树模型
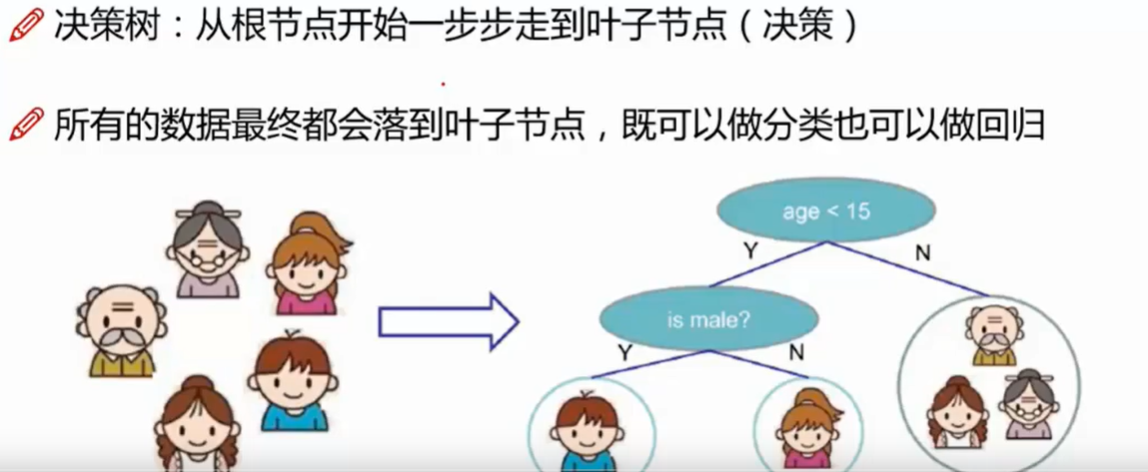
- 多分类任务
- 树的组成
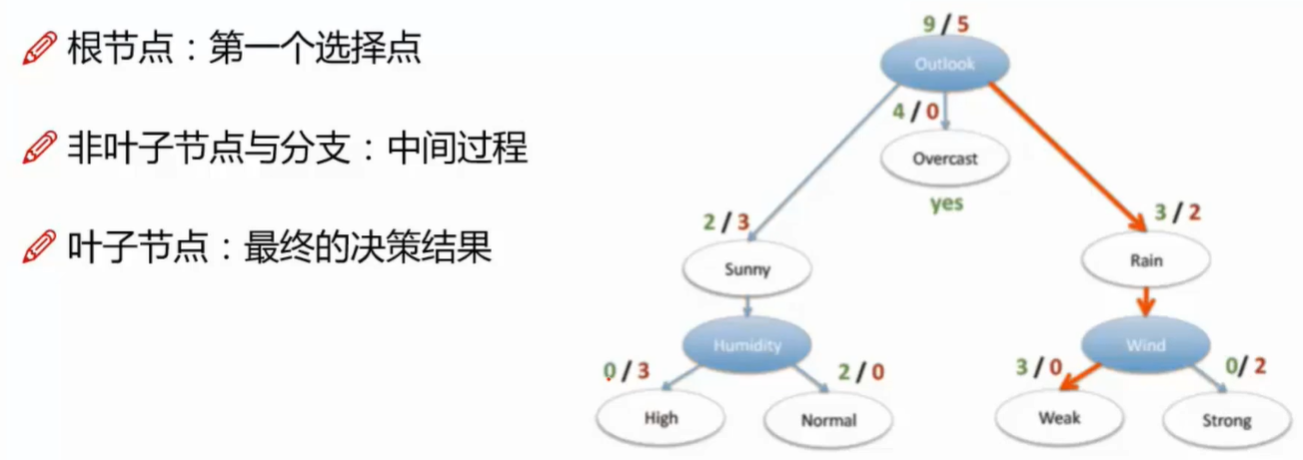
- 节点

- 训练和测试

- 切分特征(选择节点)

衡量标准(熵)

