1.什么是 Redis
Redis 是一个使用 ANSI C 编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。从 2015 年 6 月开始,Redis 的开发由 Redis Labs 赞助,而 2013 年 5 月至 2015 年 6 月期间,其开发由 Pivotal 赞助。在 2013 年 5 月之前,其开发由 VMware 赞助。根据月度排行网站 DB-Engines.com 的数据显示,Redis是 最流行的键值对存储数据库。
2.Redis 具有如下特点
- Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,不会造成数据丢失
- Redis 支持五种不同的数据结构类型之间的映射,包括简单的 key/value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储
-
3.Redis 具有如下功能
内存存储和持久化:redis 支持异步将内存中的数据写到硬盘上,在持久化的同时不影响继续服务
- 取最新N个数据的操作,如:可以将最新的 10 条评论的 ID 放在 Redis 的 List 集合里面
- 数据可以设置过期时间
- 自带发布、订阅消息系统
- 定时器、计数器
4.Redis 安装
Windows 版 Redis 的安装,整体来非常简单,考虑到 Redis 的大部分使用场景都是在 Linux 上,因此这里我对 Windows 上的安装不做介绍,下面我们主要来看下 Linux 上怎么安装 Redis 。
环境:
- CentOS7
- redis4.0.8
1.首先下载 Redis,下载地址https://redis.io/,下载获得 redis-4.0.8.tar.gz 后将它放入我们的 Linux 目录 /opt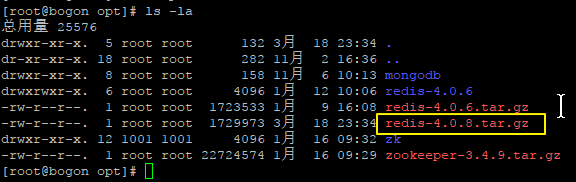
2./opt 目录下,对文件进行解压,解压命令: tar -zxvf redis-4.0.8.tar.gz ,如下: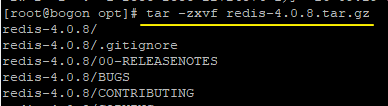
3.解压完成后出现文件夹:redis-4.0.8,进入到该目录中: cd redis-4.0.8
4.在 redis-4.0.8 目录下执行 make 命令进行编译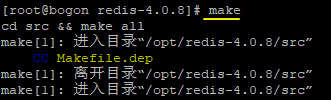
5.如果 make 完成后继续执行 make install 进行安装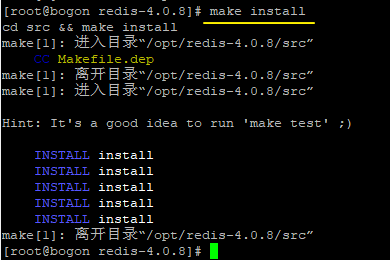
OK,至此,我们的 redis 就算安装成功了。
6.在我们启动之前,需要先做一个简单的配置:修改 redis.conf 文件,将里面的 daemonize no 改成 yes,让服务在后台启动,如下:
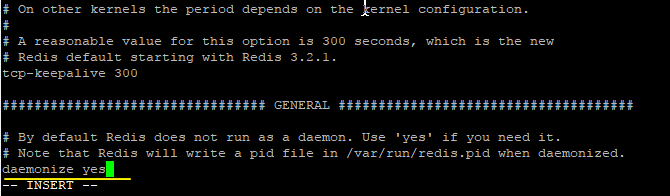
7.启动,通过redis-server redis.conf命令启动redis,如下:
8.测试
首先我们可以通过 redis-cli 命令进入到控制台,然后通过 ping 命令进行连通性测试,如果看到 pong ,表示连接成功了,如下: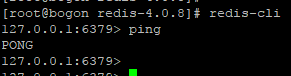
9.关闭,通过 shutdown 命令我们可以关闭实例,如下:
OK,至此,我们的 Redis 就安装成功了
5.五大数据类型介绍
redis 中的数据都是以 key/value 的形式存储的,五大数据类型主要是指 value 的数据类型,包含如下五种:
STRING
STRING 是 redis 中最基本的数据类型,redis 中的 STRING 类型是二进制安全的,即它可以包含任何数据,比如一个序列化的对象甚至一个 jpg 图片,要注意的是 redis 中的字符串大小上限是 512M 。
LIST
LIST 是一个简单的字符串列表,按照插入顺序进行排序,我们可以从 LIST 的头部 (LEFT) 或者尾部 (RIGHT) 插入一个元素,也可以从 LIST 的头部(LEFT)或者尾部 (RIGHT) 弹出一个元素。
HASH
HASH 类似于 Java 中的 Map ,是一个键值对集合,在 redis 中可以用来存储对象。
SET
SET 是 STRING 类型的无序集合,不同于 LIST ,SET 中的元素不可以重复。
ZSET
ZSET 和 SET 一样,也是 STRING 类型的元素的集合,不同的是 ZSET 中的每个元素都会关联一个 double 类型的分数,ZSET 中的成员都是唯一的,但是所关联的分数可以重复。
OK,接下来我们就来看看这五种数据类型要怎么操作。
6.key 相关的命令
首先通过 redis-server redis.conf 命令启动 redi s,再通过 redis-cli 命令进入到控制台中,如下:
String类型 存储:set key value 取值:get key 删除:del key 查看所有键:keys *
127.0.0.1:6379> set key1 "nihao"OK127.0.0.1:6379> set key2 "nihao"OK127.0.0.1:6379> del key1(integer) 1127.0.0.1:6379> keys *1) "key2"
