一、概率模型
0.概率模型VS非概率模型
| 概率模型 | 非概率模型 |
|---|---|
| 取条件概率的分布形式: 在监督学习中为P(y|x),x输入,y输出; 在非监督学习中为P(z|x),P(x|z),x输入,z输出 |
取函数形式: 在监督学习中为y=f(x); 在非监督学习中为z=g(x) |
| 在监督学习中, 概率模型是生成模型。 |
在监督学习中, 非概率模型是判别模型。 |
| 1.条件概率分布和函数可以相互转化: 条件概率分布最大化后可得函数; 函数归一化后可得条件概率分布。 2.概率模型和非概率模型的区别: 不在于输入到输出的映射,而在于模型内部结构。 概率模型一定可以表示为联合概率分布的形式;而非概率模型则不一定。 |
基本概率公式
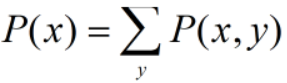
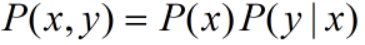
1.概率模型建模三步走
1.1模型:定义函数集
使用贝叶斯公式定义分类模型:P(C1|x)表示样本x属于C1类别的概率。
1.2策略:定义最好的函数
针对生成观测数据的可能性概率,利用最大似然估计,计算均值和协方差矩阵。
(协方差矩阵是和输入feature大小的平方成正比,所以当feature很大的时候,协方差矩阵是可以增长很快的。此时考虑到model参数过多,容易Overfitting)
1.3算法:求解参数,找出最好的函数
2.概率模型的实现
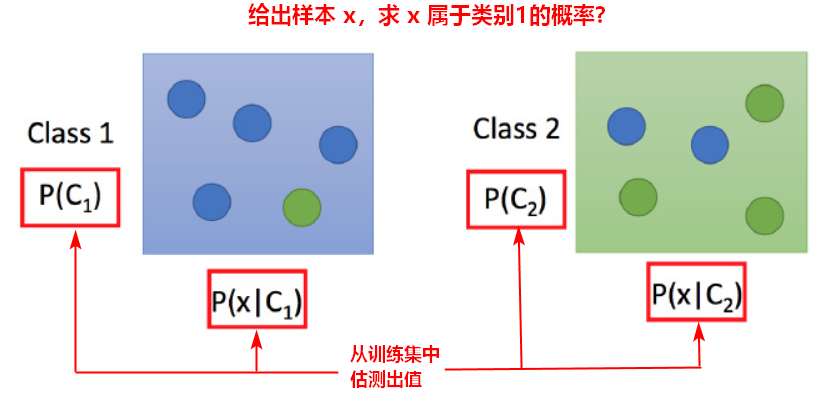
2.1生成模型(Generative model)

通过从训练集中估测 P(C1)、P(x|C1)、P(C2)、P(x|C2),得到一个分类模型,就可以计算出 x 属于哪一个类别,这个模型叫生成模型(Generative model)。
2.2最大似然估计
例如:训练集中有79个样本属于C1类别,61个样本属于C2类别,则:
P(C1)=79/(79+61), P(C2)=61/(79+61)。 如何估算 P(x|C1)、P(x|C2)?
