导入数据
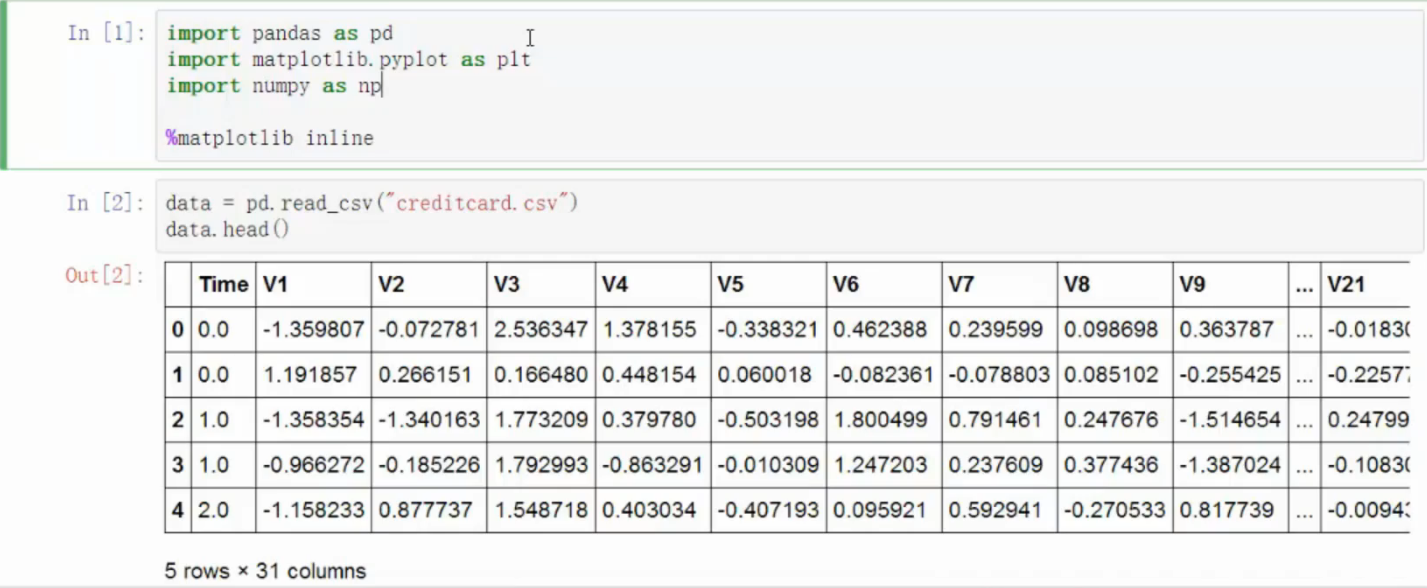
- 银行数据,信用卡的欺诈检测,特征无名称,已经过特征压缩
- 输出值有较大的变动范围,需要标准化预处理
- 在数据中区分正常类(正样本)和异常类(负样本),执行二分法的分类任务,逻辑回归
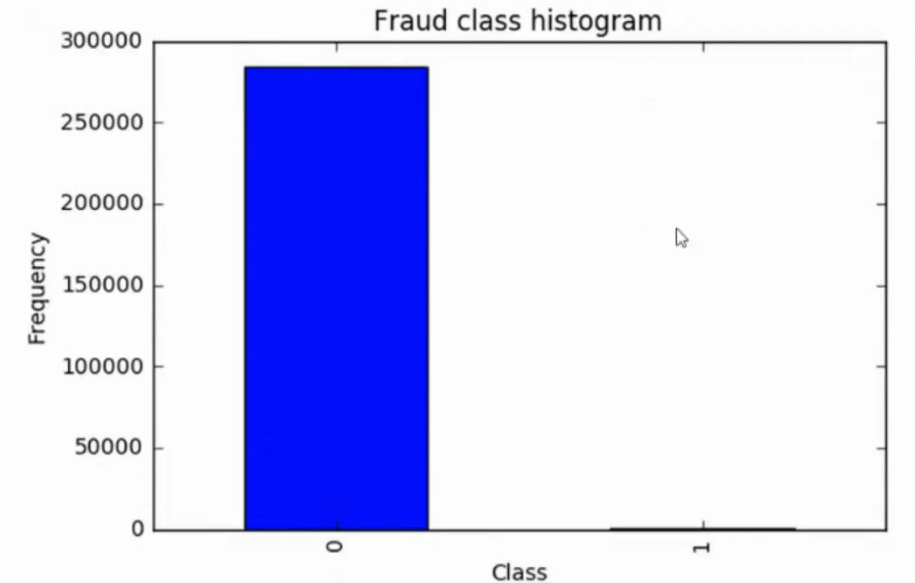
数据当中有可能绝大多数是正样本,极少数是负样本(偏斜类问题)
不均衡问题
先观察样本中的偏斜情况

- 可视化
- 两种方法
- 过采样,在较少的数据中采用一种生成策略,让少的数据和多的数据一样多
- 下采样,在较多的数据中选出和较少的数据一样多的量输入到分类器中(使得两个数据同样少)
