机器学习的最终目的是获得不断学习和改进的数据模型。
模型是对数据的一种总结。
1.模型构建model building
- 关注数据本身:
数据类型、建模数据在特定数据集中的表现。
如何描述数据?
中心测量方法:描述分布中心的情况,例如 众数、平均数、中位数。
- 众数mode:出现频率较高的一个或多个数/范围。
均匀分布uniform distribution,它没有众数。
双峰分布bi-modal distribution,它有两个众数。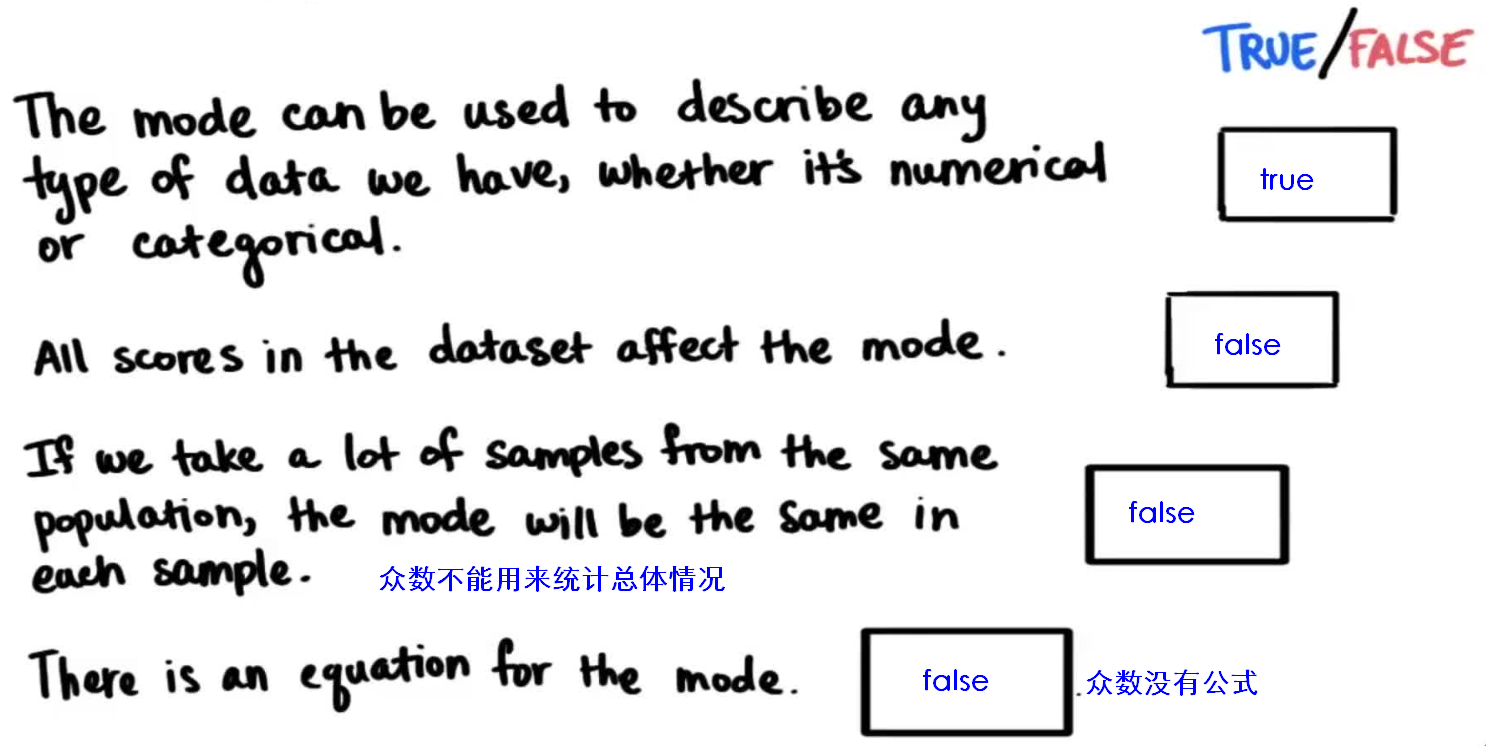
- 均值mean/average
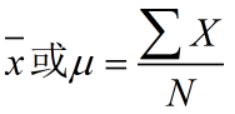 sigma是大写的希腊字母s,代表sum。
sigma是大写的希腊字母s,代表sum。
数据中的异常值outlier会将平均值拉向异常值方向,造成偏斜分布。
众数不受异常值的影响,但难以用来统计总体情况。
- 中位数median:数据的中间值。
中位数能很好的反映高偏斜分布(highly skewed distribution)中的集中情况。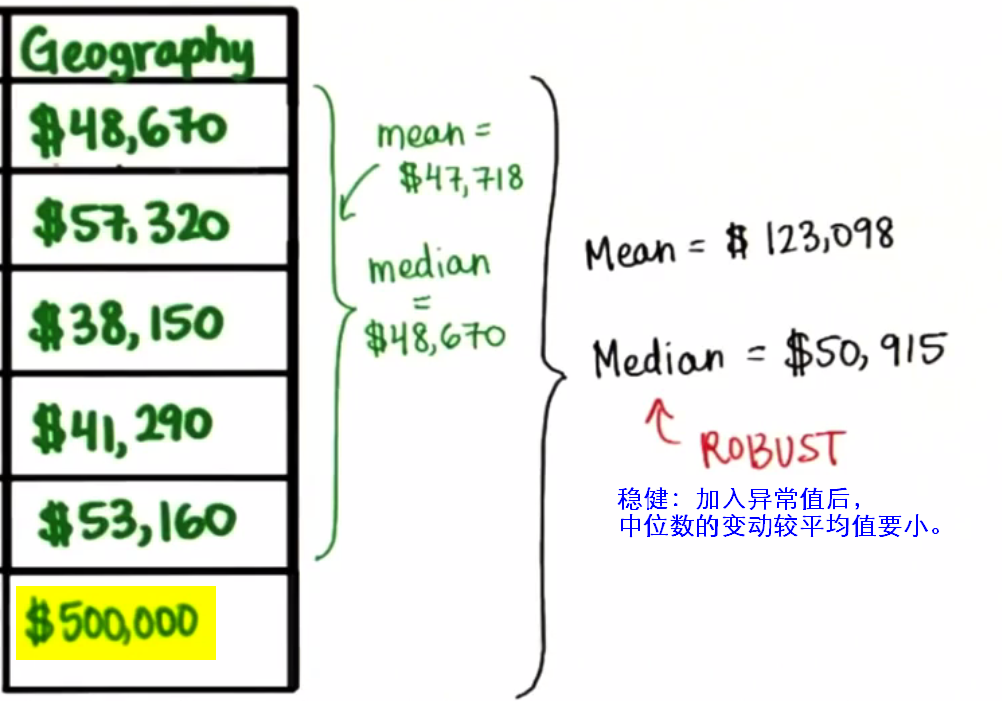

异常值的定义:
四分位数的计算:
简单箱线图: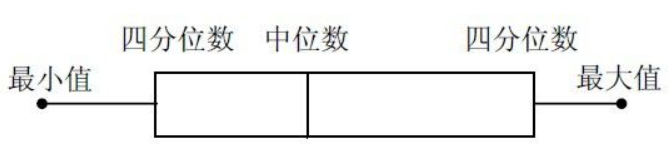
-
2.验证组件validation component
2.1信息泄露(information leak)
基于模型在验证集上的性能来调节超参数,就会有一些关于验证数据的信息泄漏到模型中。如果泄漏过多,就会在验证集上过拟合,即使没有直接在验证集上训练模型也会如此。
也不能基于测试集来调整模型,同样有信息泄露问题。2.1简单留出验证(hold-out validation)
为了防止信息泄露,需要在训练集和测试集之外,保留一个验证集,定义验证集之前通常需要打乱数据(shuffle)。
使用训练集训练模型,在验证集上评估模型(evaluate)。根据评估情况,调节参数;一旦调好参数,就在所有非测试数据上重新训练最终模型。
【问题】留出验证存在以下问题: 当可用数据较少时,验证集和测试集样本就少,无法从统计学上代表数据;
- 划分验证集前进行不同的随机打乱,得到模型的性能差异性很大。
2.3K折交叉验证(K-fold validation)
当训练集数据较少时,验证集也会非常小,验证分数会有很大波动,即验证集的划分方式可能会造成验证分数有很大的方差。这时,可以使用K折交叉验证:
训练K个模型,每个模型在(K-1)个分区上训练,在剩下一个分区上评估,验证分数是K个验证分数的平均值。
根据K折验证的评估,可以选定最佳的参数,使用这些参数在所有训练数据上训练最终的生产模型,然后在测试集上测试性能。