- 目标是得到熵值逐渐降低的分支

构造实例
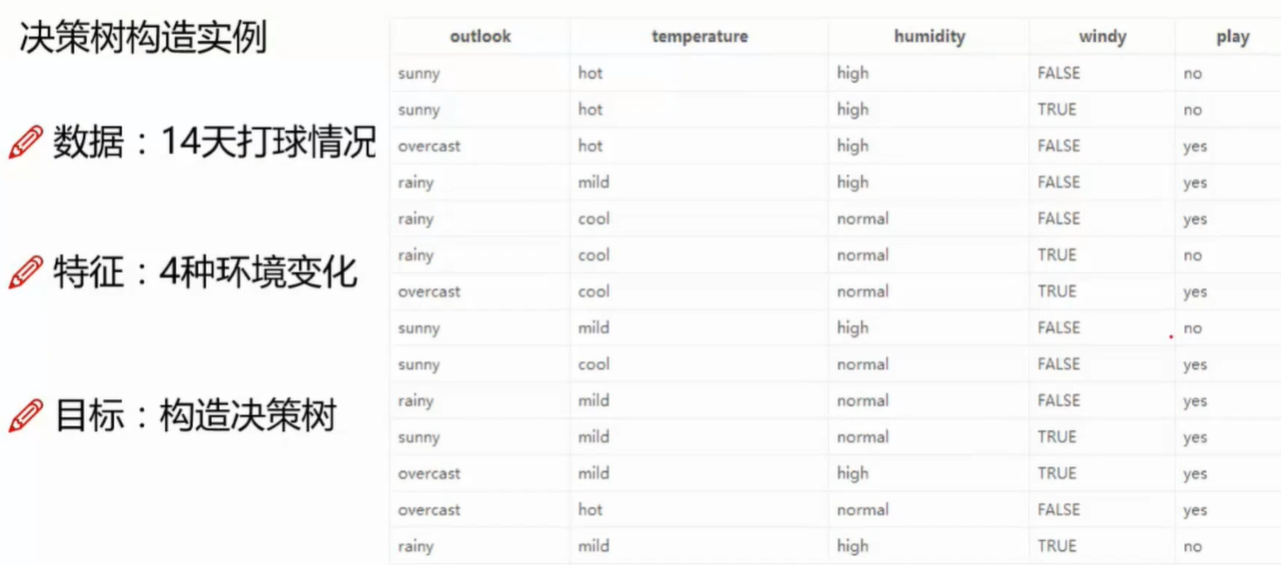
- 开始并不知道要用哪一个特征做节点开始分类,所以每一个都尝试一遍
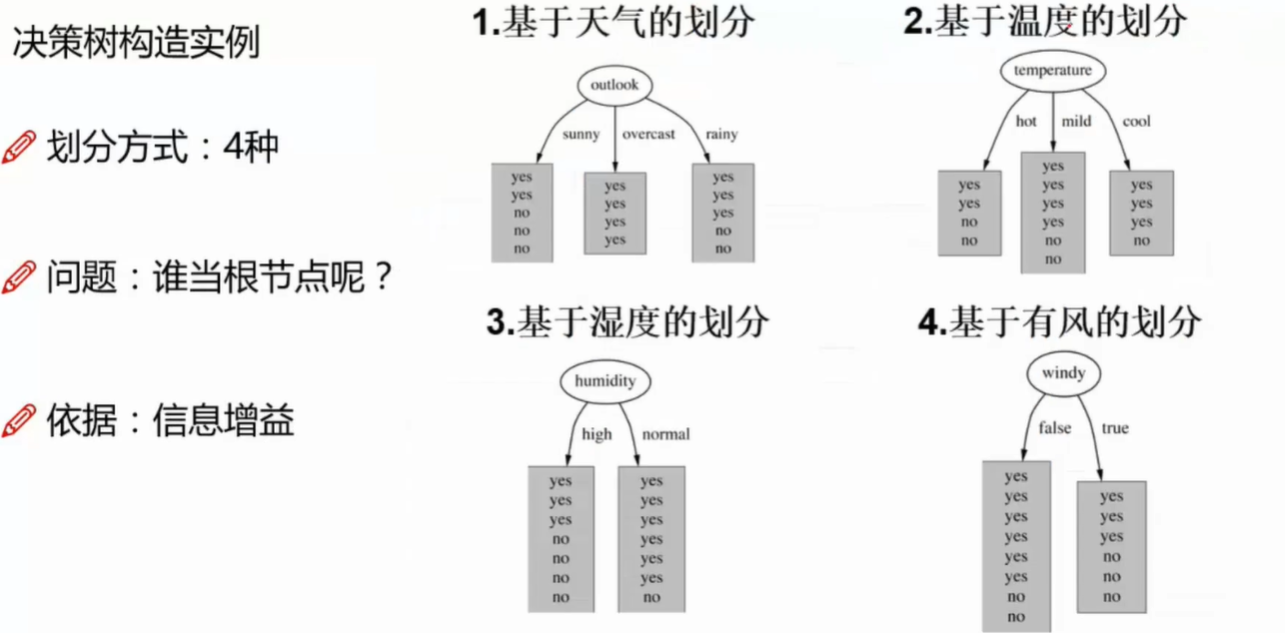
- 如果以天气划分计算



