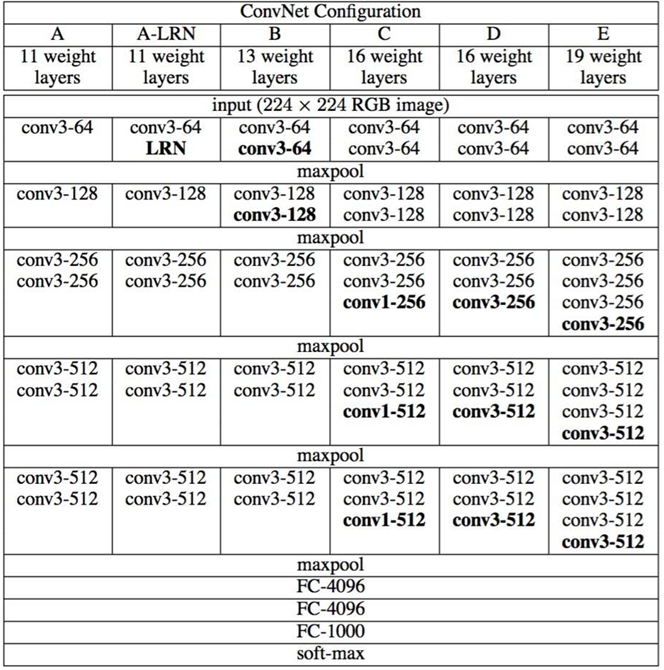
1.VGG16
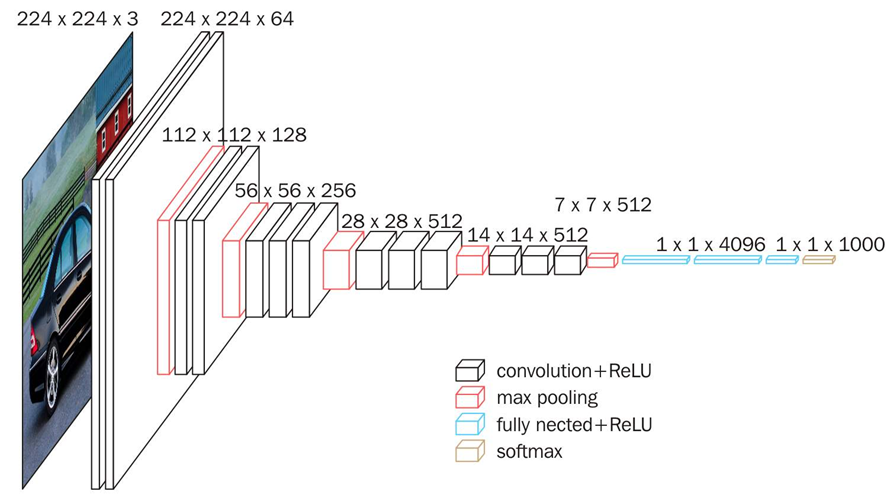
- VGG16中的16是指16个参数/权重层,即卷积层conv的层数+全连接FC的层数=16层。
- VGG16的特点是连续使用了小的卷积核,可以减少W参数,同时增加非线性变化,更小的感受野可以感受更细粒度的特征。
2.Inception
2.1Inception V1
LRN局部响应归一化
局部响应归一化(Local Response Normalization):对输入的局部区域进行归一化。应用LRN的其他网络还有:AlexNet、GoogleNet。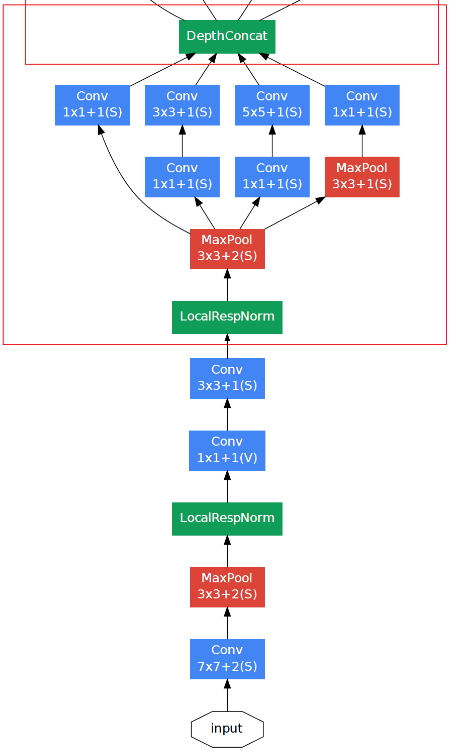
Inception Module模块化
- 同一层并行的使用大小不同的卷积核进行卷积,提取细粒度和粗粒度的特征,通过不同尺寸的卷积核卷积相当于使用了大小不同的感受野,得到低阶/中阶/高阶的特征图(feature map)。
- DepthConcat:在深度/通道上进行堆叠/拼接(concatenate);拼接前,图像的尺寸必须一致,通道数可以不一致。
