1.FCN

语义分割将属于同一类的不同实例都用一种颜色标出。
实例分割将属于同一类的不同实例用不同的颜色标明。
1.1FCN-语义分割
代表论文:Fully Convolutional Networks for Semantic Segmentation(语义分割:分割出类别,但分不出实例)。
FCN对图像进行像素级的分类,目标是将每个像素(pixel)分类为一组固定的类别,但并不需要区分物体实例(object instance)。
1.1.1FCN与CNN
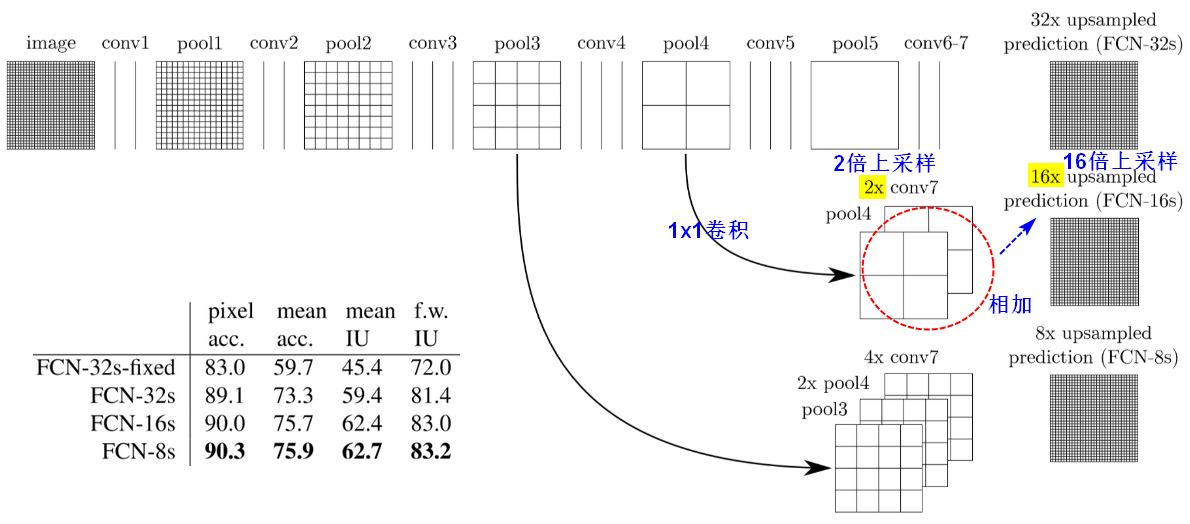
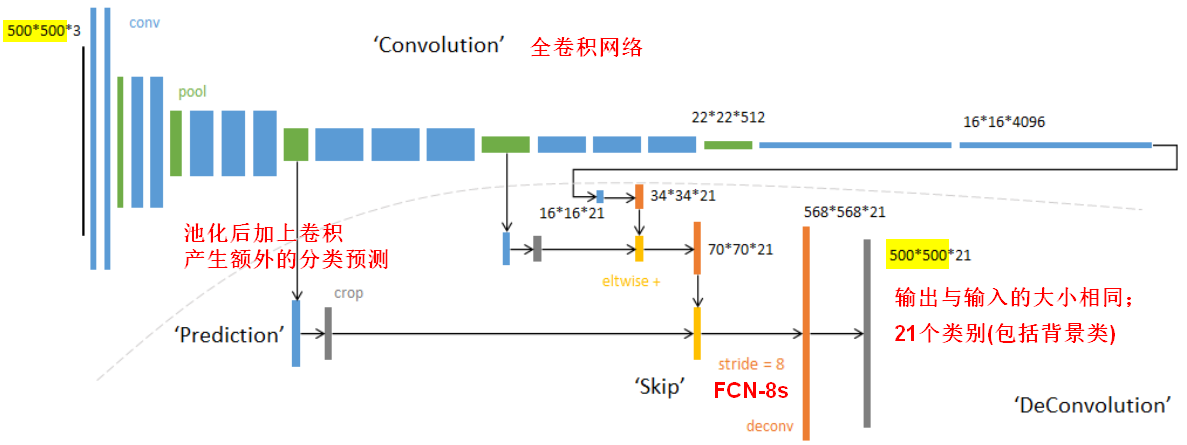
- FCN将传统CNN中的全连接层转化成卷积层,而经典的CNN在卷积层使用全连接层得到固定长度的特征向量。(全卷积输出的结果heatmap大小与原始图像相比小了很多,所以这个时候需要解决 “下采样” 引出的问题,使用上采样)
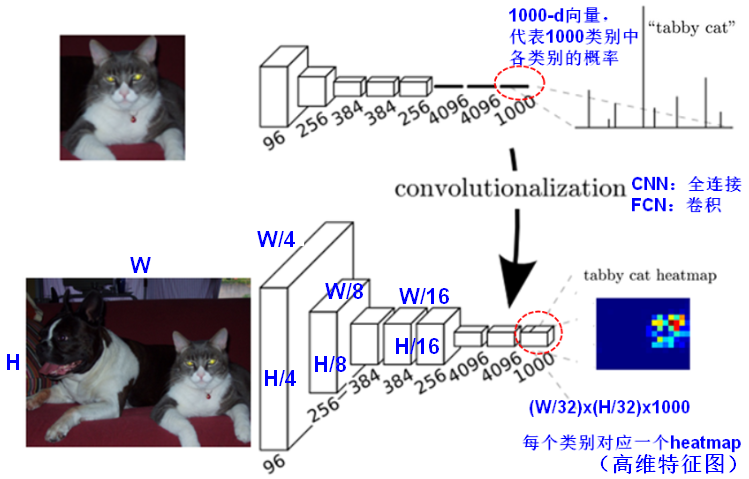
- FCN可以接受任意尺寸的输入图像,采用反卷积层(deconvolution/conv_transpose)对最后一个卷积层的feature map进行上采样(upsampling), 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
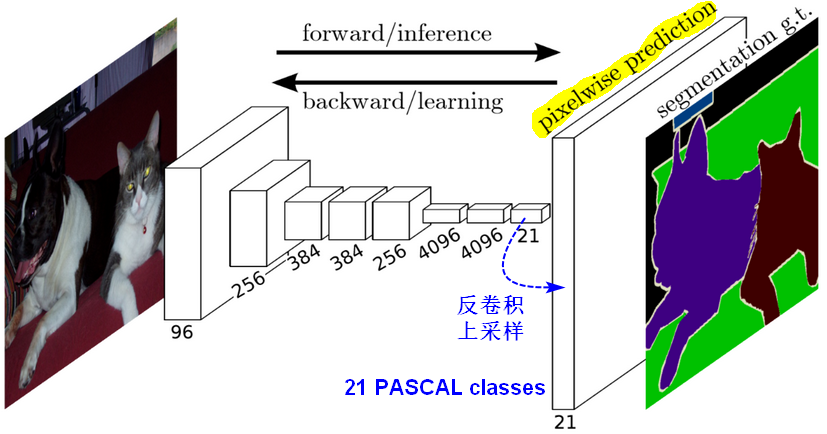
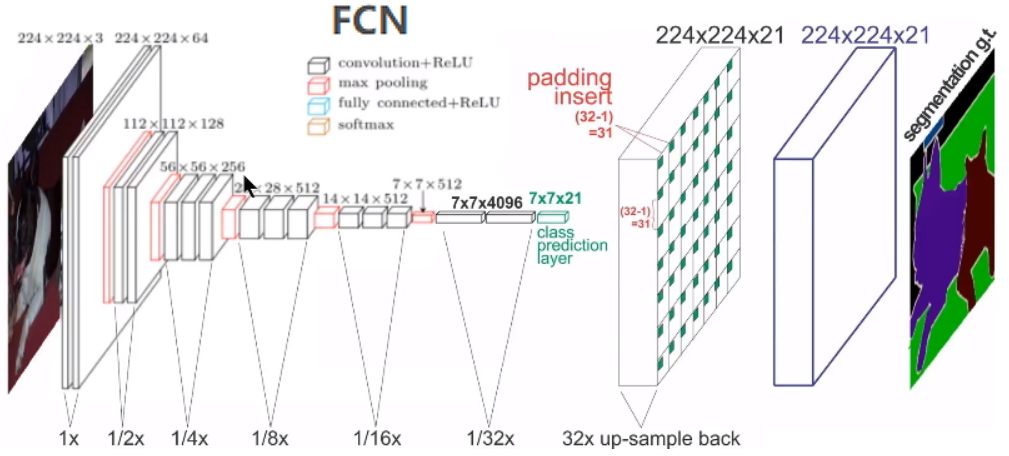
1.1.2跳跃结构(Skip Architecture)
在FCN中上采样(upsampling)的时使用双线性插值。
插值(interpolation):在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点。插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值。图像处理中,插值用来填充图像变换时像素之间的空隙。根据若干离散的数据数据,得到一个连续的函数(也就是曲线)或者更加密集的离散方程与已知数据相吻合。这个过程叫做拟合。內插/插值是曲线必须通过已知点的拟合。
线性插值(Linear interpolation):线性插值是指插值函数为一次多项式的插值方式,其在插值节点上的插值误差为零。线性插值的几何意义即为利用过A点和B点的直线来近似表示原函数。