【假设】各特征维度的分布服从正态分布(高斯分布)。那么,如何计算某类样本的μ和∑ ?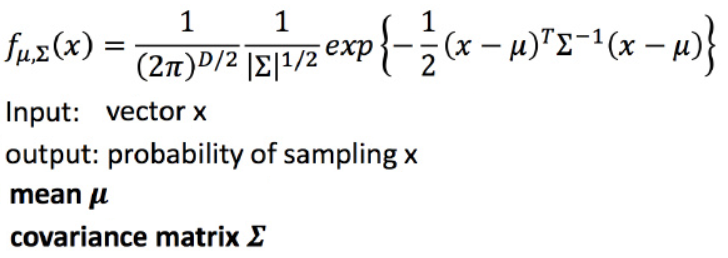
对于C1类别中的79个样本,需要找到一组参数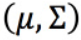 ,使得生成这些样本点的概率最大。样本的似然函数为:
,使得生成这些样本点的概率最大。样本的似然函数为:
2.3分类效果
根据最大似然估计,估算每个类别的样本各自的μ和∑,代入到生成模型中进行分类,效果并不好。
【问题】因为协方差矩阵∑是和输入feature大小的平方成正比,当feature很大的时候,协方差矩阵是可以增长很快的。此时考虑到model参数过多,容易Overfitting。
【优化】为了有效减少参数,给描述这两个类别的高斯分布相同的协方差矩阵。此时可以改善分类效果。
3.后验概率-逻辑回归
逻辑回归的输出就是用来估算后验概率(Posterior Probability)。
x是特征,C为标签,训练集其实不足以覆盖到维度x的所有可能取值,因此不能用频率去估计概率,因为未观测到的x,不等于它出现的概率为0。所以假设x满足某种特定的概率分布形式(例如:高斯分布),这种分布形式由参数θ确定,所以通过已有训练集估计出参数θ,也就能计算出后验概率。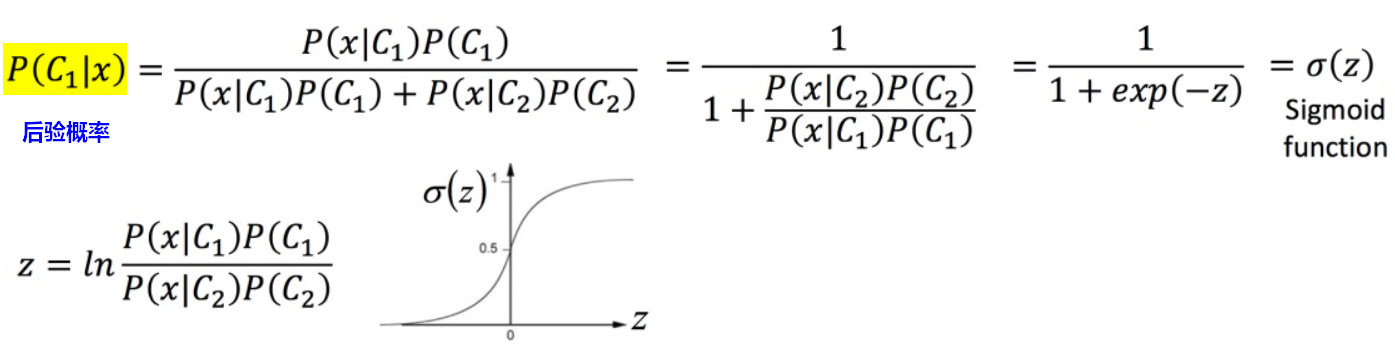