Hash类型 相当于一个key对于一个map,map中还有key-value 存储:hset key field value 取值:hget key field
127.0.0.1:6379> hset zhangsan age 33
(integer) 1
127.0.0.1:6379> hset zhangsan weight 66
(integer) 1
127.0.0.1:6379> hget zhangsan age
"33"
127.0.0.1:6379> hget zhangsan weight
"66"
查看某个键对应的map里面的所有key:hkeys key 查看某个键对应的map里面的所有的value:hvals key 查看某个键的map:hgetall key
127.0.0.1:6379>hkeys zhangsan
1) "age"
2) "weight"
127.0.0.1:6379>hvals zhangsan
1) "33"
2) "66"
127.0.0.1:6379>hgetall zhangsan
1) "age"
2) "33"
3) "weight"
4) "66"
List类型 存储:push,分为lpush list v1 v2 v3 v4 …(左边添加),rpush list v1 v2 v3 v4 …(右边添加)
127.0.0.1:6379>lpush list1 1 2 3 4
"4"
取值:pop,分为lpop lpop list(左边取,移除list最左边的值) ,rpop rpop list(右边取,移除list最右边的值)
127.0.0.1:6379>lpop list1
"4"
查看list:lrange key 0 2 , lrange key 0 -1表示查看全部
127.0.0.1:6379>lrange list2 0 2
1) "wangwu"
2) "lisi"
3) "zhangsan"
Set类型 Set中的元素是无序不重复的,出现重复会覆盖 存储:sadd key v1 v2 v3 …
127.0.0.1:6379>sadd set1 hello world 123
"3"
移除:srem key v
127.0.0.1:6379>srem set1 123
"1"
查看set集合: smembers key
127.0.0.1:6379>smembers set1
1) "world"
2) "hello"
另外还提供了差集,交集,并集操作 差集:sdiff seta setb(seta中有setb中没有的元素)
127.0.0.1:6379>sadd set1 hello world nihao haha
"4"
127.0.0.1:6379>sadd set2 hello2 world2 nihao haha
"4"
127.0.0.1:6379>sdiff set1 set2
1) "hello"
2) "world"
交集:sinter seta setb
127.0.0.1:6379>sinter set1 set2
1) "haha"
2) "nihao"
并集:sunion seta setb
127.0.0.1:6379>sunion set1 set2
1) "hello2"
2) "haha"
3) "world"
4) "hello"
5) "world2"
ZSet,有序Set 存储:存储的时候要求对set进行排序,需要对存储的每个value值进行打分,默认排序是分数由低到高。zadd key 分数1 v1 分数2 v2 分数3 v3…
127.0.0.1:6379>zadd zset1 1 a 3 b 2 c 6 d 5 e 4 f
"6"
127.0.0.1:6379>zrange zset1 0 -1
1) "a"
2) "c"
3) "b"
4) "f"
5) "e"
6) "d"
取值:取指定的值 zrem key value(取出后,Set当中对应少一个)
127.0.0.1:6379>zrem zset1 b
"1"
127.0.0.1:6379>zrem zset1 a
"1"
127.0.0.1:6379>zrem zset1 c
"1"
取(遍历)所有的值(不包括分数):zrange key 0 -1,降序取值用zrevrange key 0 -1
127.0.0.1:6379>zrange zset1 0 -1
1) "f"
2) "e"
3) "d"
127.0.0.1:6379>zrevrange zset1 0 -1
1) "d"
2) "e"
3) "f"
取所有的值(带分数):zrange(zrevrange) key 0 -1 withscores
127.0.0.1:6379>zrange zset1 0 -1 withscores
1) "f"
2) "4"
3) "e"
4) "5"
5) "d"
6) "6"
TTL 命令
TTL 命令可以查看一个给定 key 的有效时间:
127.0.0.1:6379> TTL k1
(integer) -1
127.0.0.1:6379> TTL k2
(integer) -2
EXPIRE 命令
EXPIRE 命令可以给 key 设置有效期,在有效期过后,key 会被销毁。
127.0.0.1:6379> EXPIRE k1 30