预处理
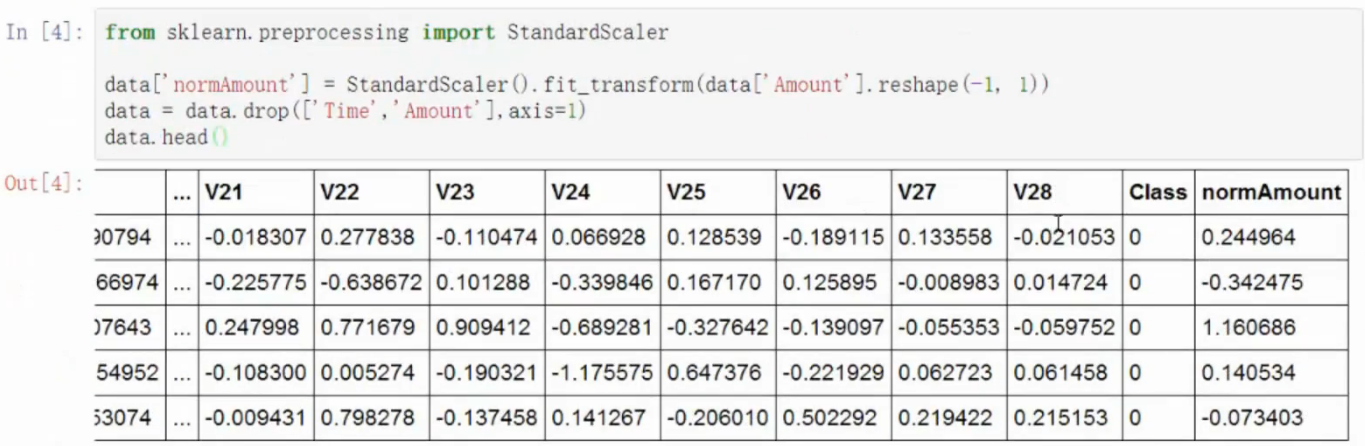
- 机器算法如果不经过预处理会存在误区
- 较大的数据更重要
- 理应重要程度相等
- sklearn库提供函数,preprocessing预处理模块,standardScaler标准化模块,fit_transform变换数据的方法
- from 导入文件,import导入集中的某一个类
- 如果直接import文件,会把文件所有的类导入
-
下采样
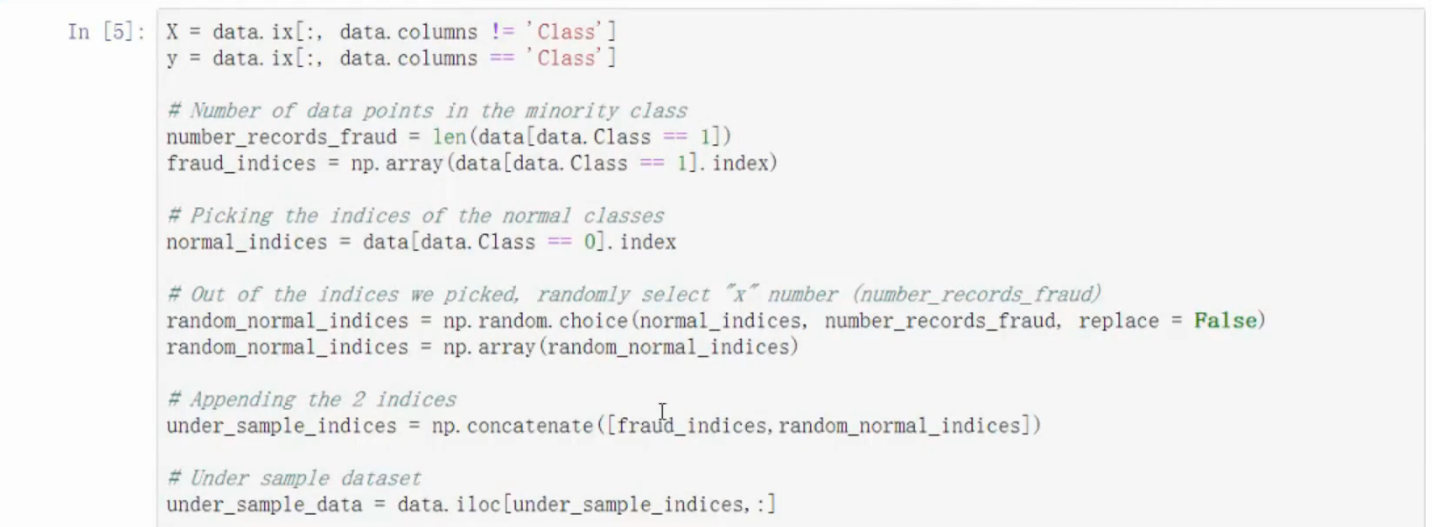


分离标签和样本数据
- 在较多的数据中随机选择和较少的数据的数目相同的样本数