- 1x1卷积核的作用:升维、降维;不改变面积,只改变通道数;因为DepthConcat拼接之后,通道太多,需要用1x1卷积核降维。1x1+1(S)表示1x1卷积,步长为1,Same模式填充。
1x1卷积也叫逐点卷积(pointwise conv),它有助于区分开通道特征学习和空间特征学习,计算得到的特征能将输入张量通道中的信息混合在一起,但不会将跨空间的信息混合在一起。如果假设每个通道在跨越空间时是高度自相关的,1x1卷积就是合理的。
- NIN(Network In Network):Inception模块本身可看成一个小网络,它嵌入整个大网络中。
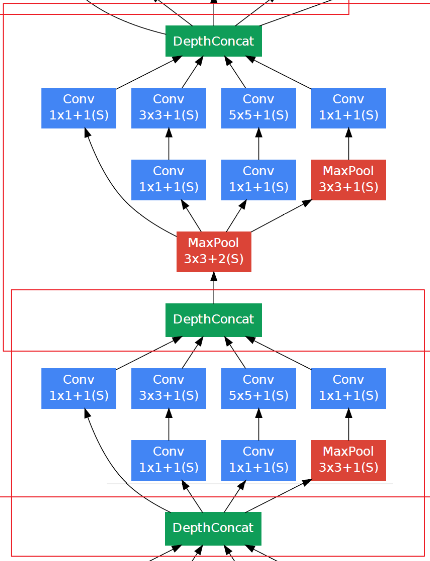
分阶段优化Loss
Inception分阶段求loss,并进行交替训练,以防网络太深出现梯度消失。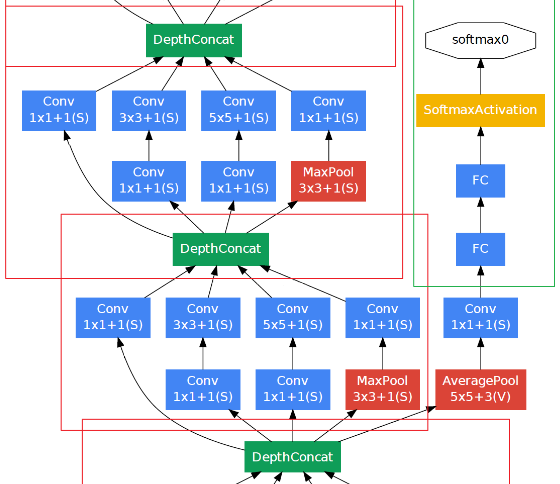
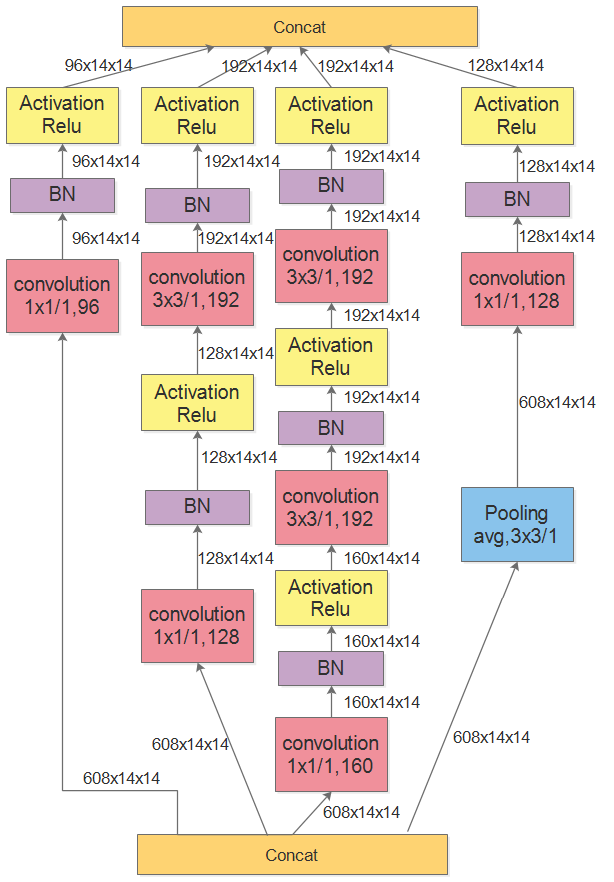
2.2Inception V2:BN
| Inception V1 | Inception V2 | |
|---|---|---|
