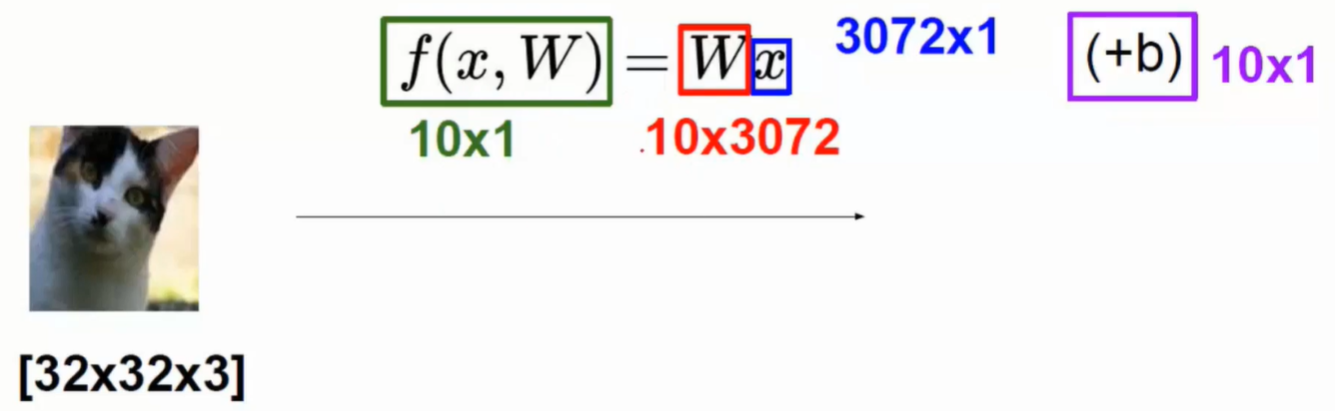
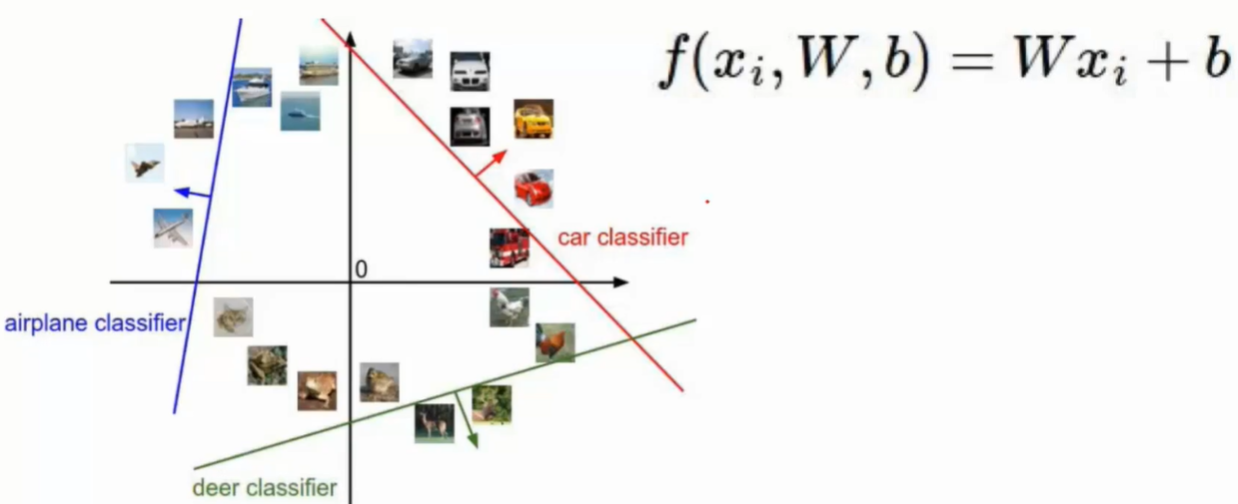
线性分类


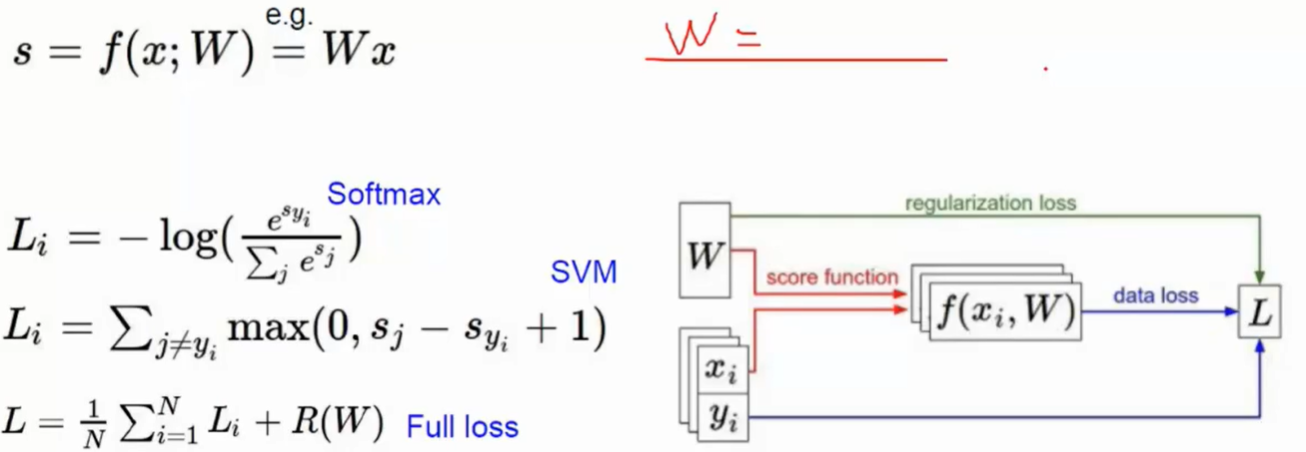
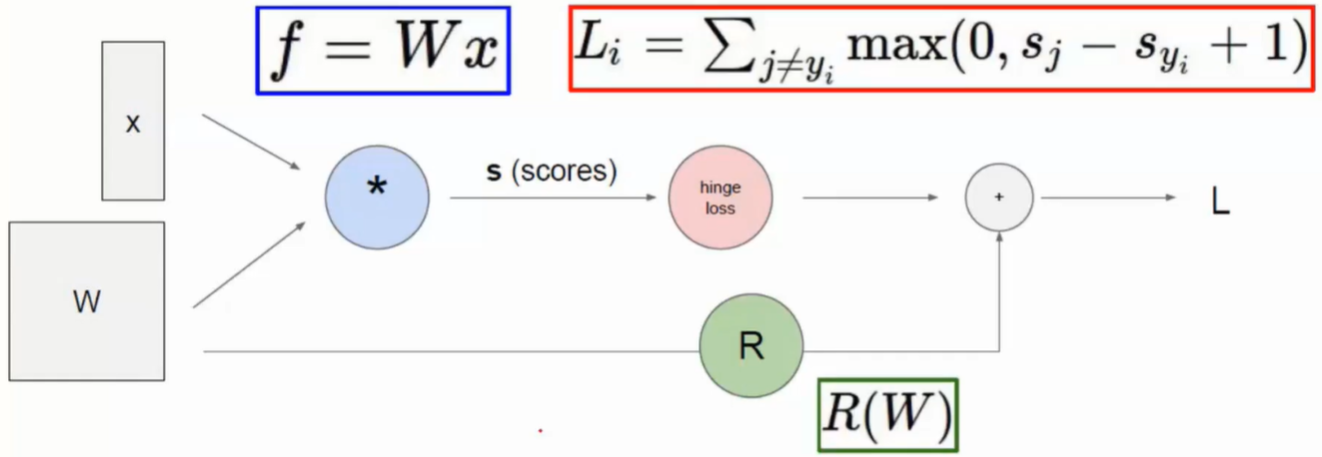
损失函数
- 评判模型判断错误的损失,即评估预测效果,偏差程度
- 举简单例子

- 其中+1是定义了一个可以容忍的程度,认为最小的容忍程度是1

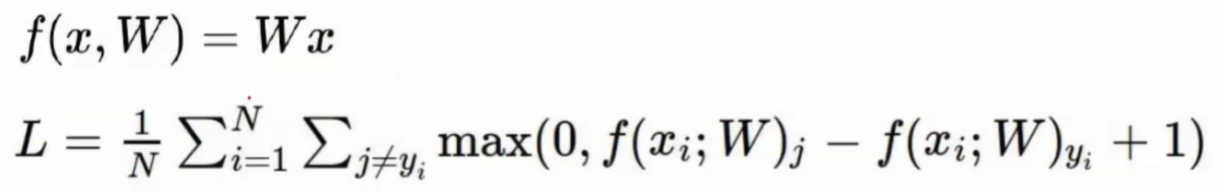