- 如果将每一个样本的ID当作特征分类,最终的节点只有一个样本,信息熵为0,增益达到最大,计算时会把ID当成特诊考虑进去,存在问题
- C4.5算法用自身熵实现标准化
- CART算法不使用熵值,而是使用GINI系数
处理连续值
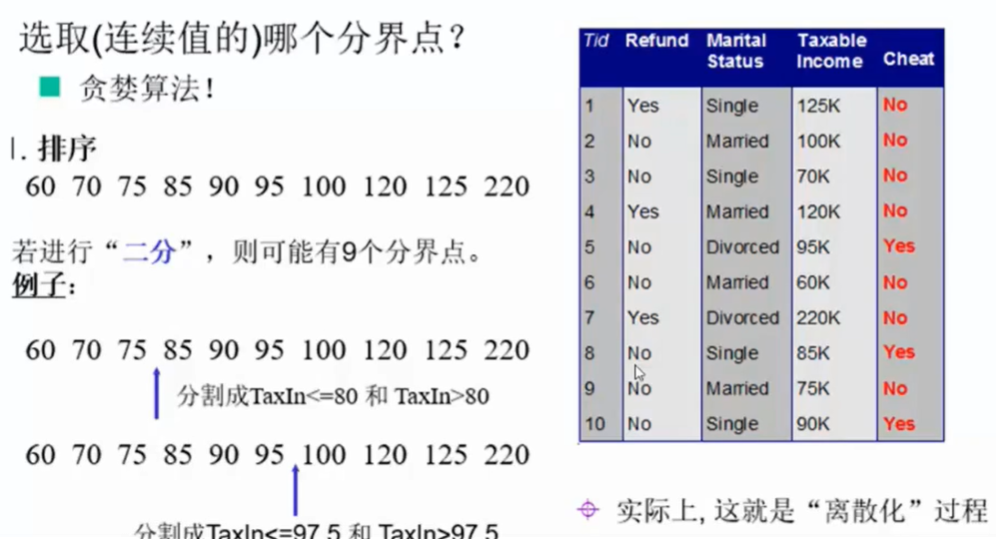
决策树剪枝

- 避免深度太大,计算过程中对特征的取舍
- 预剪枝使用更多,可以简化模型

- 后剪枝的衡量标准C(T)为每次迭代中每个叶子节点的损失(样本个数 * GINI系数/熵),通过α|T_leaf|限制叶子节点的个数,α越大,越限制叶子节点数不能太多,通过对比分裂还是不分裂处理后的损失来决定是否减去向下的分支
- 决策树更方便实现可视化的展示
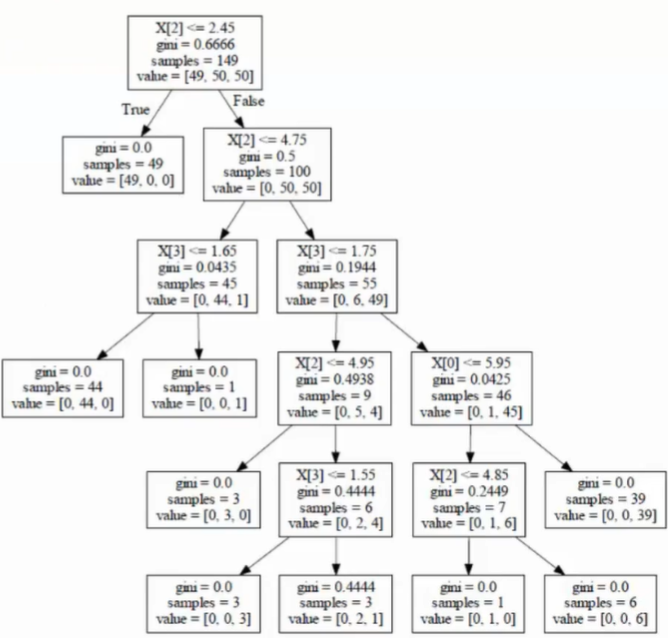
Python实现
- 导入模块
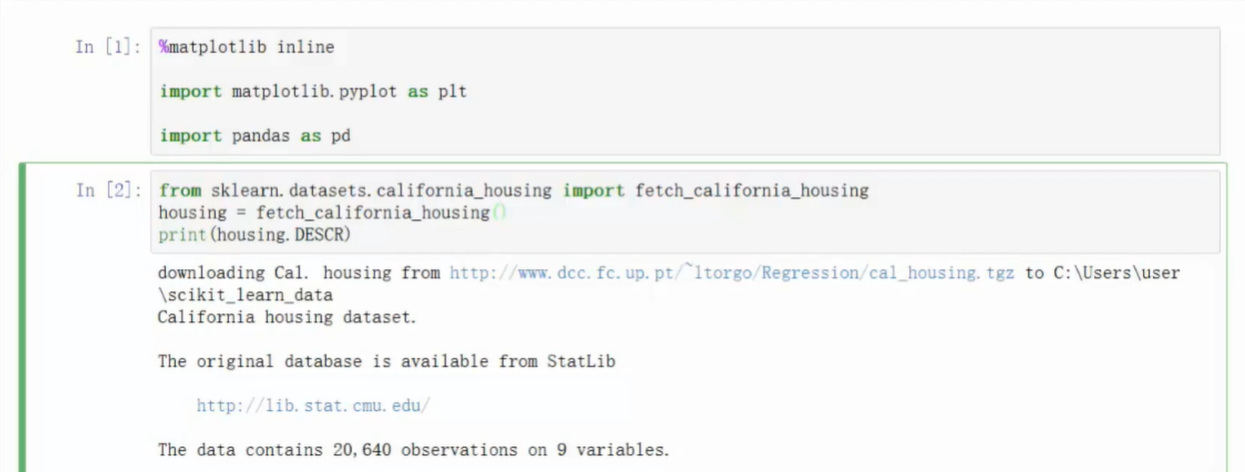