双线性插值(Bilinear interpolation):双线性插值又称为双线性内插,其核心思想是在两个方向分别进行一次线性插值。双线性插值的结果与先进行哪个方向的插值无关。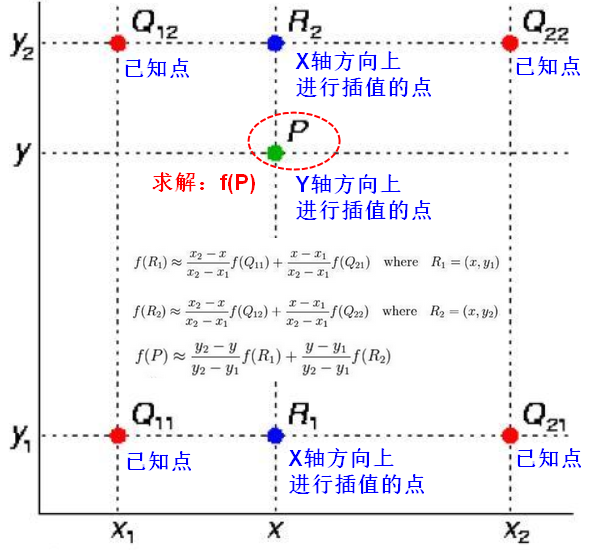
1.2FCN-实例分割
代表论文:Instance-sensitive Fully Convolutional Networks(实例分割),作者提出instance-sensitive score maps, 每个feature map识别一个instance的相对位置。
FCN可以用来做segmentation, 做法是把这个分割问题看成是per-pixel的classification问题,但是这种做法无法做instance segmentation。如果需要做Instance Segmentation,就需要像素针对不同的Instance有不同的响应。虽然不同instance之间有相邻部分,但是相邻部分在不同的instance里处于不同的位置,响应也不同。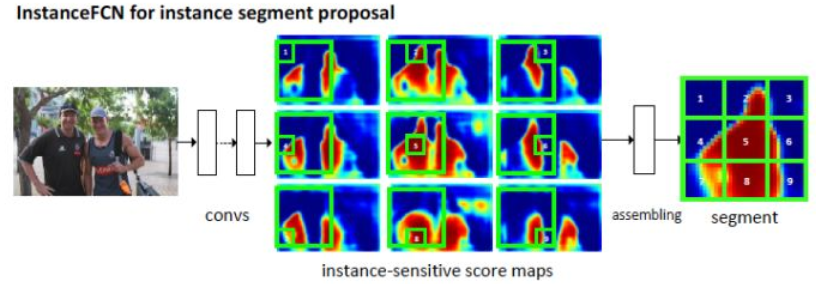
1.2.1FCN与InstanceFCN
在传统的FCN中,每个图像生成一个score map,每个像素的值表示该像素是否属于目标的概率。
在InstanceFCN中,会生成 个score maps,每个像素的值表示该像素是否属于某一类的某个相对位置的概率。
个score maps,每个像素的值表示该像素是否属于某一类的某个相对位置的概率。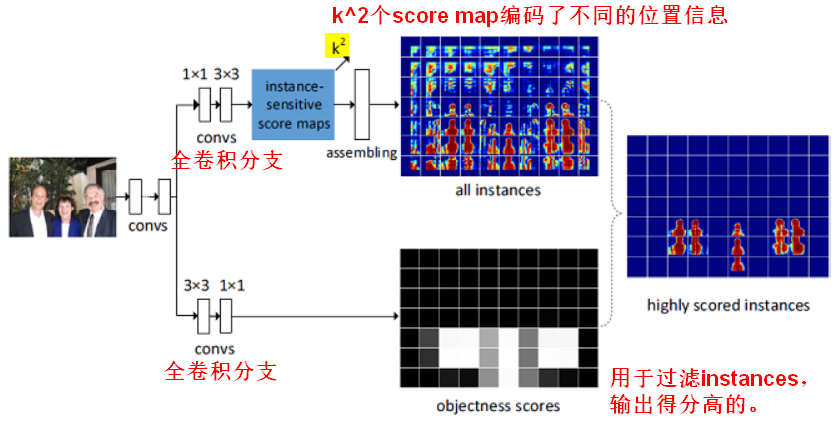
2.R-FCN
R-FCN:Region-based Fully Convolutional Network基于区域的全卷积网络。
R-FCN是Faster R-CNN的改进版,比 Faster R-CNN 快了 2.5 到 20 倍,精度从 Faster R-CNN 在 PASCAL VOC 2007 上的 69.9% mAP 提升到了 83.6% mAP。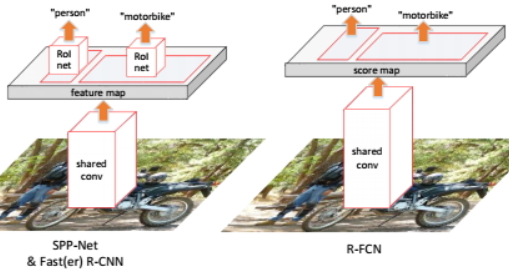
2.1问题及改进
平移不变/可变性问题
在传统的卷积神经网络中,因为过度使用池化层(包含最大池化层 max pooling layer 和平均池化层 average pooling layer),导致在进行图像分类任务时,网络“平移不变性”(translation-invariance)性能提升,但是在目标检测的时候我们需要的是“平移可变性”(translation-variance),即需要对位置敏感(position sensitive),因此这两个方面构成了一个矛盾困境(dilemma)。