- .concatenate合并数据
-
交叉验证
切分样本数据
- 训练集、测试集(8:2)
- 训练集平均分三份(1:1:1)
- 训练集中选取1和2,验证3;选取1和3,验证2;选取2和3,验证1(求稳策略,求平均效果)
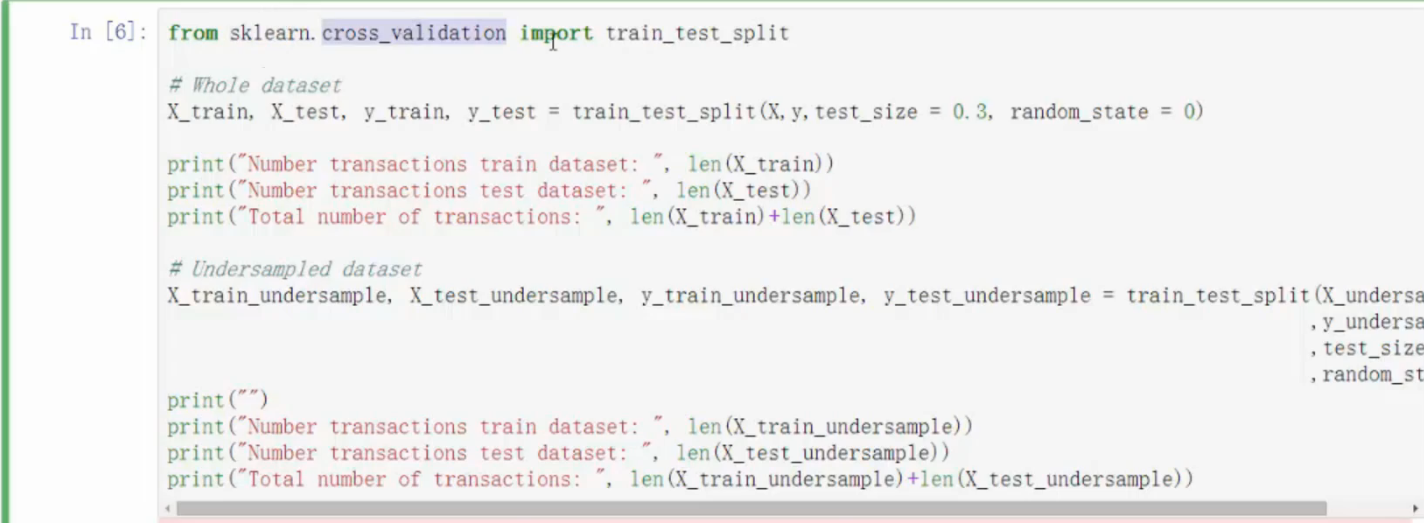



- 召回率表达式
- 导入其他机器学习的库
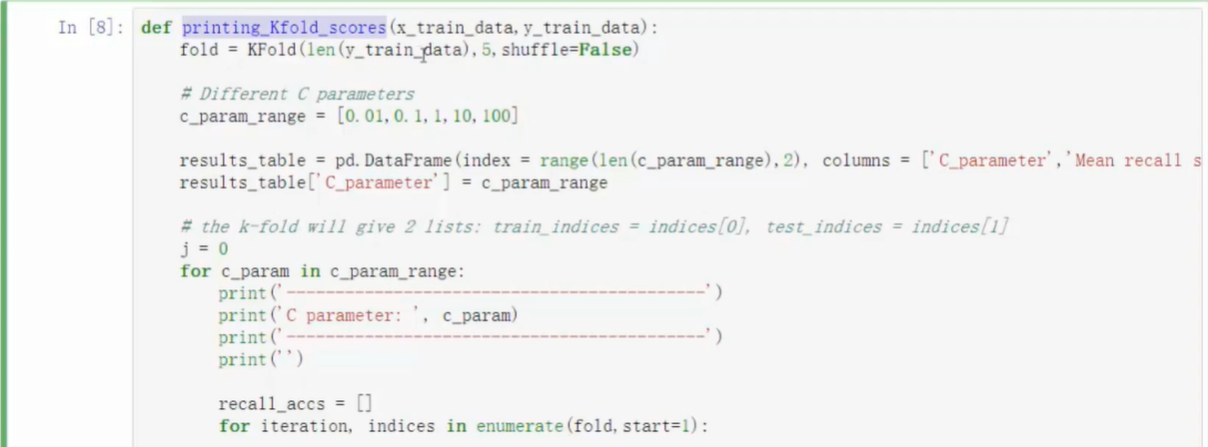
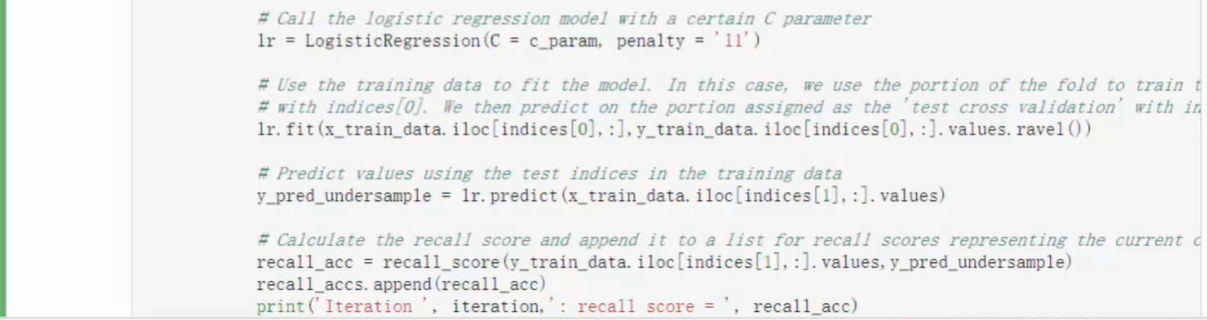
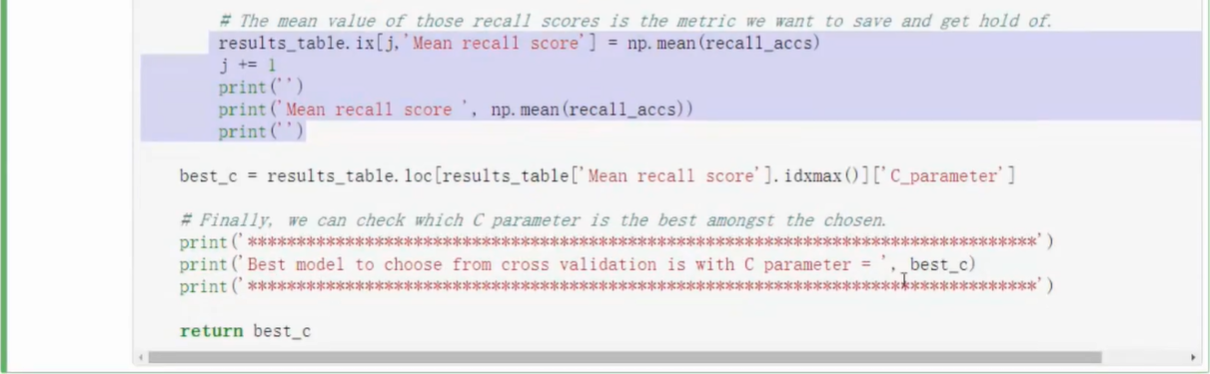