(integer) 1
127.0.0.1:6379> TTL k1
(integer) 25
127.0.0.1:6379>
PERSIST 命令
PERSIST 命令表示移除一个 key 的过期时间,这样该 key 就永远不会过期:
127.0.0.1:6379> EXPIRE k1 60
(integer) 1
127.0.0.1:6379> ttl k1
(integer) 57
127.0.0.1:6379> PERSIST k1
(integer) 1
127.0.0.1:6379> ttl k1
(integer) -1
7.Jedis 使用
Redis 的知识我们已经介绍的差不多了,我们来看看如何使用 Java 操作 redis。
查看 redis 官网,我们发现用 Java 操作 redis,我们有多种解决方案,如下图: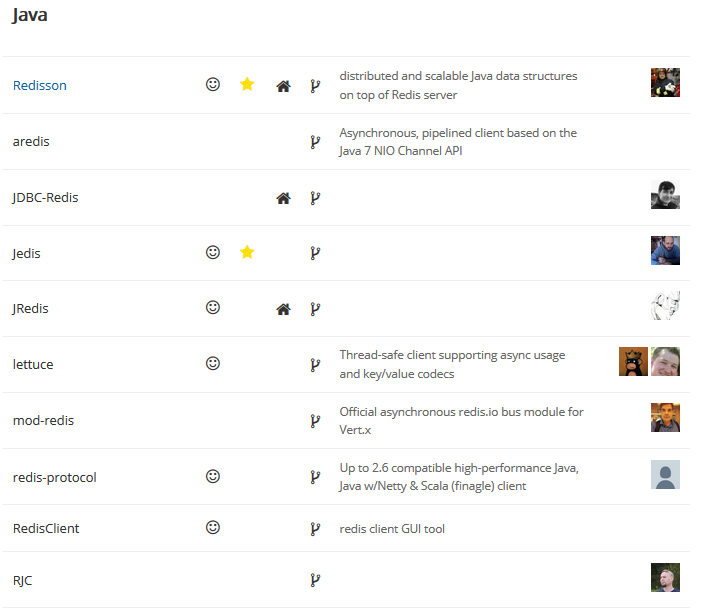
这里的解决方案有多种,我们采用 Jedis,其他的框架也都大同小异,我这里权当抛砖引玉,小伙伴也可以研究研究其他的方案 。
配置
客户端要能够成功连接上 redis 服务器,需要检查如下三个配置:
1.远程 Linux 防火墙已经关闭,以我这里的 CentOS7 为例,关闭防火墙命令 systemctl stop firewalld.service ,同时还可以再补一刀 systemctl disable firewalld.service 表示禁止防火墙开机启动。
2.关闭 redis 保护模式,在 redis.conf 文件中,修改 protected 为 no,如下:
protected-mode no
3.注释掉 redis 的 ip 地址绑定,还是在 redis.conf 中,将 bind:127.0.0.1 注释掉,如下:
# bind:127.0.0.1
Java 端配置
上面的配置完成后,我们可以创建一个普通的 JavaSE 工程来测试下了,Java 工程创建成功后,添加 Jedis 依赖,如下:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
然后我们可以通过如下一个简单的程序测试一下连接是否成功:
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.248.128", 6379);
String ping = jedis.ping();
System.out.println(ping);
}
运行之后,看到如下结果表示连接成功了: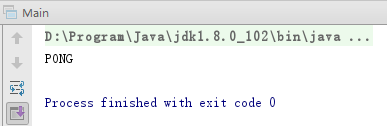
连接成功之后,剩下的事情就比较简单了,Jedis 类中方法名称和 redis 中的命令基本是一致的,看到方法名小伙伴就知道是干什么的,因此这些我这里不再重复叙述。
频繁的创建和销毁连接会影响性能,我们可以采用连接池来部分的解决这个问题:
public static void main(String[] args) {
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxTotal(100);
config.setMaxIdle(20);
JedisPool jedisPool = new JedisPool(config, "192.168.248.128", 6379);
Jedis jedis = jedisPool.getResource();
System.out.println(jedis.ping());
}
这样就不会频繁创建和销毁连接了,在 JavaSE 环境中可以把连接池配置成一个单例模式,如果用了 Spring 容器的话,可以把连接池交给 Spring 容器管理。
8.Spring Data Redis 使用
上文我们介绍了 Redis,在开发环境中,我们还有另外一个解决方案,那就是 Spring Data Redis
Spring Data Redis 介绍
Spring Data Redis 是 Spring 官方推出,可以算是 Spring 框架集成 Redis 操作的一个子框架,封装了 Redis 的很多命令,可以很方便的使用 Spring 操作 Redis 数据库,Spring 对很多工具都提供了类似的集成,如 Spring Data MongDB、Spring Data JPA 等, Spring Data Redis 只是其中一种。
环境搭建
要使用 SDR,首先需要搭建 Spring+SpringMVC 环境,由于这个不是本文的重点,因此这一步我直接略过,Spring+SpringMVC 环境搭建成功后,接下来我们要整合 SDR,首先需要添加如下依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>RELEASE</version>
</dependency>
然后创建在 resources 目录下创建 redis.properties 文件作为 redis 的配置文件,如下:
redis.host=192.168.248.128
redis.port=6379
redis.maxIdle=300
redis.maxTotal=600
redis.maxWait=1000
redis.testOnBorrow=true