【假设】各特征维度的分布服从正态分布(高斯分布)

通过训练集数据,估算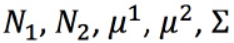 ,就可以求出 w,b。
,就可以求出 w,b。
3.1判别模型VS生成模型

判别模型的分类效果有可能要更好: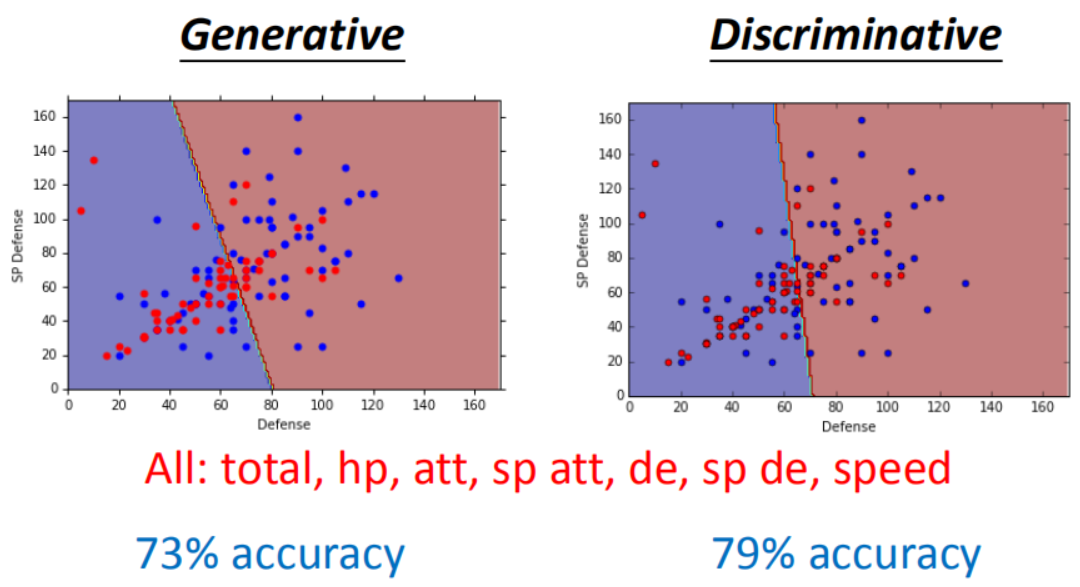
生成模型的优势:
- 判别方法没有做任何假设,就是看着训练集来计算,训练集数量越来越大的时候,error会越小。
- 生成方法有一些假设,会自己“脑补”先验概率(先验和类相关的概率可以从不同的来源估计),受到数据量的影响比较小。 对于噪声数据有更好的鲁棒性(robust)。适合于训练数据量很小的情况。(例如:语音识别是生成方法,需要算一个先验概率,就是某句话被说出来的概率,而估计某句话被说出来的概率不需要声音数据,只需要爬很多的句子,就能计算某句话出现的几率。)
二、朴素贝叶斯
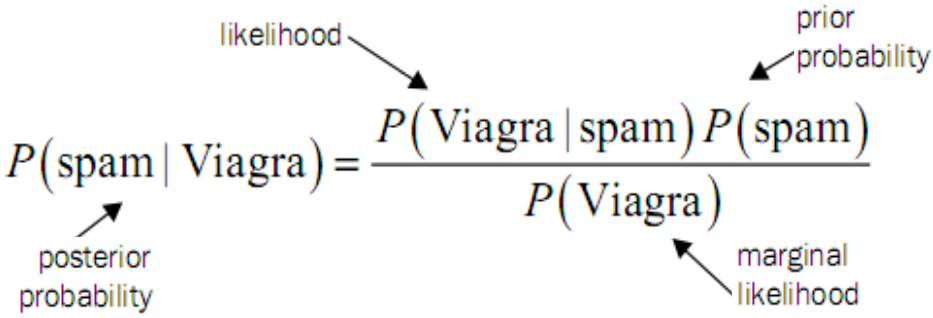
1.贝叶斯公式
2.朴素贝叶斯
朴素的定义:独立
用频率估算概率,可得:

【问题】用频率估计(似然)概率存在什么问题?