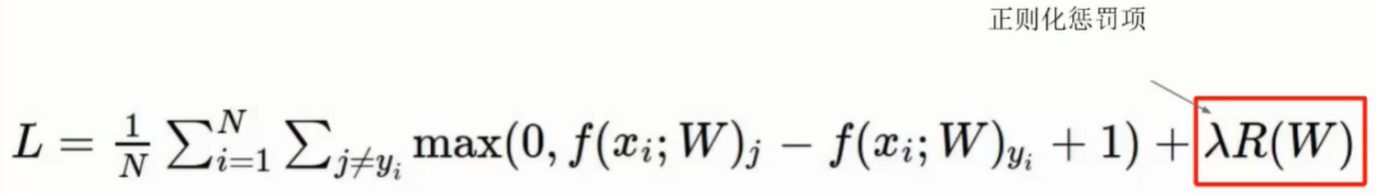
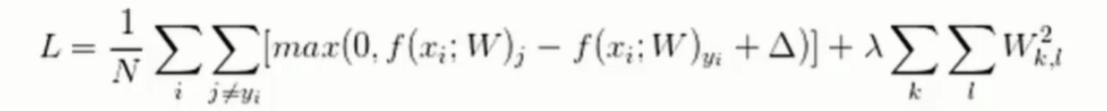
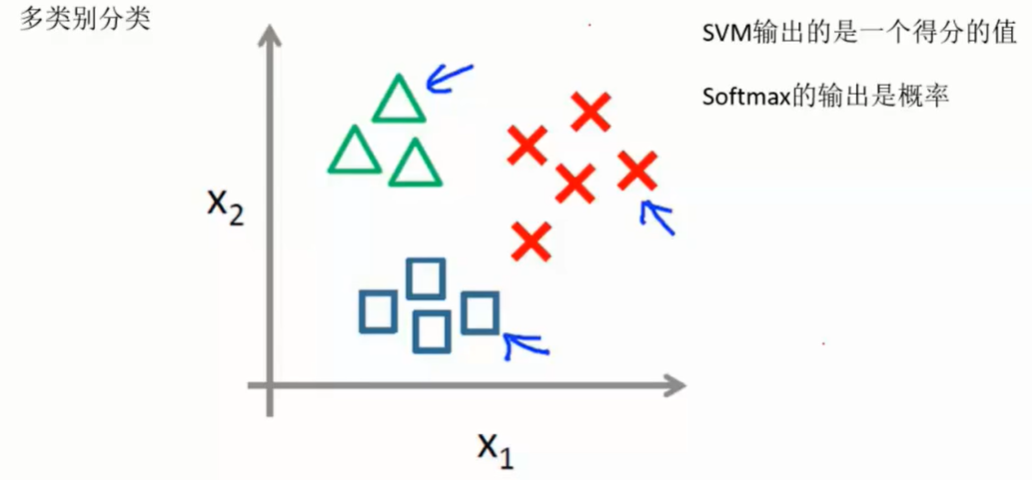

- 实例

- 先进行e的次幂操作,然后归一化,再用-log函数将它的正确概率值转换损失函数
- 结果对比
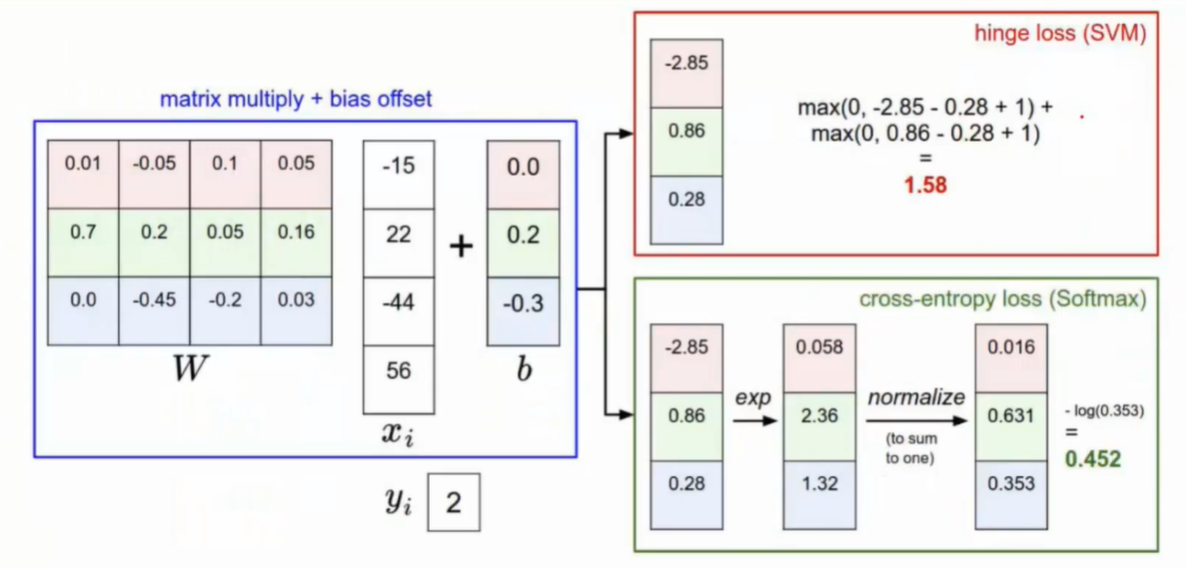
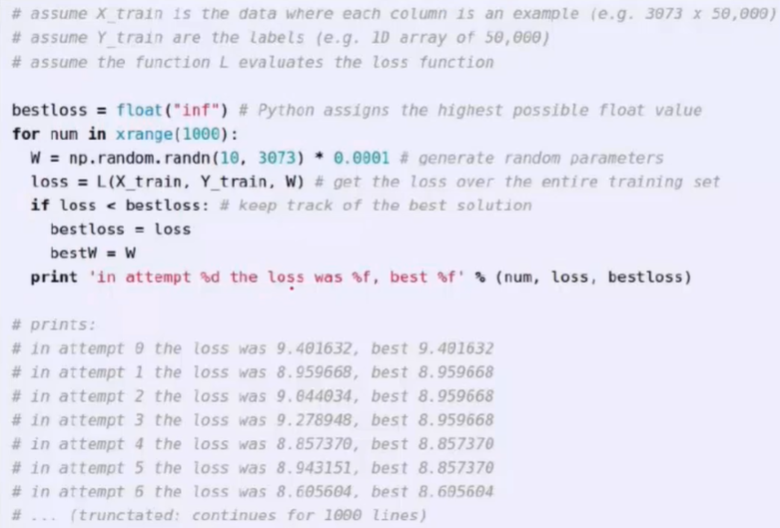
- 如果使用简单的想法