共享计算问题
2016年流行的网络架构是在卷积网络后面接一个空间池化层(spatial pooling layer),然后再接几层全连接层。卷积计算进行特征提取时共享计算,但是在兴趣区域池化(RoI pooling layer)时不共享计算。后来提出全卷积网络(fully convolutional network),删掉了兴趣池化层,发现当它用于分类任务上效果很好,而当把它直接应用于检测任务上时精度很差。
为了解决这个问题,Faster R-CNN 等算法在使用像 ResNet,GoogLeNet 等全卷积网络时,开始在一些卷积层间很不自然地插入一些兴趣区域池化层,RoI池化是一个区域相关(region-specific)的操作,因此可以提高检测精度,但是由于兴趣区域池化不共享计算,所以网络的整体速度有所下降。
(理解:共享卷积,是指共享卷积网络之后生成的feature map,一张图片只需要一次卷积操作)
为了解决这个矛盾,R-FCN 专门对位置信息进行了编码,在传统的全卷积层后额外地输出一个对位置敏感的得分图(position-sensitive score map),从而既保持了整个框架全卷积的结构,又实现了“平移可变性”。在整个全卷积网络的顶部,R-FCN 加上了对位置敏感的兴趣池化层(position-sensitive RoI pooling layer),用来强调位置敏感性。这样一来,整个全卷积层既能共享计算,又能对位置进行编码。
Faster R-CNN中的RoI Pooling之后,会接几个卷积层和全连接层,这些层作用在每个RoI上,存在重复计算。在R-FCN中,所有能共享的层都在ROI Pooling之前做好了,再引入position-sensitive score map和position-sensitive ROI Pooling,使得经过Pooling后简单地执行一些操作就能得到回归和分类结果,而不再像Faster RCNN一样用几个全连接层去得到结果。
2.2网络结构
R-FCN:ResNet、RPN、position-sensitive score map、position-sensitive RoI Pooling。
网络主要是基于ResNet-101(100个卷积层、1个均值降采样层),RestNet-101最后的卷积层输出是2048维,为了降维,在其后添加了 的卷积层;添加一个