在 spring 的配置文件中,添加如下 bean:
<!--引入redis.properties文件-->
<context:property-placeholder location="classpath:redis.properties"/>
<!--配置连接池信息-->
<bean class="redis.clients.jedis.JedisPoolConfig" id="poolConfig">
<property name="maxIdle" value="${redis.maxIdle}"/>
<property name="maxTotal" value="${redis.maxTotal}"/>
<property name="maxWaitMillis" value="${redis.maxWait}"/>
<property name="testOnBorrow" value="${redis.testOnBorrow}"/>
</bean>
<!--配置基本连接信息-->
<bean class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" id="connectionFactory">
<property name="hostName" value="${redis.host}"/>
<property name="port" value="${redis.port}"/>
<property name="poolConfig" ref="poolConfig"/>
</bean>
<!--配置RedisTemplate-->
<bean class="org.springframework.data.redis.core.RedisTemplate" id="redisTemplate">
<property name="connectionFactory" ref="connectionFactory"/>
<!--key和value要进行序列化,否则存储对象时会出错-->
<property name="keySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
</property>
<property name="valueSerializer">
<bean class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer"/>
</property>
</bean>
好了,在 Spring 中配置了 redisTemplate 之后,接下来我们就可以在 Dao 层注入 redisTemplate 进而使用了。接下来我们首先创建实体类 User ,注意 User 一定要可序列化:
public class User implements Serializable{
private String username;
private String password;
private String id;
//get/set省略
}
然后在 Dao 层实现数据的添加和获取,如下:
@Repository
public class HelloDao {
@Autowired
RedisTemplate redisTemplate;
public void set(String key, String value) {
ValueOperations ops = redisTemplate.opsForValue();
ops.set(key, value);
}
public String get(String key) {
ValueOperations ops = redisTemplate.opsForValue();
return ops.get(key).toString();
}
public void setuser(User user) {
ValueOperations ops = redisTemplate.opsForValue();
ops.set(user.getId(), user);
}
public User getuser(String id) {
ValueOperations<String, User> ops = redisTemplate.opsForValue();
User user = ops.get(id);
System.out.println(user);
return user;
}
}
SDR 官方文档中对 Redistemplate 的介绍,通过 Redistemplate 可以调用 ValueOperations 和 ListOperations 等等方法,分别是对 Redis 命令的高级封装。但是 ValueOperations 等等这些命令最终是要转化成为 RedisCallback 来执行的。也就是说通过使用 RedisCallback 可以实现更强的功能。
最后,给大家展示下我的 Service 和 Controller ,如下:
@Service
public class HelloService {
@Autowired
HelloDao helloDao;
public void set(String key, String value) {
helloDao.set(key,value);
