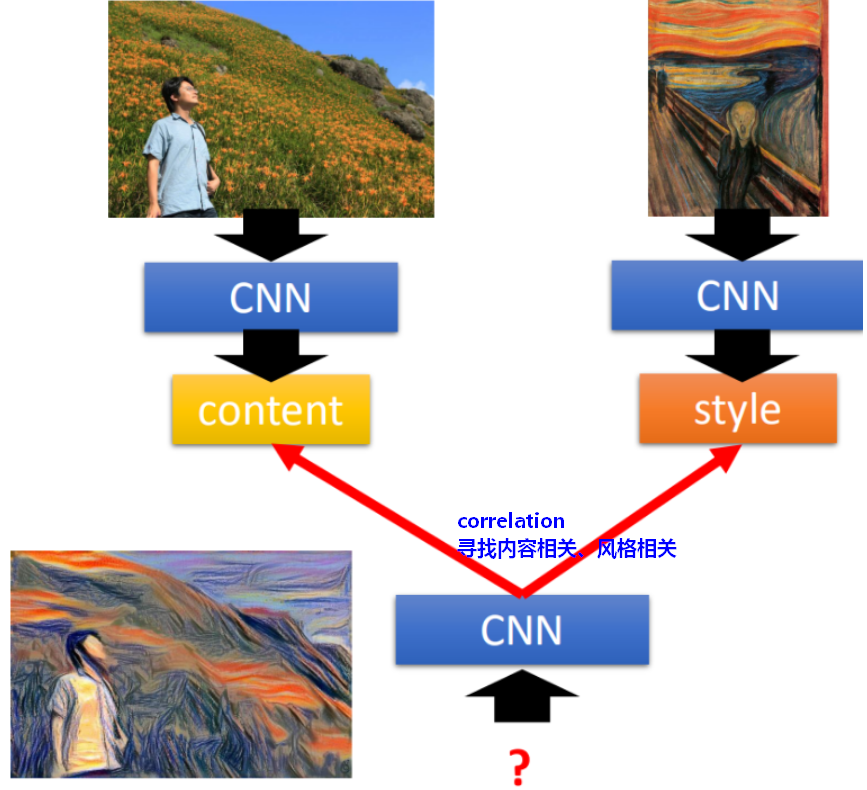
4.CNN应用
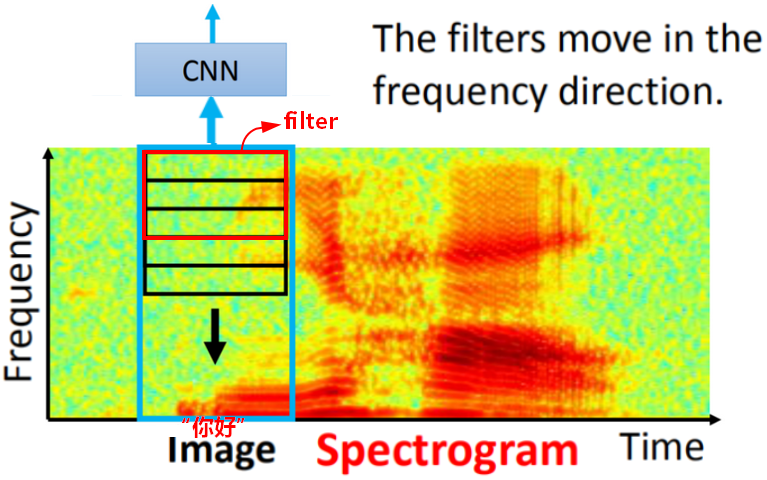
语音识别
- 把语音转成频谱图(spectrogram)
- 频谱图输入CNN,进行语音识别。
- 卷积核Filter是在频率(frequency)方向上移动,例如:男女声在说同样的话时,只是频率上的差别。在时间(time)方向上移动对识别没有什么帮助,RNN等处理时已经考虑时间问题了。
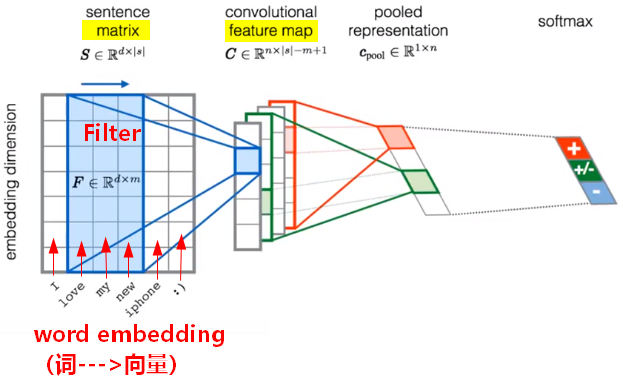
文本处理
- 把文本转为向量(vector)。
- 卷积核Filter是在时间(time)方向上移动。因为embedding方向上是独立的,移动没有意义。
参考来源: 1.李宏毅《机器学习》2017,Spring 2.肖莱《Python深度学习》

若有收获,就点个赞吧
0 人点赞