的卷积层;添加一个 维的卷积层用于生成score maps(保存了目标的空间位置信息)。
维的卷积层用于生成score maps(保存了目标的空间位置信息)。
score maps主要是用来生成object的类别,该层和bounding box regression是并列的。主网络以外,RPN网络用于生成ROI,生成的ROI和分类的卷积层生成的score maps进行position-sensitive ROI Pooling得到形状为 -d的position-sensitive scores,vote(均值操作)之后得到每个ROI属于每个类别的概率(一共C+1类);ROI还将和回归卷积层的输出进行pooling,得到每个ROI的四个坐标。
-d的position-sensitive scores,vote(均值操作)之后得到每个ROI属于每个类别的概率(一共C+1类);ROI还将和回归卷积层的输出进行pooling,得到每个ROI的四个坐标。
ROI Pooling层后面不再跟卷积层或全连接层,这样整个网络不仅可以end-to-end训练,而且所有层的计算都是在整个图像上共享的。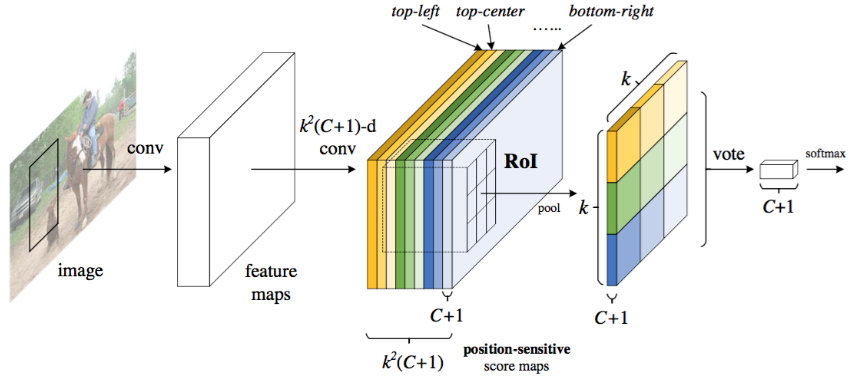
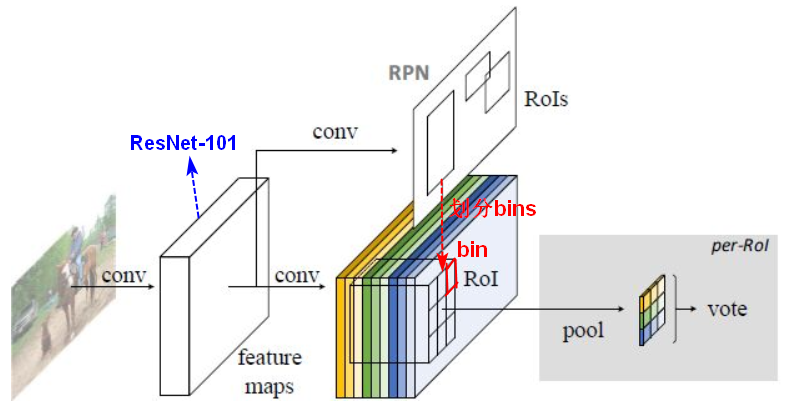
2.3position-sensitive RoI Pooling
若一个RoI中含有一个类别C的物体,我们将该RoI划分为个区域,其分别表示该物体的各个部位,即物体的各个部位和RoI的这些子区域是“一一映射”的对应关系。
一个RoI必须是个子区域都含有该物体的相应部位,我们才能判断该RoI属于该物体,如果该物体的很多部位都没有出现在相应的子区域中,那么就该RoI判断为背景类别。
score maps
position-sensitive score map设计的核心思想就是如何让其能够反映一个RoI的 个子区域都含有相应部位。score map本身就是一层卷积层的输出,卷积核个数(或通道)为,一共 个类别,每个类别有
个类别,每个类别有 个score map。【参考InstanceFCN】
个score map。【参考InstanceFCN】
通过RPN提取的RoI,每个RoI生成个bins(即子区域),每个bin的长宽分别是 ,每个bin对应score map上的一个区域。
,每个bin对应score map上的一个区域。
RoI的第 个子区域需要的部位和第张score map关注的部位是对应的,这种对应关系就是要让网络去学习的东西。