- KFold函数可指定交叉验证将原始数据集切分为几个部分
-
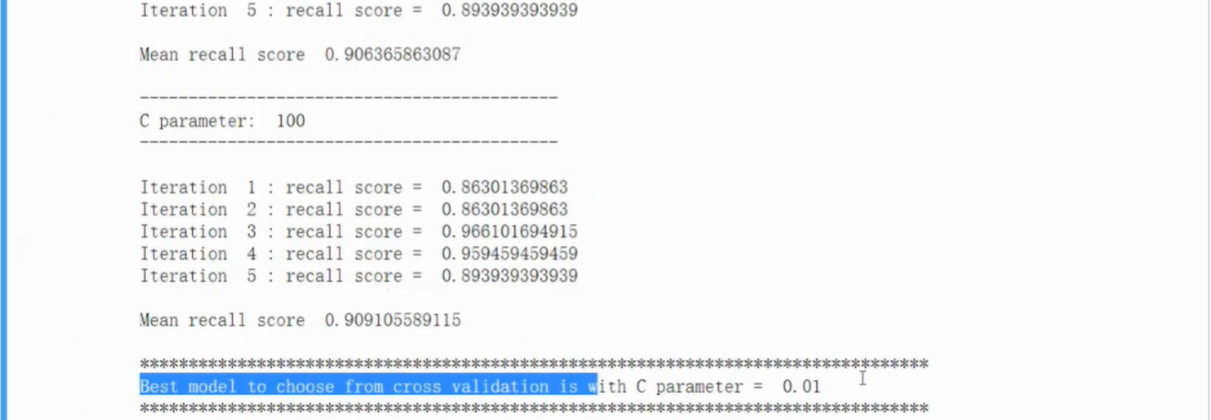
正则化惩罚项
相同评估结果的模型选择参数模型稳定,泛化能力强的模型
- 避免过拟合现象
- L2正则化,代价函数加上1/2 w^2
- L1正则化,代价函数加上 |w|
- 正则化参数 λ

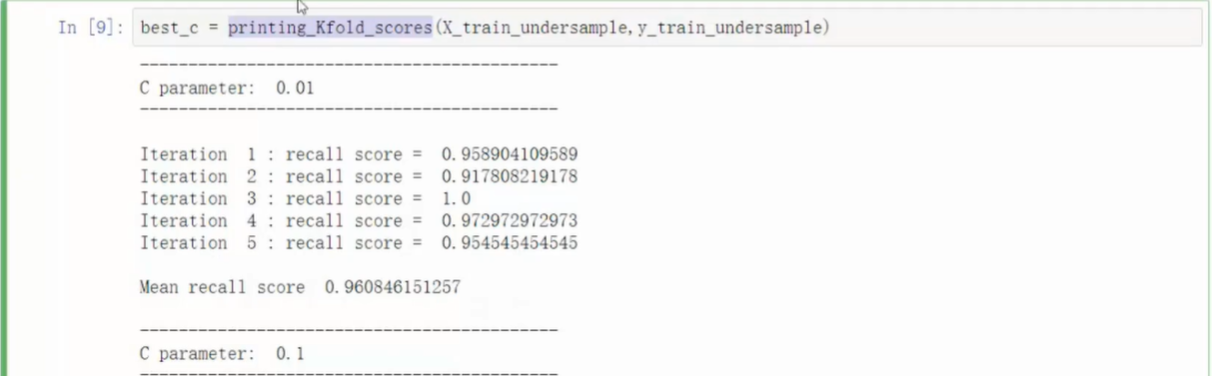
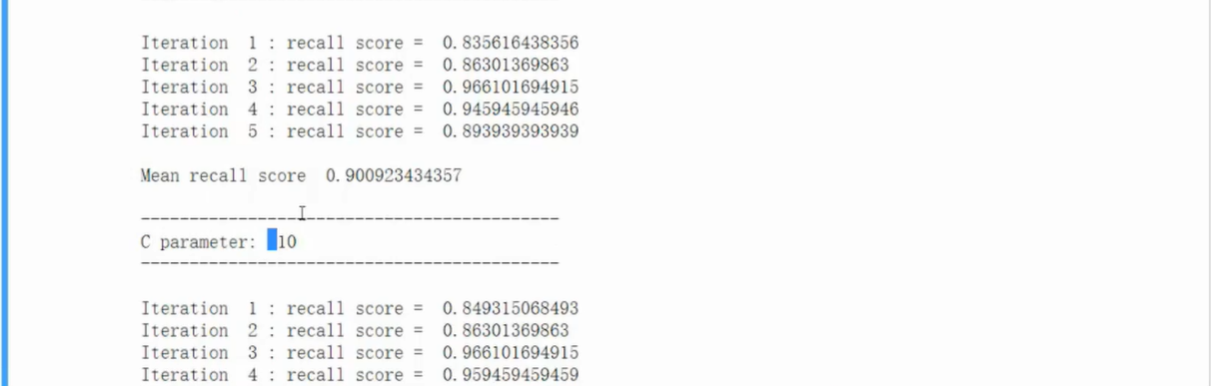
训练
- 代码中使用了两层循环,外层循环寻找最佳正则化参数,内存循环实现交叉验证
- 直接调用库中的模型函数,填入参数
- .fit函数训练
- …….