}
public String get(String key) {
return helloDao.get(key);
}
public void setuser(User user) {
helloDao.setuser(user);
}
public String getuser(String id) {
String s = helloDao.getuser(id).toString();
return s;
}
}
@Controller
public class HelloController {
@Autowired
HelloService helloService;
@RequestMapping("/set")
@ResponseBody
public void set(String key, String value) {
helloService.set(key, value);
}
@RequestMapping("/get")
@ResponseBody
public String get(String key) {
return helloService.get(key);
}
@RequestMapping("/setuser")
@ResponseBody
public void setUser() {
User user = new User();
user.setId("1");
user.setUsername("深圳");
user.setPassword("sang");
helloService.setuser(user);
}
@RequestMapping(value = "/getuser",produces = "text/html;charset=UTF-8")
@ResponseBody
public String getUser() {
return helloService.getuser("1");
}
}
测试过程就不再展示了,小伙伴们可以用 POSTMAN 等工具自行测试 。
9.SpringBoot整合Redis配合Spring Cache
新建项目添加四个依赖,在springboot2.1.5之后远程连接redis强制要求添加security依赖
对redis进行配置
# ip
spring.redis.host=127.0.0.1
# 密码
spring.redis.password=12345
# 端口
spring.redis.port=6379
# redis数据库索引
spring.redis.database=0
User实体类 实现 Serializable 可以被序列化
import java.io.Serializable;
public class User implements Serializable {
private Integer id;
private String name;
private String password;
//getter,setter省略
}
启动类上添加启用缓存注解
@SpringBootApplication
@MapperScan(basePackages = "org.neuedu.redisboot02.mapper")
@EnableCaching
public class Redisboot02Application {
public static void main(String[] args) {
SpringApplication.run(Redisboot02Application.class, args);
}
}
UserService
@Service
@Transactional
public class UserService {
@Autowired
UserMapper userMapper;
@Cacheable(value = "user",key = "#id",unless = "#result==null")
public User getUserById(Integer id) {
User user = userMapper.getUserById(id);
System.out.println("test msg");
return user;
}
@CacheEvict(value = "user",key = "#id")
public int deleteById(Integer id) {
return userMapper.deleteById(id);
}
}
@Cacheable
该注解的作用是将 value = "user",key = "#id" 值作为组合,作为缓存数据的键值,# 的参数是将方法参数id取出的意思,每次访问该方法时,注解会到缓存中检查是否有value 和 key 值作为组合的键值存在,若存在,则不会调用该方法,也就不会执行mapper的方法,否则就会调用方法,并把返回值存入缓存作为value,key之则是 value = "user",key = "#id"的组合
unless是缓存条件,上例中是结果不为空时进行缓存
@CacheEvict
该注解是删除功能,当访问该方法时,若存在value = "user",key = "#id" 组合而成的键值,就把该缓存数据删除
测试过程省略

若有收获,就点个赞吧
0 人点赞