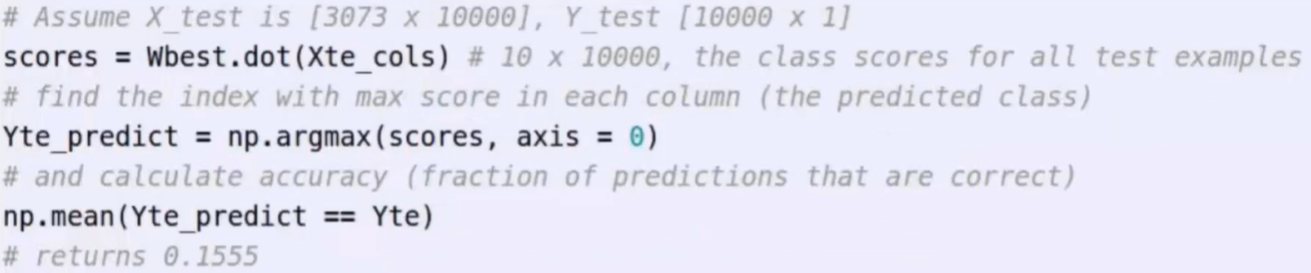
- 计算结果
- 找到最低点
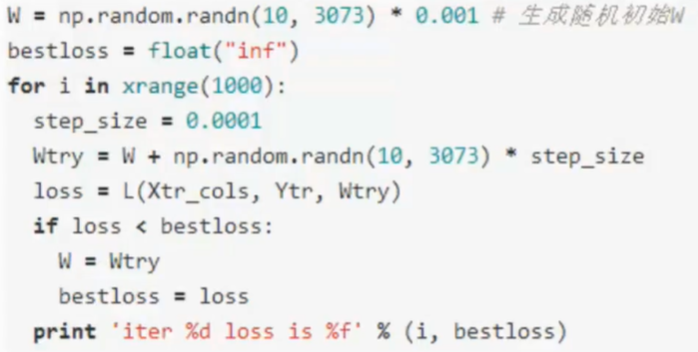
- 跟随梯度
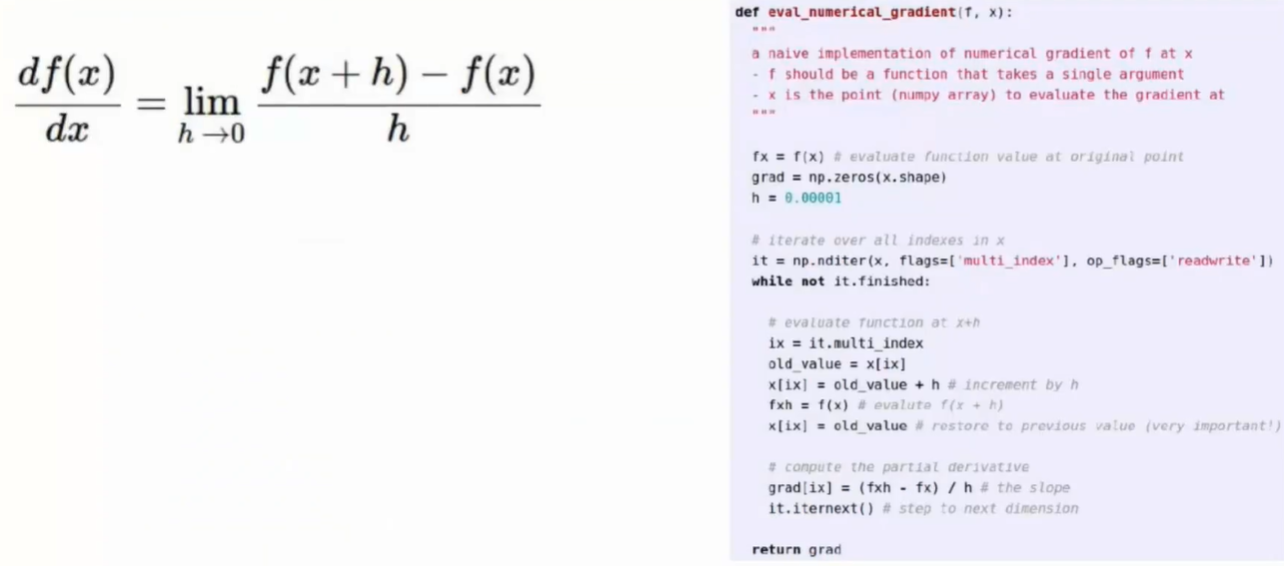
- 小批量梯度下降
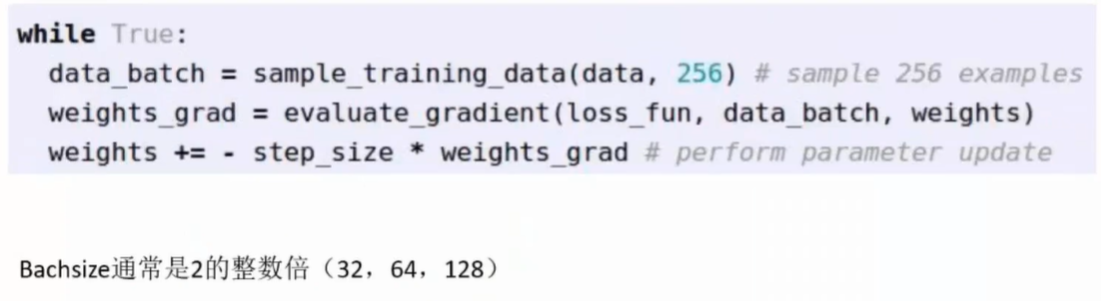
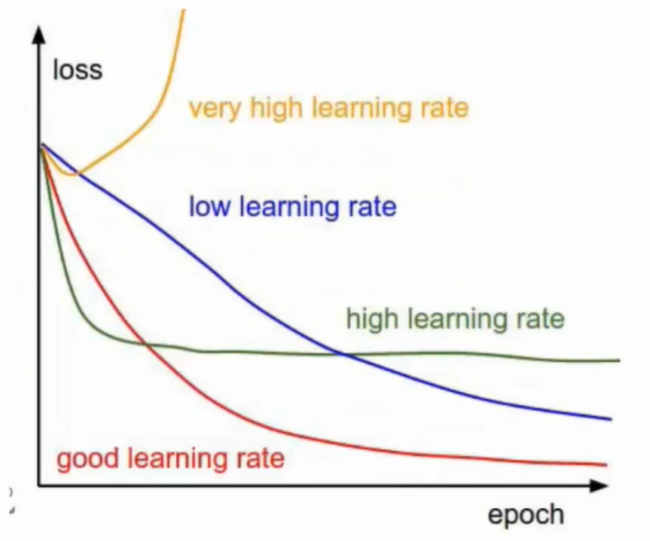
学习率
反向传播
- 前向传播得到损失函数loss值
- 反向传播使用得到的损失函数反推权重参数w