个子区域需要的部位和第张score map关注的部位是对应的,这种对应关系就是要让网络去学习的东西。
【举例】假设是“人”的类别,一共有9个(k=3)个score map,每一个score map都是用来描述人体的其中一个部位出现在该score map的何处,而在出现的地方就有高响应值;然后将RoI的各个子区域对应到“属于人的每一个score map”上并获取它的响应值,RoI的第个子区域(bin)一定要到第 张score map上去找对应区域的响应值。最后,RoI的 个子区域都已经分别到“属于人的 个score maps”上找到其响应值了,那么如果这些响应值都很高,那么就证明该RoI是人。
张score map上去找对应区域的响应值。最后,RoI的 个子区域都已经分别到“属于人的 个score maps”上找到其响应值了,那么如果这些响应值都很高,那么就证明该RoI是人。
RoI pooling
池化操作是在某个bin对应的score map上的子区域执行,且执行的是平均池化(也可以是最大值池化)。在第 个bin(0≤i,j≤k−1)中,定义一个position-sensitive RoI pooling操作,它只在第个分数图中进行池化:
个bin(0≤i,j≤k−1)中,定义一个position-sensitive RoI pooling操作,它只在第个分数图中进行池化: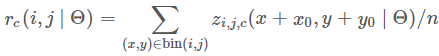 (执行平均池化,也可以是最大池化。)
(执行平均池化,也可以是最大池化。) 是在第个bin中对
是在第个bin中对 类别的池化响应(response),
类别的池化响应(response), 是个分数图中的其中一个分数图,
是个分数图中的其中一个分数图, 表示RoI的左上角坐标,
表示RoI的左上角坐标, 是第个bin中的像素数量,
是第个bin中的像素数量, 表示网络中所有可学习的参数。
表示网络中所有可学习的参数。
对score maps和RoI进行position-sensitive RoI pooling,输出 维向量,reshape之后
维向量,reshape之后 的三维张量position-sensitive scores。个scores在RoI上进行投票(vote),为每个RoI生成一个维的向量:
的三维张量position-sensitive scores。个scores在RoI上进行投票(vote),为每个RoI生成一个维的向量: 。
。