混淆矩阵
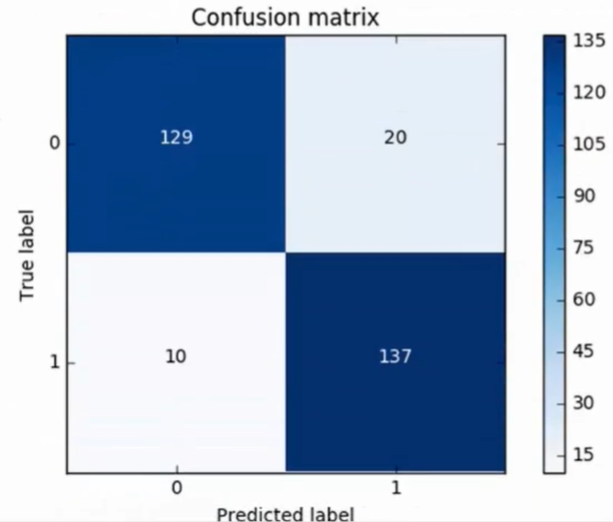
- 可计算精度, 查准率/召回率
- 此为下采样测试集测试结果
- 还需要在原始数据集中操作
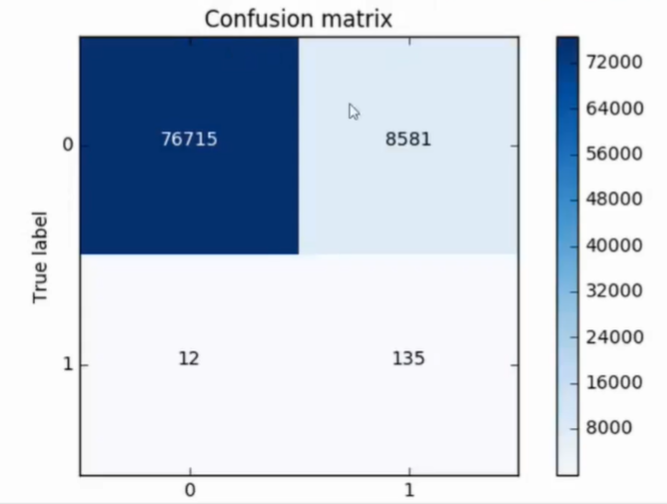

- 效果很差
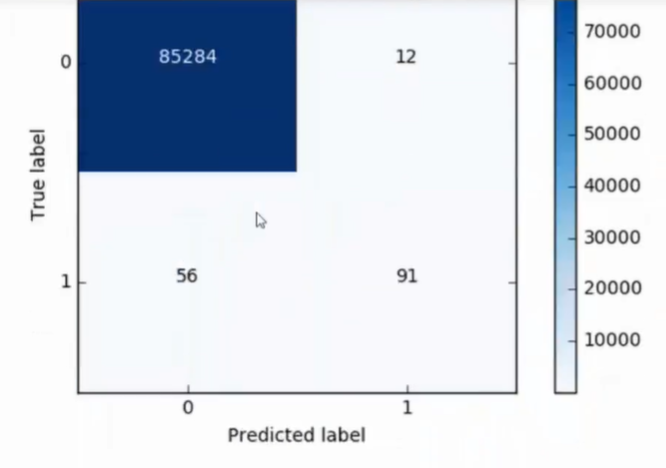
修改概率模型
- 修改Sigmoid函数的判决门限(阈值)