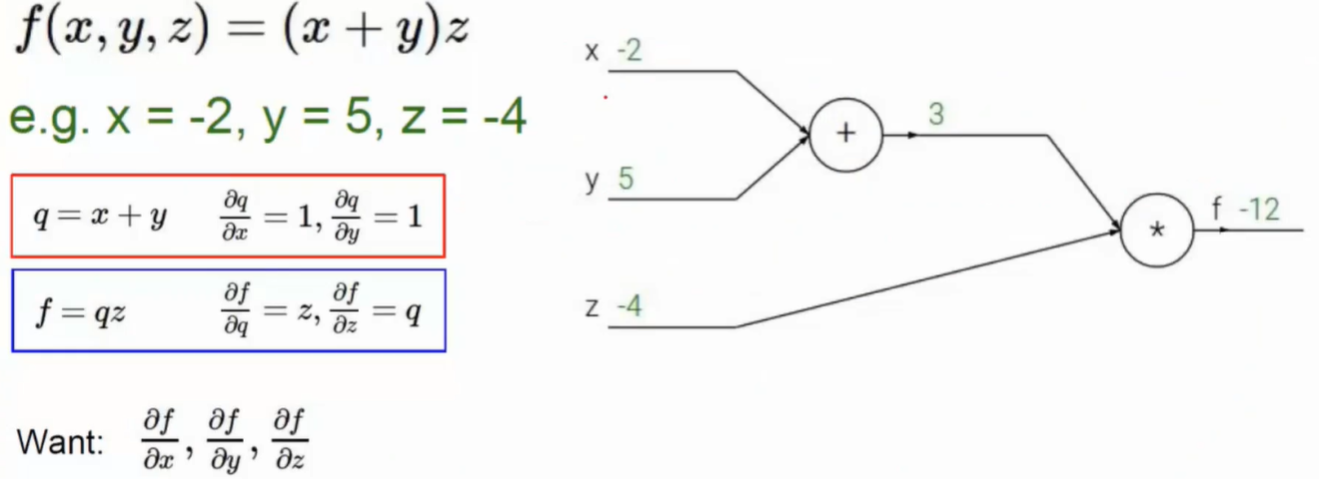
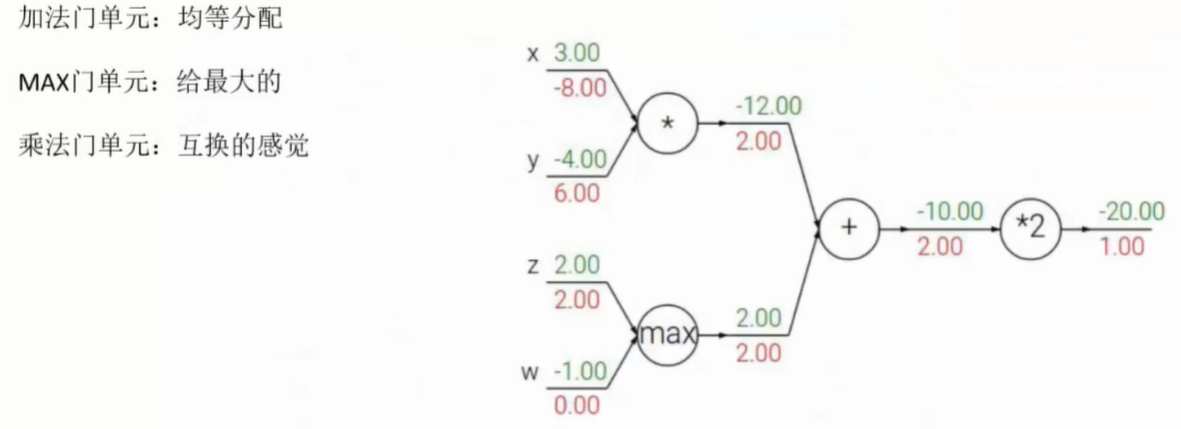
- 链式法则

- 反向传播中计算每一个权重参数对最终的结果做出了多大的贡献

- 影响不可跨级,一定是一级一级向下传递
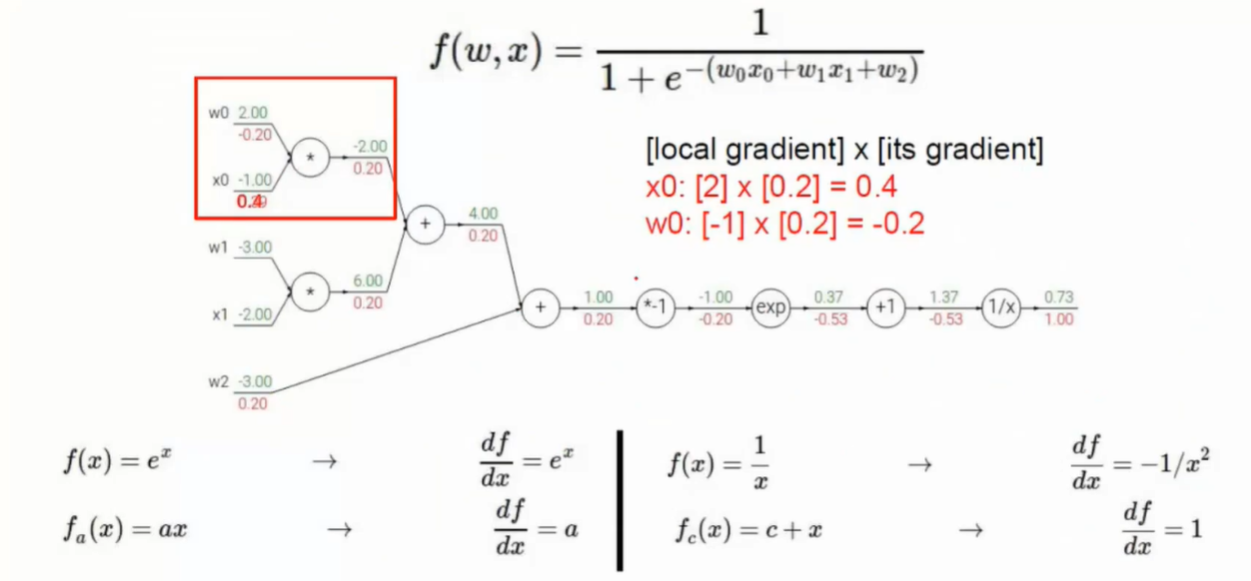
网络架构
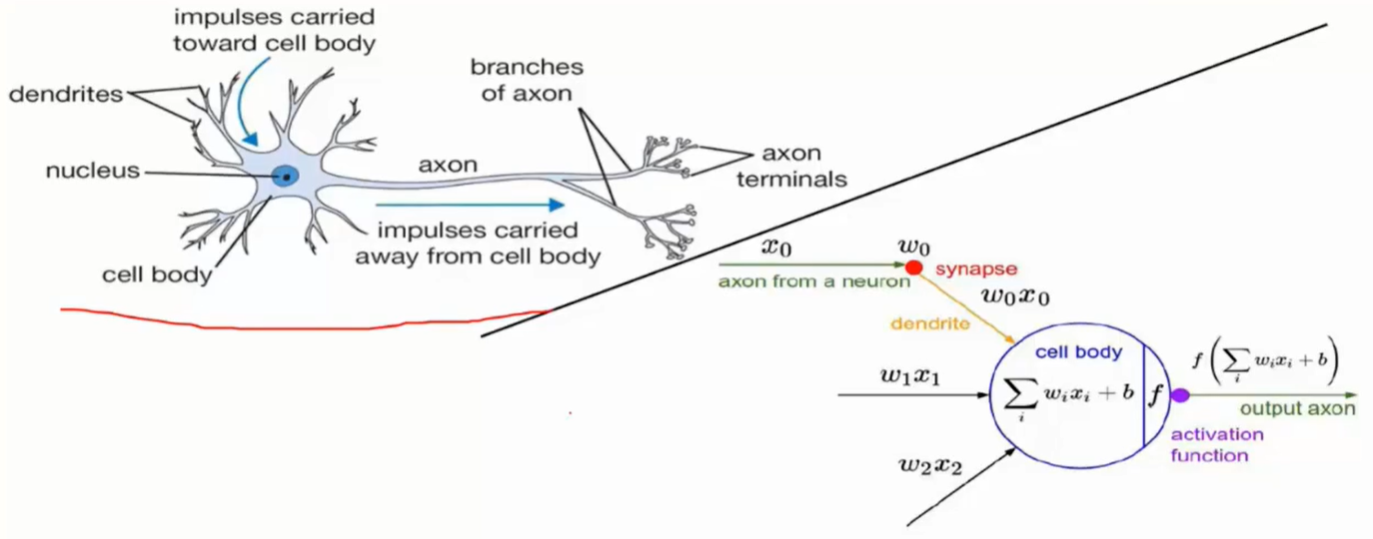
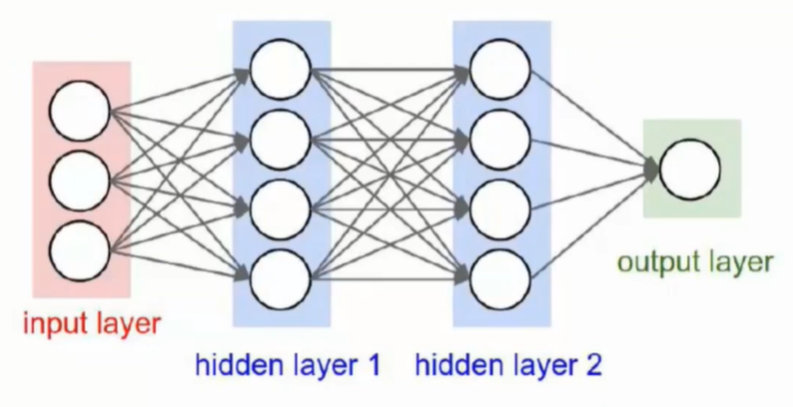
- 层之间的连线即为权重参数