| 相同 | 都有并行卷积的Inception模块(但V2的模块层数更多); 都有NIN的网络结构。 |
|
| 不同 | 归一化:LRN | 归一化:BN |
| 交替优化多个Loss | 只有一个Loss。(因为使用了BN,解决了梯度消失问题) |
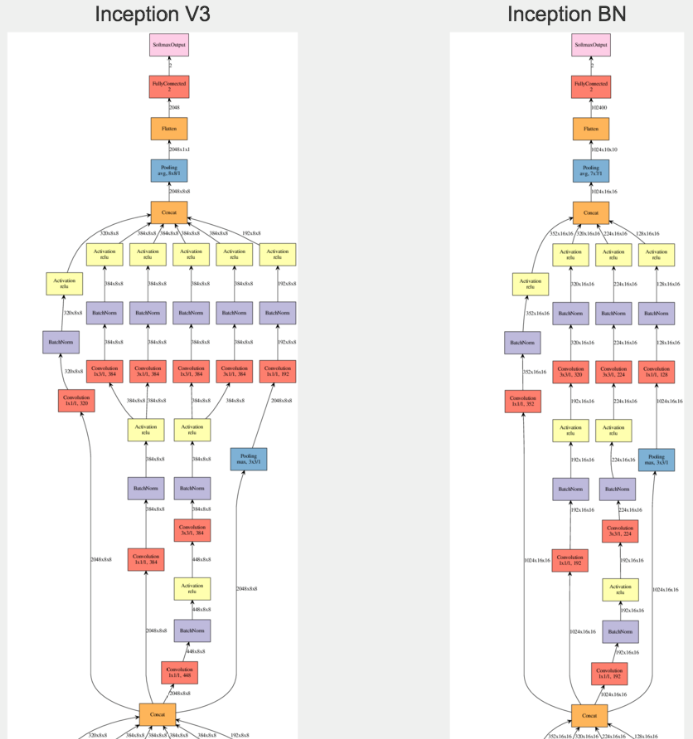
2.3Inception V3:并行化卷积
NININ:多个网络嵌套
在原本的Inception模块中,将3x3的卷积拆分为并列的1x3的卷积和3x1的卷积,或者将7x7的卷积拆分为并列的1x7的卷积和7x1的卷积;减少了一次卷积的参数量;相当于在整体网络中嵌入Inception模块,在Inception模块中嵌入拆分的并行化的卷积。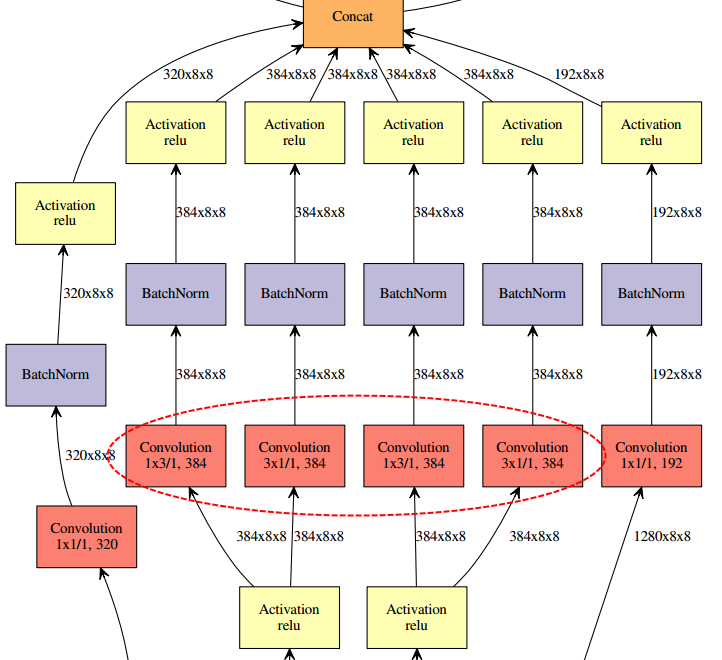
3.ResNet
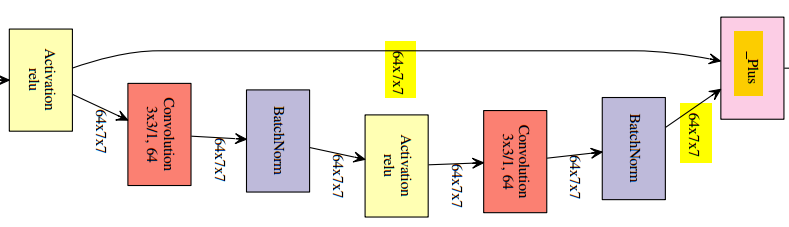
3.1RestNet block
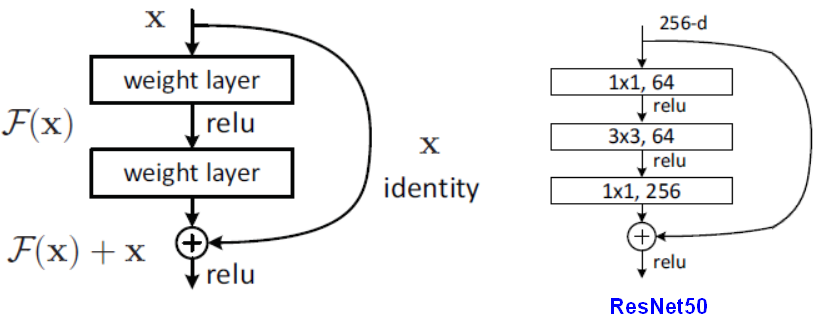
 相当于预测值,
相当于预测值,
 是在拟合残差,相当于是低阶的特征,在ResNet块中,直接把原封不动的和后面某层的输出相加,直觉是低阶的特征也会对最终的预测起作用。