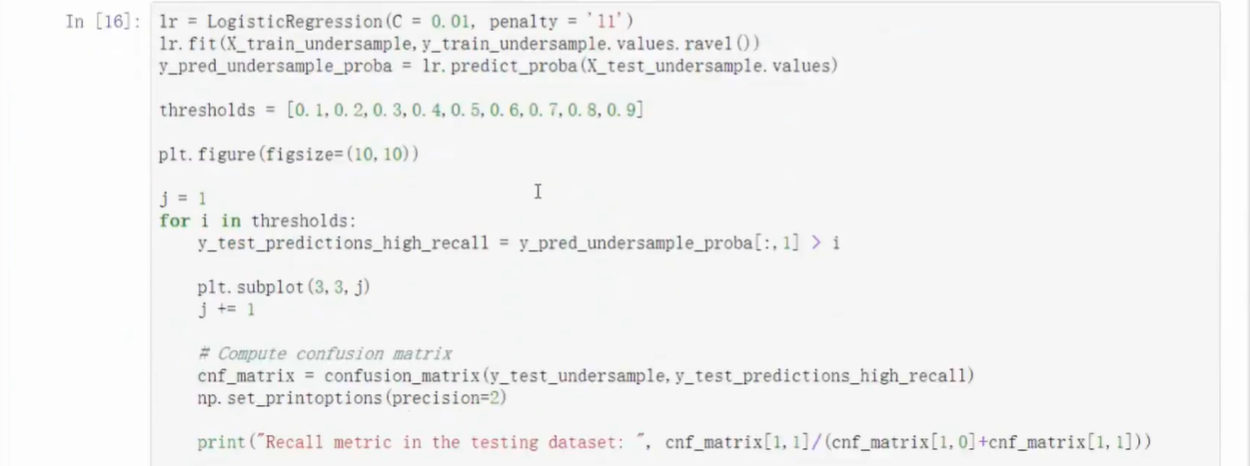
- predict_proda可修改预测模型参数


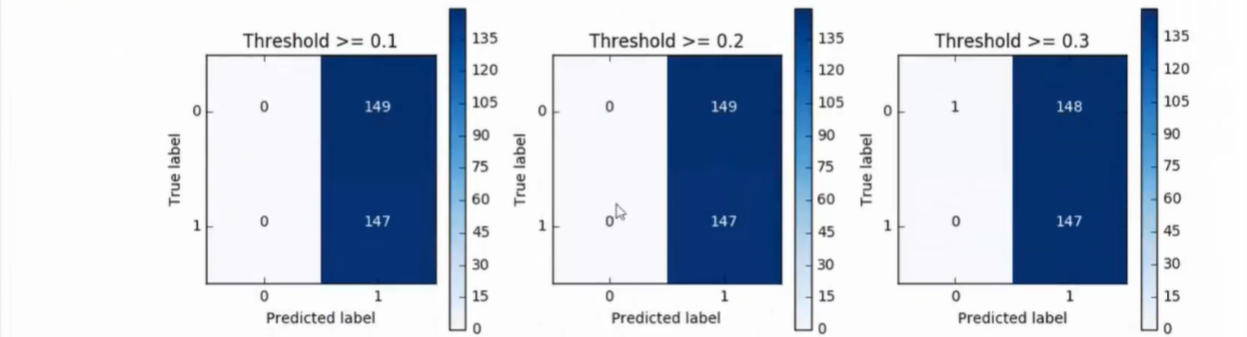
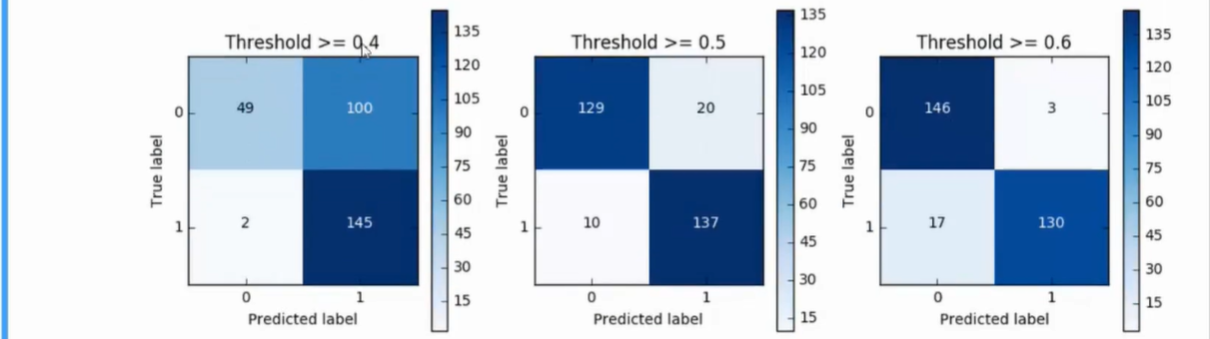
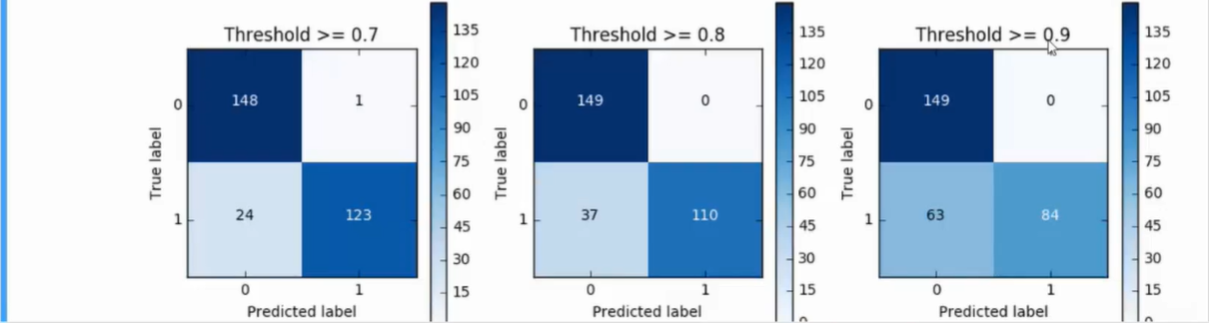
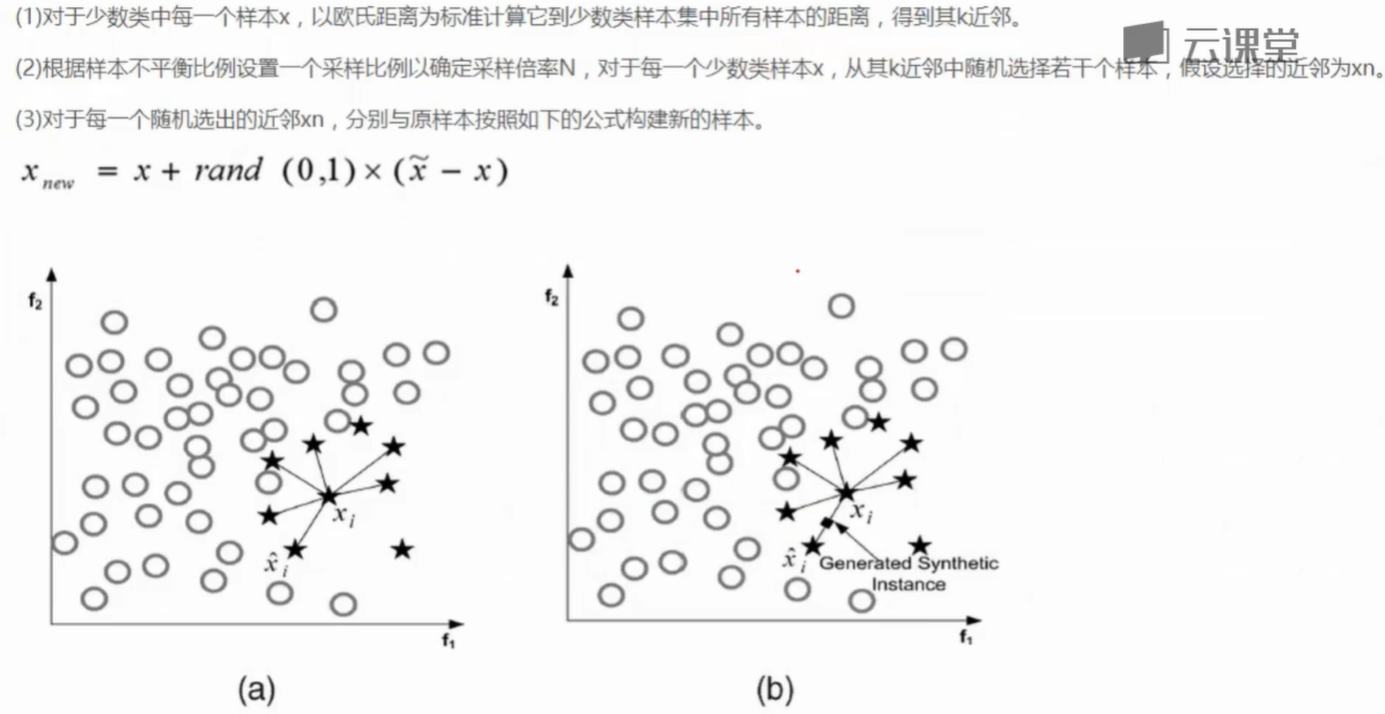
过采样
- SMOTE样本生成策略