对目标定位的输入是 ,表示9个小区域的[dx,dy,dw,dh]4个偏移坐标。
,表示9个小区域的[dx,dy,dw,dh]4个偏移坐标。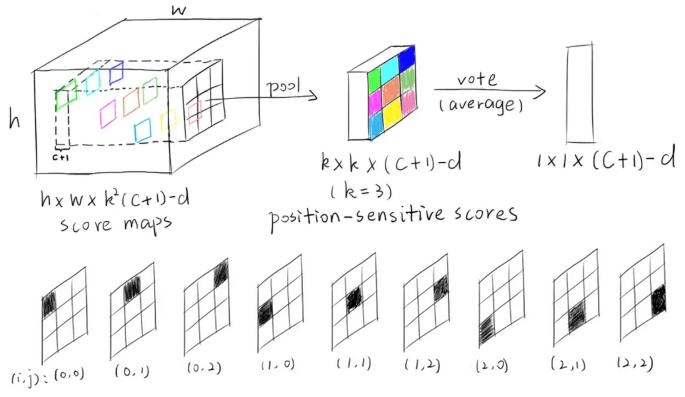
3.FPN
代表论文:Feature Pyramid Networks for Object Detection(特征金字塔网络用于目标识别)
4.Mask R-CNN
4.1改进
Mask R-CNN是ICCV2017的best paper,在一个网络中同时做目标检测(object detection)和实例分割(instance segmentation)。Mask R-CNN还可以延伸用到更复杂的任务上,比如:评估人体动作(pose)。
Mask R-CNN可以通过Faster R-CNN扩展得到。一般使用bounding box表示目标检测,使用语义分割来表示像素级分类,而实例分割兼具了语义(semantic)和检测(detection)两种需求。
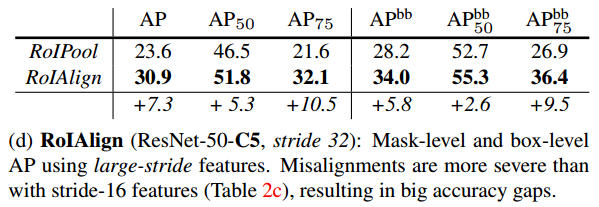
- Faster R-CNN并不是设计成网络输入输出之间从像素到像素一一对应的(alignment),即在最后全连接层为了保证输入的尺寸一致,使用RoIPool来统一RoI大小,但RoIPool导致了RoI和特征之间的错位(misalignment),这对于预测具有像素级精度的mask是不利的。为了解决非对应的问题,Mask R-CNN提出了RoIAlign,替代RoIPool,它保留了精确的空间位置。
Faster R-CNN中,对于每个ROI(论文中叫candidate object)主要有两个输出(分类+回归)。Mask R-CNN则添加了第三个输出:object mask,也就说对每个ROI都输出一个mask,该支路是通过FCN网络(FCN应用在每个RoI上来预测出一个mask)来实现的。
4.2网络结构
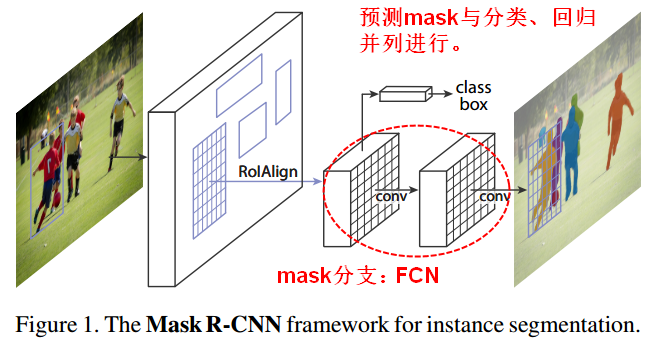
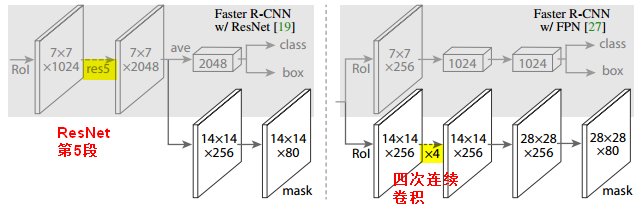
Mask R-CNN的网络结构分为两部分:
主干(backbone)部分是卷积结构,用于在整张图片上提取特征。backbone部分可以使用ResNet和FPN做特征提取。使用FPN生成的mask尺寸(28x28)更大更细致。
网络头部(head)部分是bounding-box识别(分类和回归)以及对每个RoI做mask预测。4.2.1 two-stage