是在拟合残差,相当于是低阶的特征,在ResNet块中,直接把原封不动的和后面某层的输出相加,直觉是低阶的特征也会对最终的预测起作用。
残差连接解决了深度学习模型的两个共性问题:梯度消失和表示瓶颈。
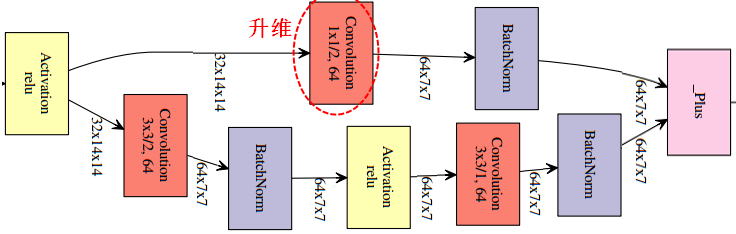
【注意】两个张量直接相加,要求张量的形状一样(恒等残差连接:identity)。相加是逐元素(element-wise)的相加。如果形状不一样,可以用一个线性变换将前面层的激活改变成目标形状(线性残差连接:linear)。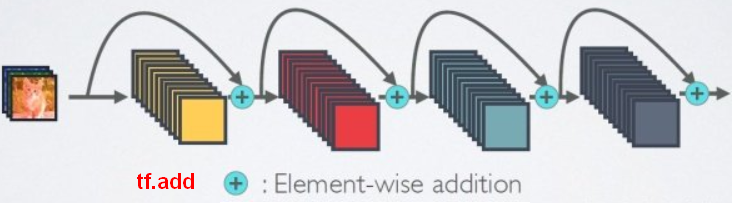
4.DenseNet
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。
Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。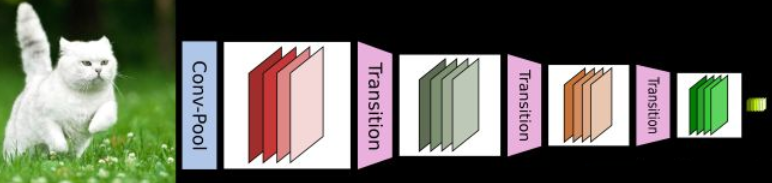
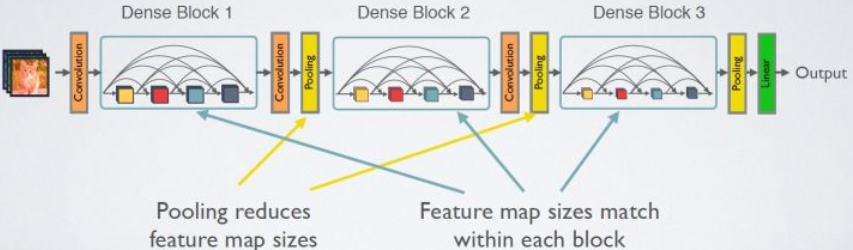
4.1Dense block