- 权重参数的组合作用得到最终结果

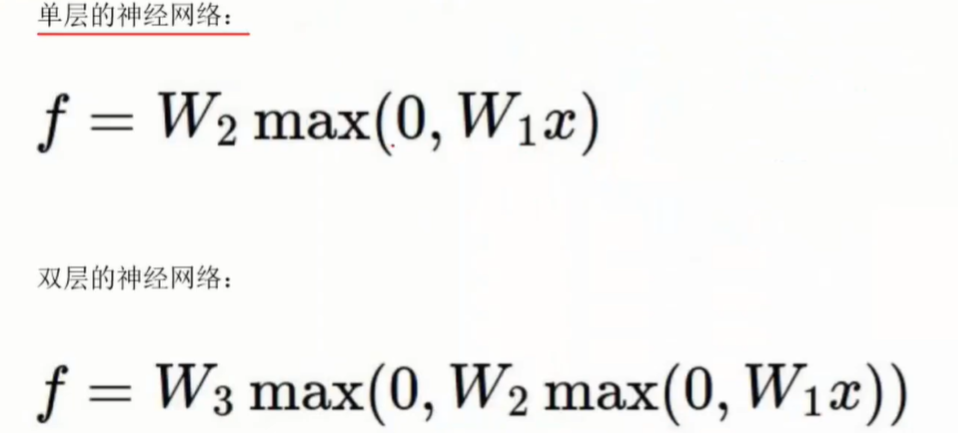
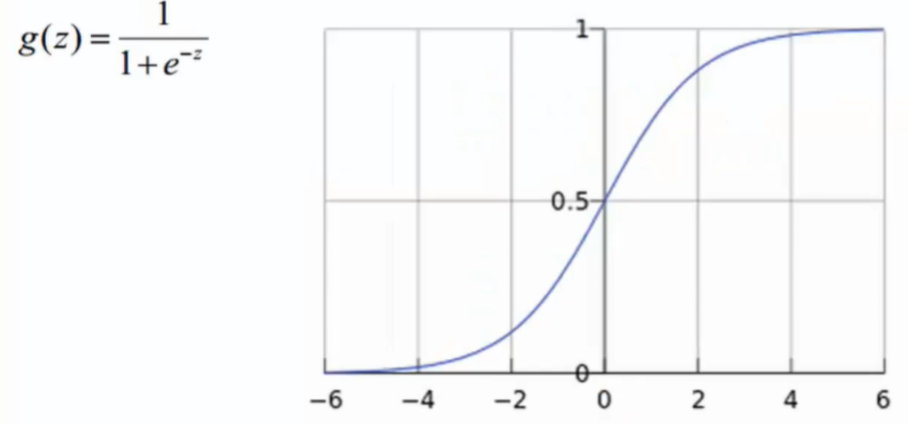
激活函数
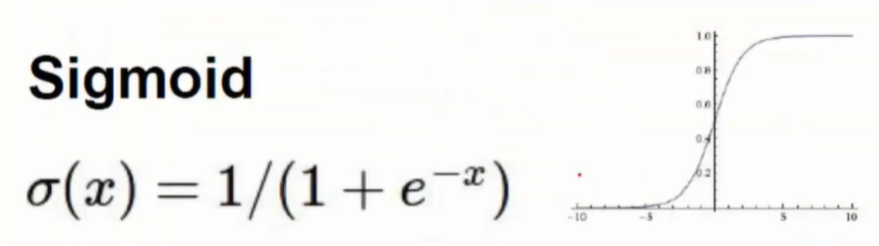
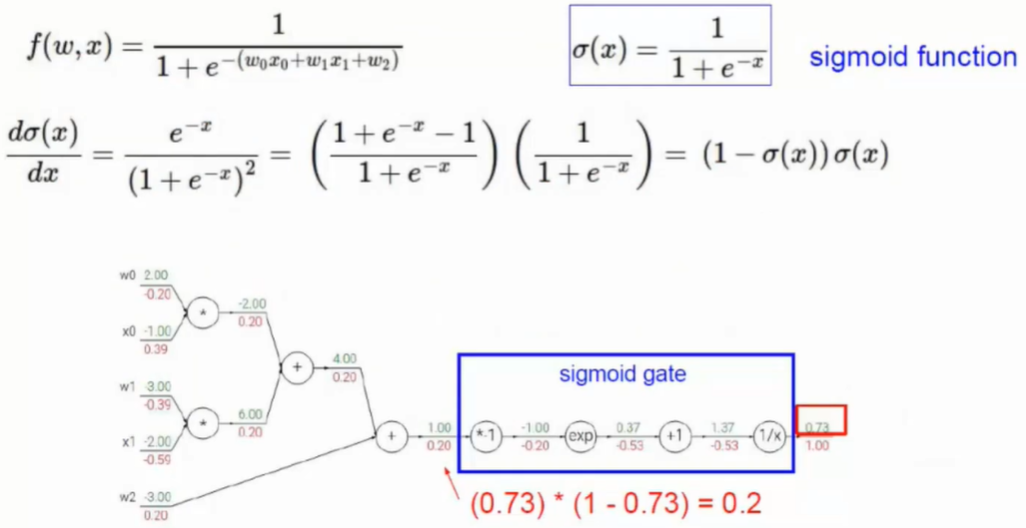
- 在中间层每次不仅只有权重参数在发挥作用,还有像Sigmode这样的激活函数作用
- 使用Sigmod作为激活函数会存在问题
- 反向传播中需要对权重参数的导数累乘
- 但是Sigmoid函数在x较大或较小的数值时导数约为0