2.4重复K折验证(iterated K-fold validation with shuffling)
多次使用K折验证,每次将数据划分为K个分区前,都先将数据打乱,最终分数是每次K折验证分数的平均值。
【问题】假设重复P次使用K折验证,则最终一共要训练和评估PxK个模型,计算代价较大。
3.模型评估
- 自身的评估
利用模型进行预测的效果。
添加更多数据或增加模型的复杂度,和预测结果之间的关系。
- 横向评估
3.1评估的注意事项
- 数据代表性。训练集和测试集都应该可以代表当前数据,在划分训练集和测试集之前,应该先打乱数据。想要让模型具有什么样的功能,就应该“喂给”模型什么样的数据。
- 时间箭头(the arrow of time)。对于时序数据,划分数据前不应该随机打乱数据,否则会造成时间泄露(temporal leak);测试集的数据在时间上都应该晚于训练集数据。
- 数据冗余(redundancy)。如果数据中有冗余数据,随机打乱,可能导致训练集、验证集、测试集上有重复数据,评估结果会不准。应该保证训练集、验证集、测试集之间没有交集。
3.2mAP(mean Average Precision)
平均精度均值(mAP)是精度均值(AP)的平均值。
假设当边界框对应的IoU大于某个阈值(e.g.IoU>0.5),就认为这个预测的边界框是对的(TP);如果IoU小于阈值,则预测的边界框就是错的(FP)。如果对于图像中某个物体来说,模型没有预测出对应的边界框,那么这种情况就可以被记为一次FN。
进而计算出精确率和召回率:
并且通过调整IoU的阈值,可以画出模型对于每个物体类别的PR曲线。
通过PR曲线,可以得到PR曲线对应的AP值。
- 在2010年以前,PASCAL VOC竞赛中AP是这么定义的:对于一条AP曲线,我们把recall的值从0到1划分为11份:0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0。在每个recall区间(0-0.1, 0.1-0.2,0.2-0.3,…,0.9-1.0)上我们计算精确率的最大值,然后再计算这些精确率最大值的总和并平均,就是AP值。这种方法叫做11-poinst-interpolation。
- 从2010年之后,PASCAL VOC竞赛把这11份recall点换成了PR曲线中的所有recall数据点。这种方法叫做all-points-interpolation。这个AP值也就是PR曲线下的面积值。
假设在测试集中一共有K个类别的目标物体,先算出模型对于每个类别的物体的AP值,再将所有类别的AP值相加在一起再除以所有类别的数量K,就得到最终模型的mAP。
(理解:Average是对不同阈值下对应的不同Precision而言,mean是对不同的类别而言。)

若有收获,就点个赞吧
0 人点赞