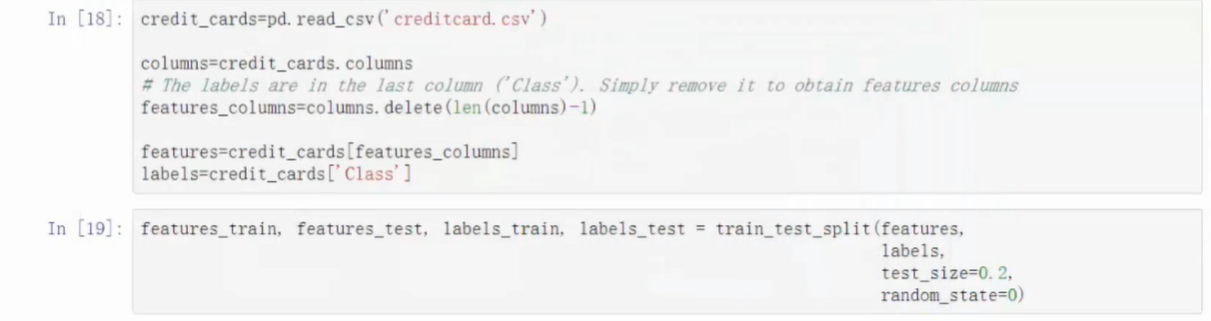
- 导入库

- imblearn模块
- 安装
pip install imblearn - 引入过采样模块
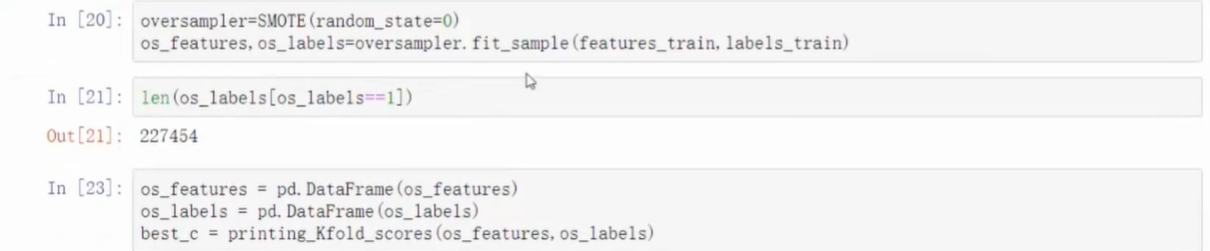
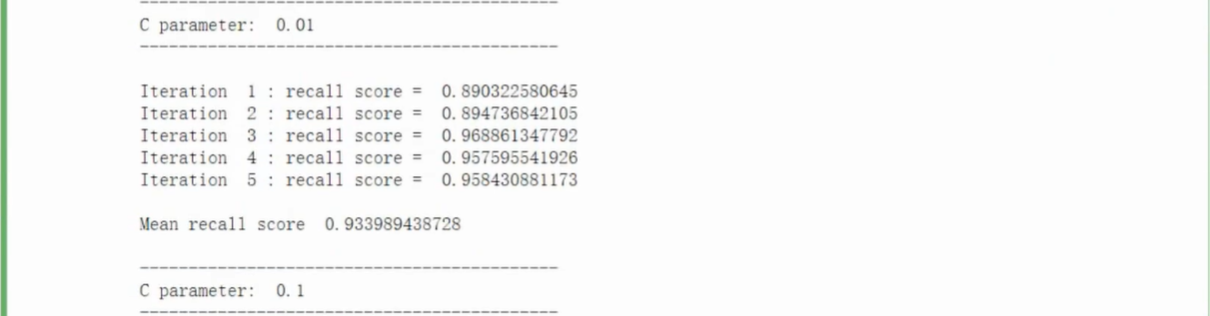
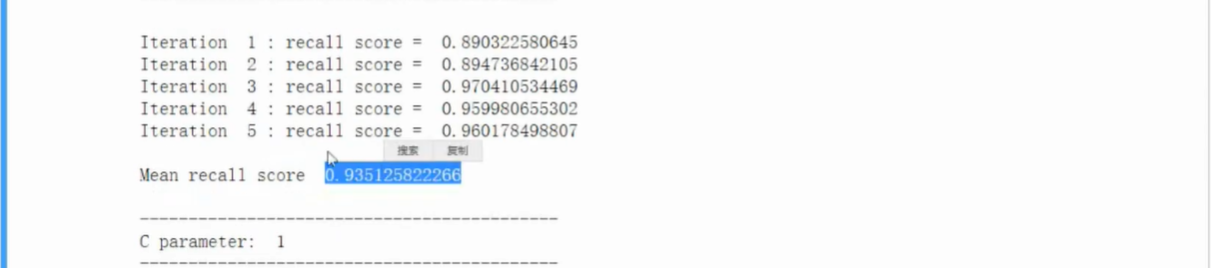