- 这样在传递的过程中会导致出现梯度消失的现象,就导致没有办法迭代
- 当层数较多就容易导致梯度消失
- 因此使用ReLU函数取代Sigmoid函数
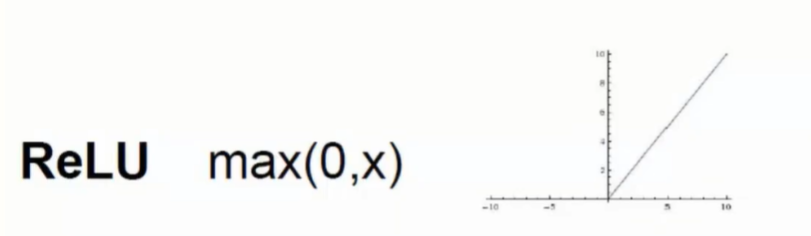
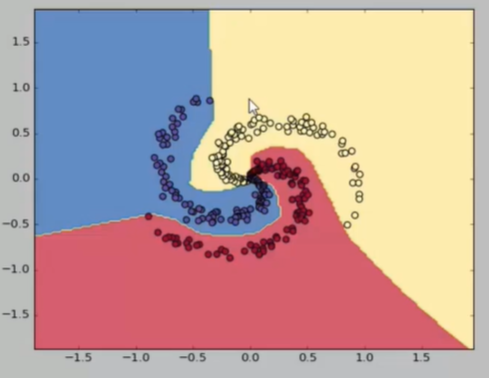
可视化演示
ConvnetJS demo
正则化项
- 过拟合是神经网络的最大问题
- 可通过正则化项抑制过拟合
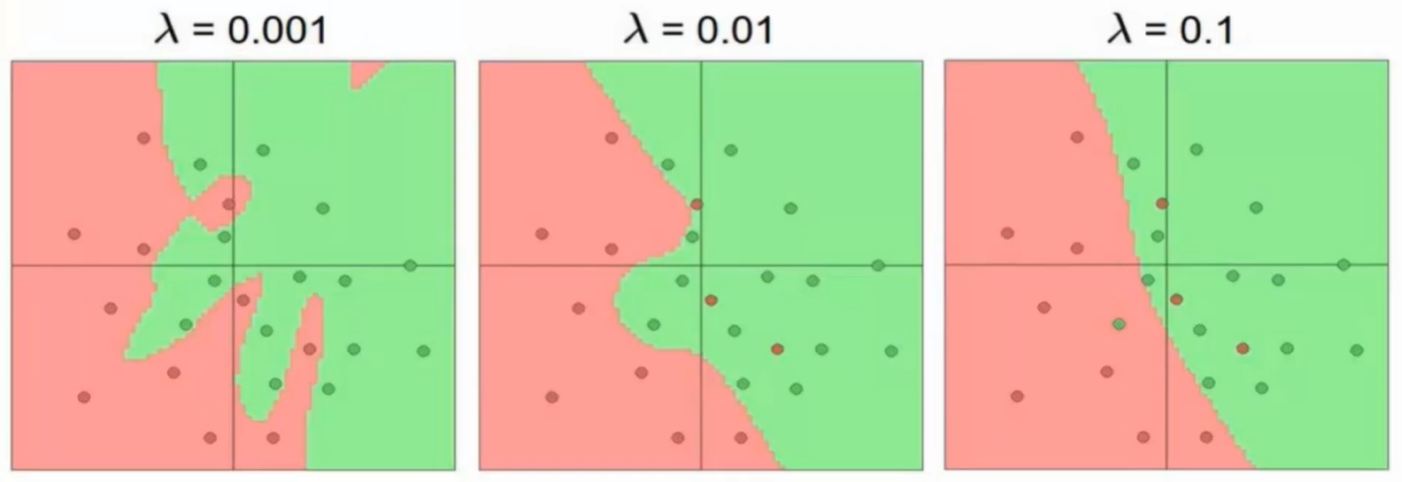
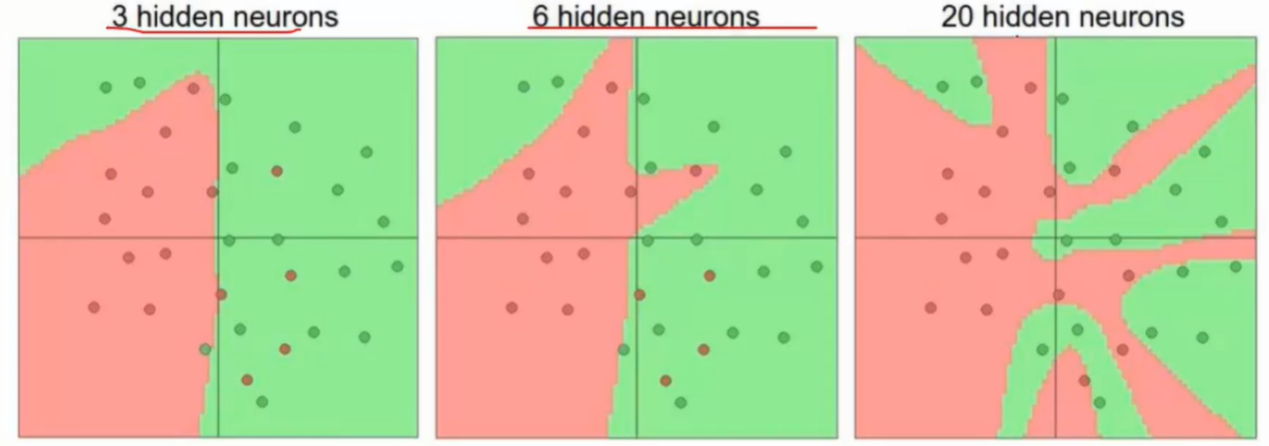