根据贝叶斯定理: ,
, 为给定的样本(向量),
为给定的样本(向量), 为类标记,
为类标记, 是类先验概率,
是类先验概率, 被称为似然或类条件概率。
被称为似然或类条件概率。
证据因子 和类标记无关,所以估计
和类标记无关,所以估计 的问题就转化为估计先验和似然的问题。类先验概率可以根据大数定律通过各类样本出现的频率来估计,类条件概率涉及样本所有属性的联合概率,很多样本取值在训练集中根本没有出现,因此仅根据频率估计概率是不准确的,“未被观测到的”不等同于“出现概率为0”。
的问题就转化为估计先验和似然的问题。类先验概率可以根据大数定律通过各类样本出现的频率来估计,类条件概率涉及样本所有属性的联合概率,很多样本取值在训练集中根本没有出现,因此仅根据频率估计概率是不准确的,“未被观测到的”不等同于“出现概率为0”。
另外,基于有限训练样本直接估计联合概率,计算上会有组合爆炸的问题,数据上会有样本稀疏的问题,属性越多,问题越严重。
所以朴素贝叶斯分类器中,“朴素”就是假设所有属性相互独立,即每个属性独立的对分类结果发生影响。基于属性条件独立性假设,有 ,d为属性数目,
,d为属性数目, 是在第j个属性上的取值。
是在第j个属性上的取值。
例如:对于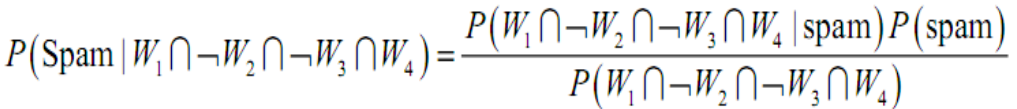 ,
,
有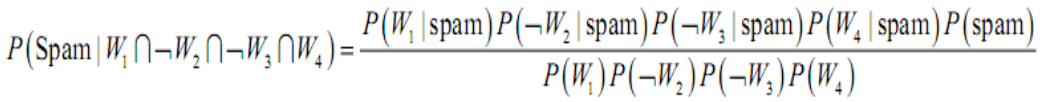
【注意:】连乘形式 可能会造成数值下溢,实践中通过取对数的方式将“连乘”转为“连加”形式。
可能会造成数值下溢,实践中通过取对数的方式将“连乘”转为“连加”形式。
样本x属于C1类别的概率P(C1|x),假设所有的feature都是相互独立产生的,这种分类叫做 Naive Bayes Classifier(朴素贝叶斯分类器)。(区别于用高斯分布来描述后验概率的计算方式)
可以认为每个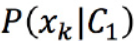 产生的概率符合一维的高斯分布。朴素贝叶斯分类器相当于将各个特征项之间解耦。
产生的概率符合一维的高斯分布。朴素贝叶斯分类器相当于将各个特征项之间解耦。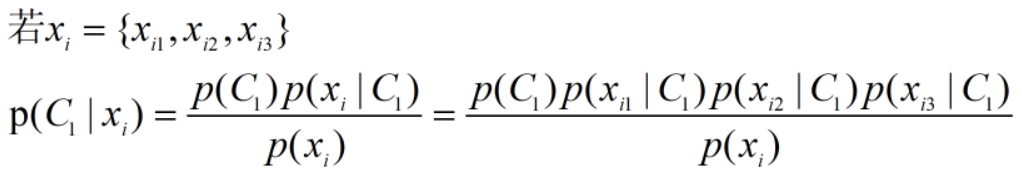
朴素贝叶斯分类器
假设有N种类别标记, ,
,
朴素贝叶斯分类器的表达式为: ,
,
即对每个样本,选择能使后验概率最大的类别标记。
对于离散属性, ,其中
,其中 为训练集中第c类样本组成的集合,
为训练集中第c类样本组成的集合, 是
是 中在第i个属性上取值为
中在第i个属性上取值为 的样本组成的集合。
的样本组成的集合。
对于连续属性,可以假设服从某种概率分布形式,例如:正态分布,,其中分别是第c类样本在第i个属性上取值的均值和方差。
拉普拉斯修正:平滑
如果某个属性值在训练集中没有与某个类别同时出现过,则 ,概率估计就会出问题,此时应该有更“平滑”的估计,使用拉普拉斯修正/拉普拉斯估计,保证每一类中每个特征发生概率非零。
,概率估计就会出问题,此时应该有更“平滑”的估计,使用拉普拉斯修正/拉普拉斯估计,保证每一类中每个特征发生概率非零。 ,其中
,其中 表示第i个属性可能的取值数;
表示第i个属性可能的取值数; ,其中
,其中 表示训练集中可能的类别数。
表示训练集中可能的类别数。
实践中的问题
- 【问题】朴素贝叶斯的应用不是太广,因为它“粗暴”的认为各个特征间是独立的,实际中,各个特征项很多是有关联的。
- 可以把贝叶斯分类器涉及的所有概率估值预先计算好并存储起来,在预测时只需要“查表”。
来源: 1.《机器学习》周志华;第7章 贝叶斯分类器。 2.《机器学习》台湾大学-李宏毅。

若有收获,就点个赞吧
0 人点赞