Mask R-CNN采用了两阶段(two-stage)进程:
first stage:RPN。
- second stage:三个相互平行的支路(class分类,box offsets回归,mask预测)。相比其他先分割再分类的实例分割算法相比,这种平行设计不仅简单而且高效。
4.2.2 mask branch
为了输出object mask,就需要更精确的提取对象的空间位置/布局信息。
mask预测是为每一个RoI输出一个二分的mask,使用FCN从每个RoI中预测一个mxm大小的mask,这就要求mask branch中的每一层都要维护对象的空间布局信息(mxm),而RoIAlign层就在mask预测中起到了关键作用,保证了RoI特征图可以实现像素级别的空间响应。
每个RoI的mask分支的输出有 个维度:
个维度: 个二分类的mask,每个mask大小(分辨率)是
个二分类的mask,每个mask大小(分辨率)是 。
。
4.2.3 RoIAlign
【RoIPool】RPN网络得到的ROI坐标是针对输入图像大小的,所以首先需要将ROI坐标缩小到输出特征对应的大小,假设输出特征尺寸是输入图像的1/16,那么先将ROI坐标除以16并取整(第一次量化);然后将取整后的ROI划分成HW个bin,因为划分过程得到的bin的坐标是浮点值,所以做第二次量化,具体而言对于左上角坐标采用向下取整,对于右下角坐标采用向上取整,最后进行最大池化(每个bin中的最大值作为该bin的值),最终输出的HW大小的ROI特征。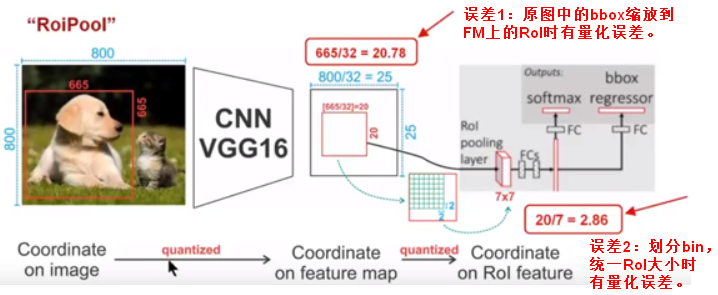
由于RoIPool过程中的两次量化,引入了误差;RoIAlign中,对RoI缩放以及划分bin时,不再进行量化,而是在每个RoI的bin(子区域)中,使用双线性插值通过周围特征图的网格点来计算四个采样点的值,最后对这四个点求均值或最大值作为这个bin的值,通过这种方式计算每个bin的值后,最终输出H*W大小的ROI特征。
ROIAlign整个过程没有采用量化操作,没有引入误差,经过RoIAlign处理后,原图中的像素和feature map中的像素是一一对应的,不仅提高了mask的准确率,也解耦了mask和class预测。(FCN通常对每个像素预测多个类别,这使得分割(segmentation)和分类是耦合的。)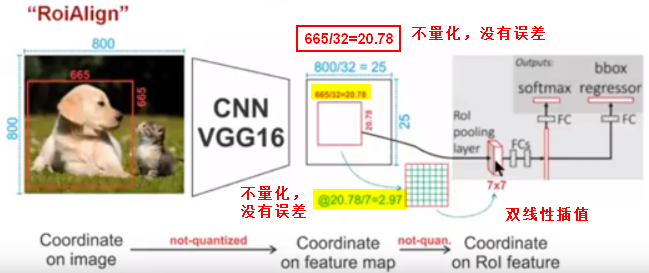

4.3算法步骤
- 将预处理后的图片输入预训练的网络(ResNet、FPN)中,提取特征。