-
完整的层结构
数据预处理
权重初始化
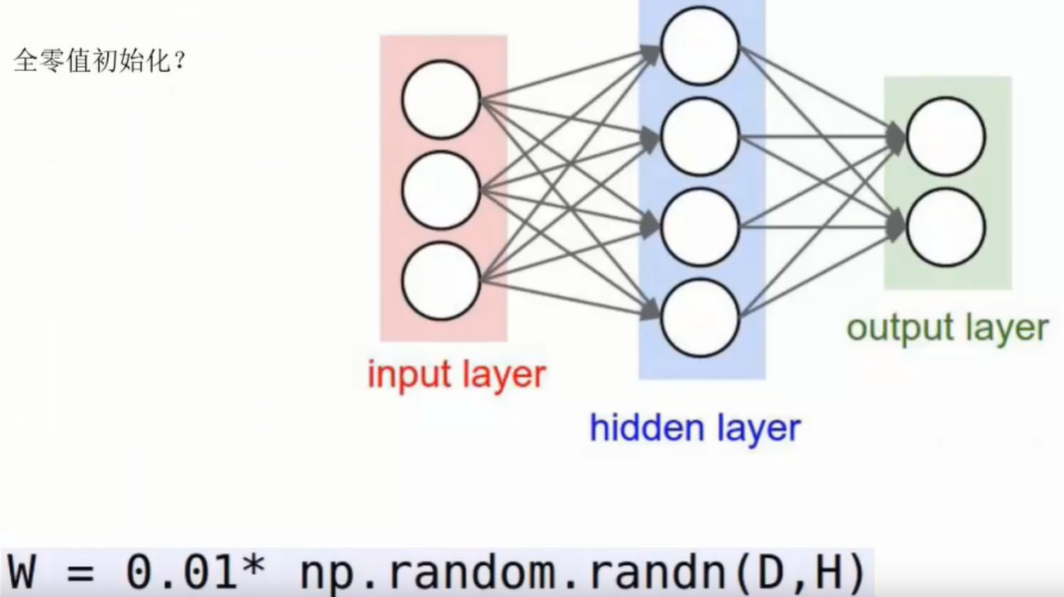
开始时对权重参数取随机值,不能取零值均值
-
DROP-OUT
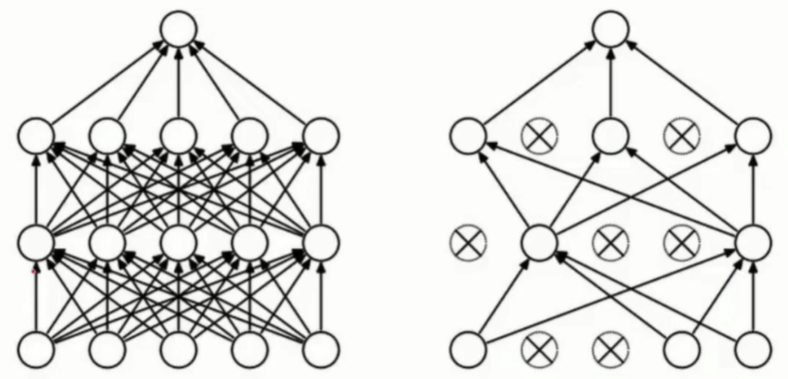
全连接操作运行慢且复杂
- Drop-out策略,每次传播随机选择一定数量的元计算,可指定Drop-out率
- 可削减神经网络规模
-
Python实现
-
线性回归
神经网络
两层神经网络
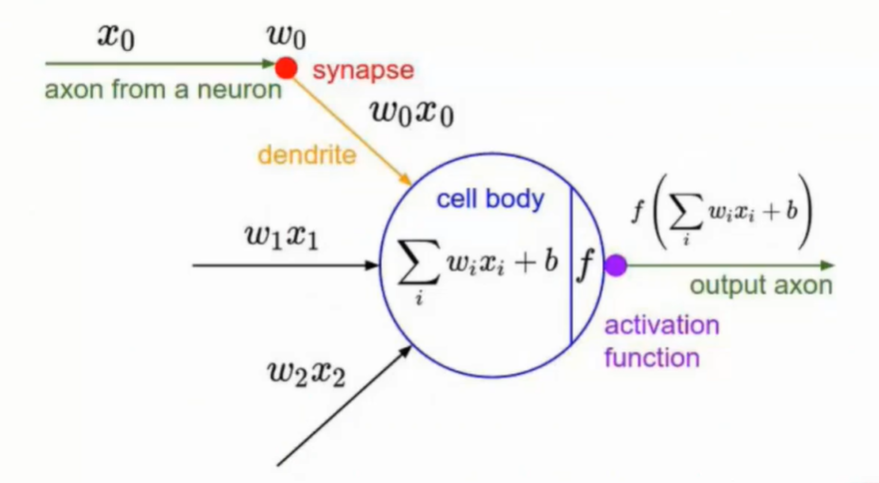