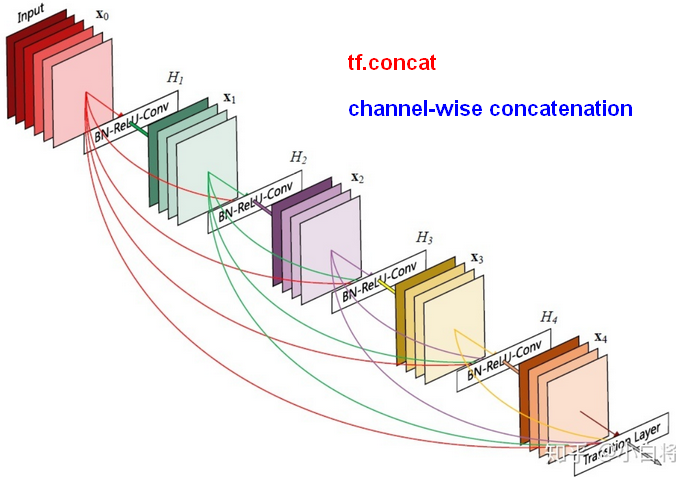
- 在DenseBlock中,每个层都会与前面所有层在channel维度上连接(concat)在一起(各个层的特征图大小是相同的),并作为下一层的输入;拼接意味着融合了低阶高阶的特征。
- 对于一个
 层的网络,DenseNet一共包括
层的网络,DenseNet一共包括 个连接(concat)。网络在第
个连接(concat)。网络在第 层的输出会连接前面的所有层作为输入:
层的输出会连接前面的所有层作为输入: 。
。 是非线性转化函数,是一个组合操作,可能包括一系列的BN,Relu,Pooling和Conv。
是非线性转化函数,是一个组合操作,可能包括一系列的BN,Relu,Pooling和Conv。
【问题】为什么DenseNet网络可以更深了?
梯度可以沿着路径传递到更前面的层,不用通过链式求导一层层的向前传播,消除了梯度消失的影响。
5.模型压缩
- 减少w参数个数:例如,把数值接近0的参数直接设置为0,再进行fine-tuning,为0的参数就不再存储了。
- 减少w参数浮点数的位数,使其更少的占用空间。

若有收获,就点个赞吧
0 人点赞