- 在特征图上生成proposals,通过RPN进行二值分类和候选框回归校正,过滤候选框得到RoIs。
- 对剩下的RoIs进行RoIAlign操作,将原图和feature map上的特征图对应起来。
- 对RoIs进行分类、候选框回归预测、mask生成(对每个RoI进行FCN操作)。
4.4网络损失与训练
定义损失 时,对mask的每个像素点值求sigmoid,计算平均的二分交叉熵(一个mask包含多个像素点,所以是每个像素点的交叉熵损失的均值)。只定义在被判定为正样本的RoI上,如果一个RoI对应的真实类别是k,则损失只定义在第k个mask上,跟其他mask输出无关。所以,只是依赖专门的某个分类分支去预测标签并用来选择输出的mask,这就解耦了mask和类别预测。
时,对mask的每个像素点值求sigmoid,计算平均的二分交叉熵(一个mask包含多个像素点,所以是每个像素点的交叉熵损失的均值)。只定义在被判定为正样本的RoI上,如果一个RoI对应的真实类别是k,则损失只定义在第k个mask上,跟其他mask输出无关。所以,只是依赖专门的某个分类分支去预测标签并用来选择输出的mask,这就解耦了mask和类别预测。
与利用FCN进行语义分割的有所不同,它通常使用一个per-pixel sigmoid和一个multinomial cross-entropy loss ,在这种情况下mask之间存在竞争关系;而使用了一个per-pixel sigmoid 和一个binary loss ,不同的mask之间不存在竞争关系。
对一个RoI来说,训练时总的损失就是: 。
。
训练阶段,每个批量2张图片,每张图片上N个采样的RoI,正负例比例是1:3。(当网络结构的backbone是ResNet时,N=64,当backbone是FPN时,N=512)RPN和Mask R-CNN使用相同的backbone。
测试时,proposal的数量对于ResNet架构采用300,对于FPN架构采用1000,mask分支都是基于最后score最高的100个预测结果进行的,这样增加的计算量就非常少。5.YOLO
来源: 1.https://www.bilibili.com/read/cv2142386 2.https://blog.csdn.net/u014380165/article/details/72848254 3.https://blog.csdn.net/WZZ18191171661/article/details/79453780

若有收获,就点个赞吧
0 人点赞