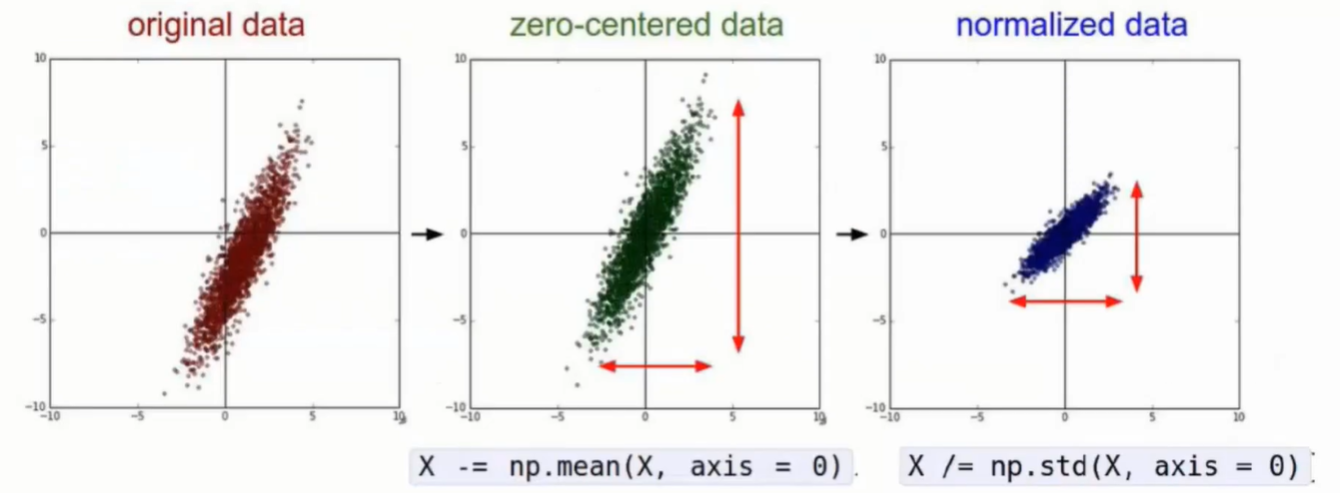
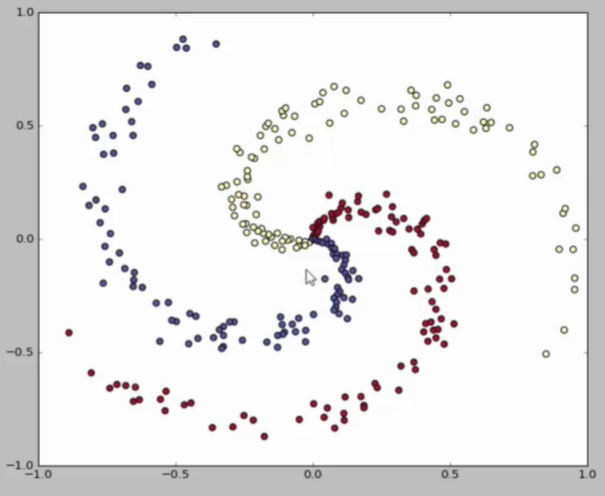
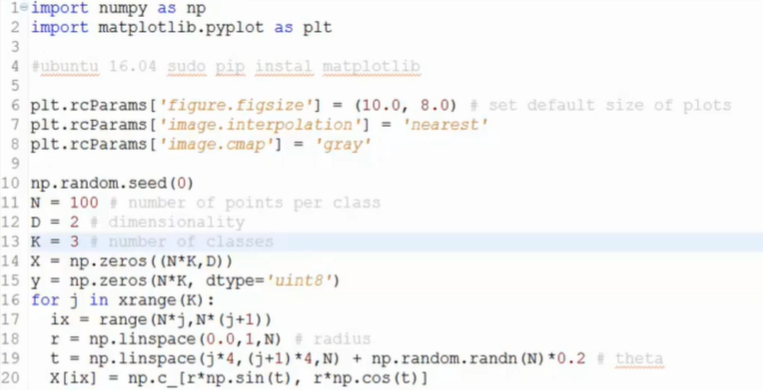




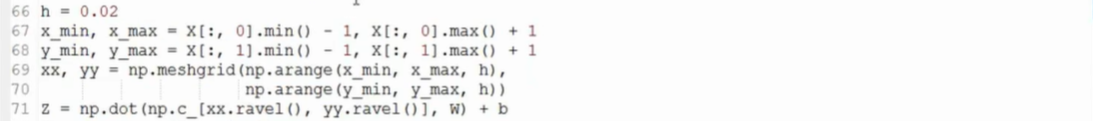

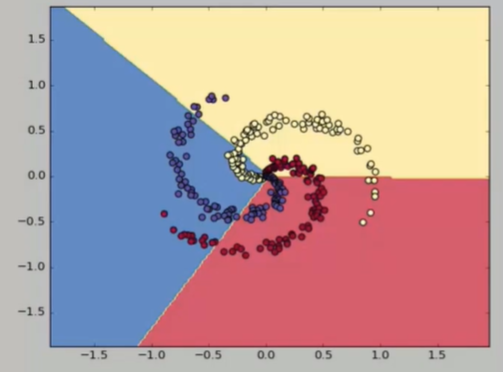

替换上图片部分区域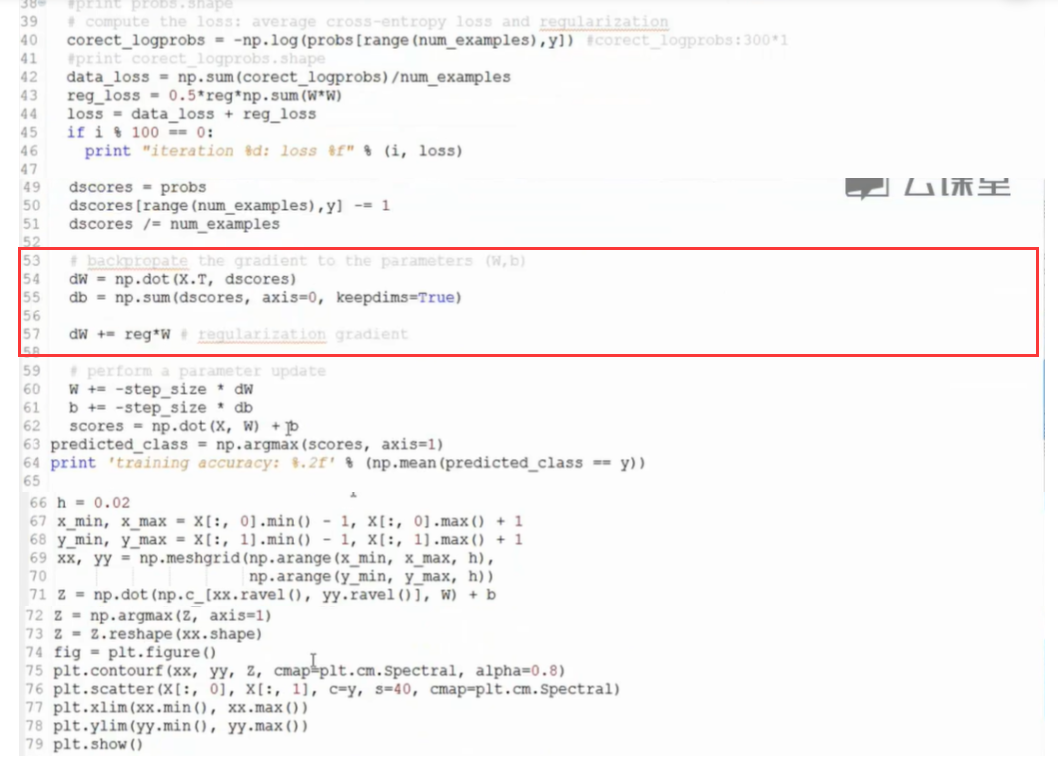

若有收获,就点个赞吧
0 人点赞