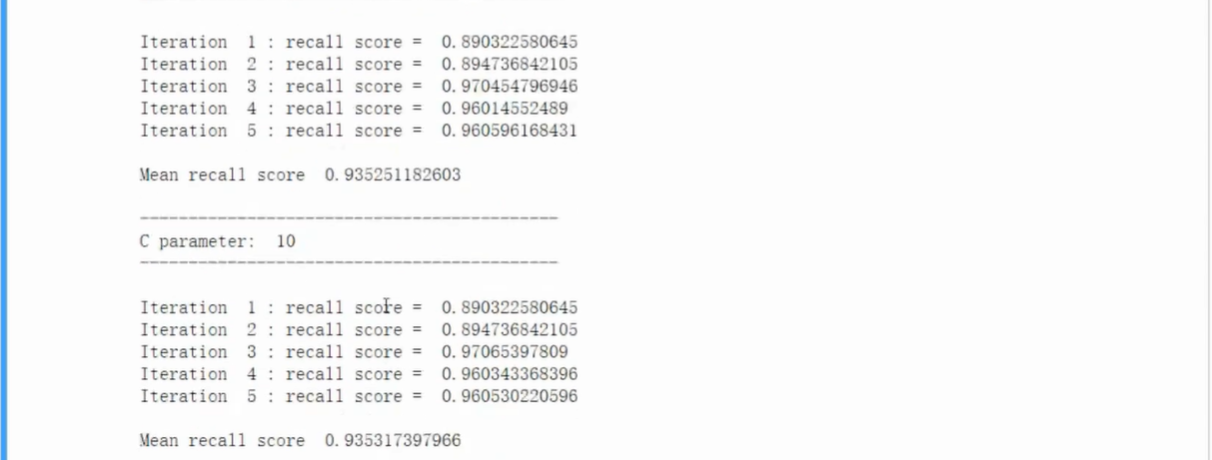
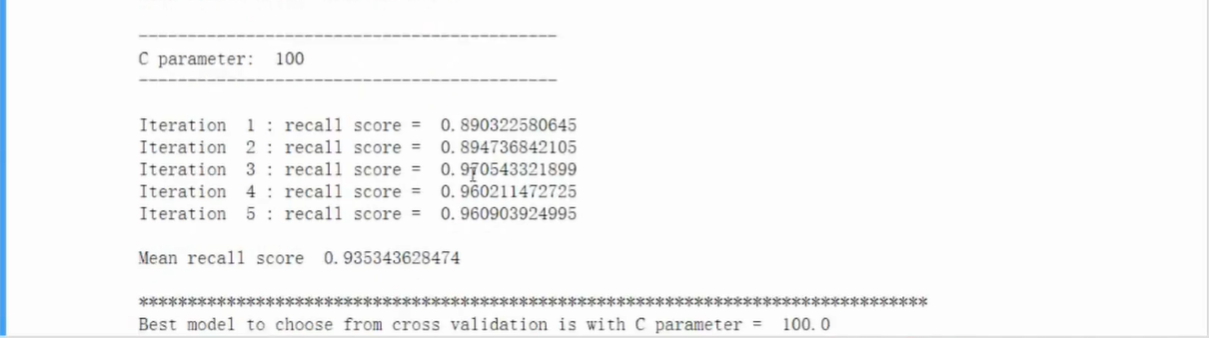
- 观察混淆矩阵
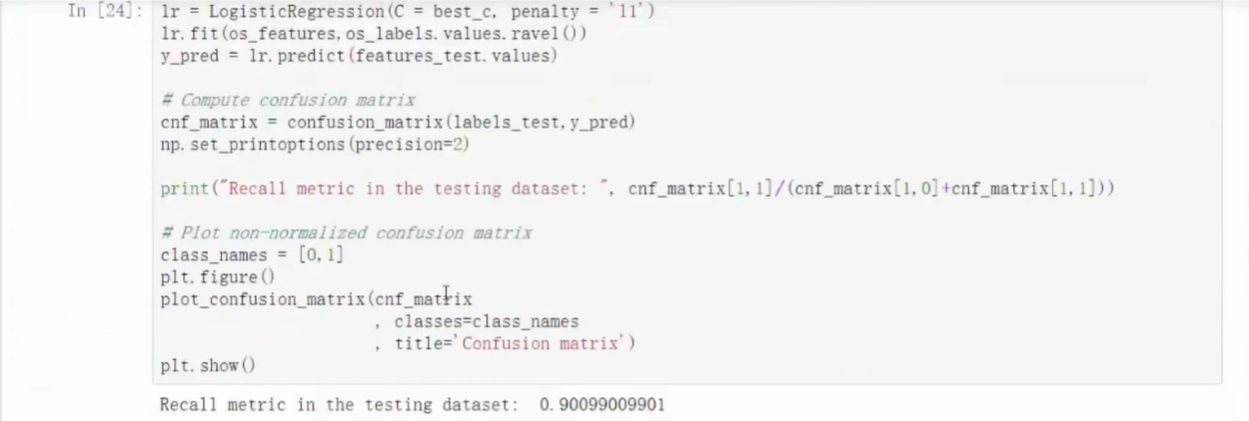
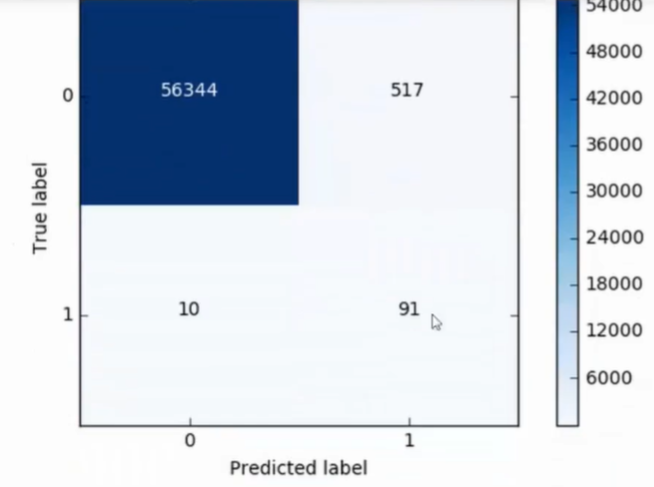
- 通过过采样得到的误杀率大大降低
- 计算能力满足的条件下,尽可能选择过采样

若有收获,就点个赞吧
0 人点赞