- datasets为sklearn的内置数据集
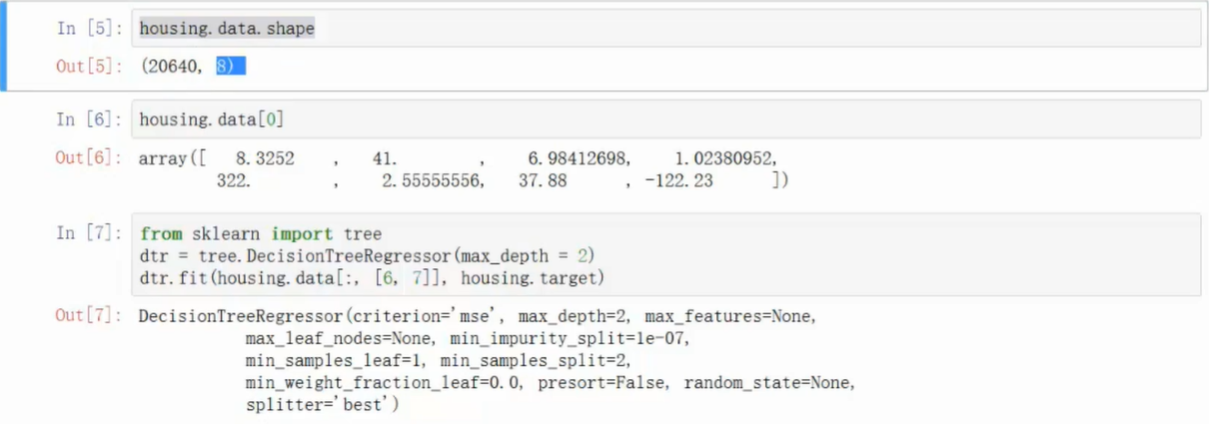
- 导入房价数据集


安装可视化工具
- 访问网址
- Download标签
- 根据系统选择版本,下载exe文件安装
- 然后运行上面的代码,会生成一个.dot文件

- 再安装pydotplus模块
- 还需要外部安装Graphviz模块,详见第一节Anaconda
- 需要使能dot插件,命令行键入 dot -c
- 可修改颜色等
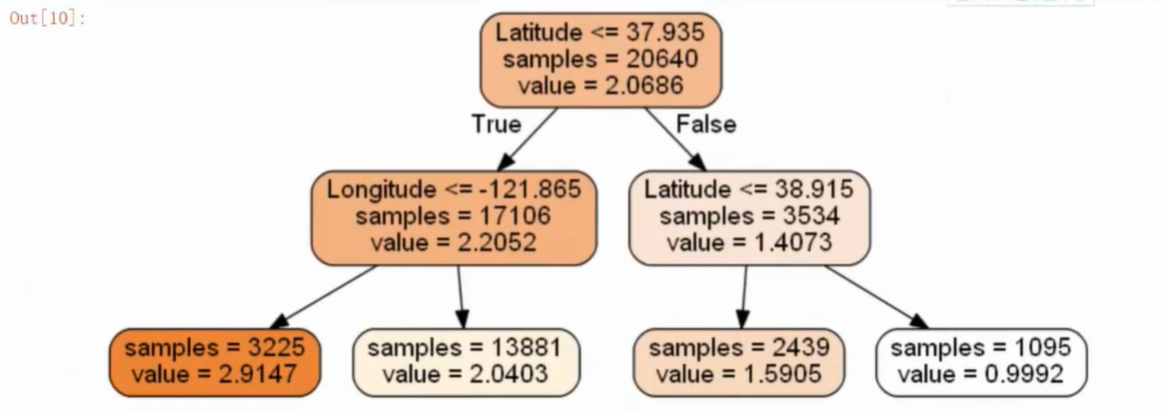

-
数据切分
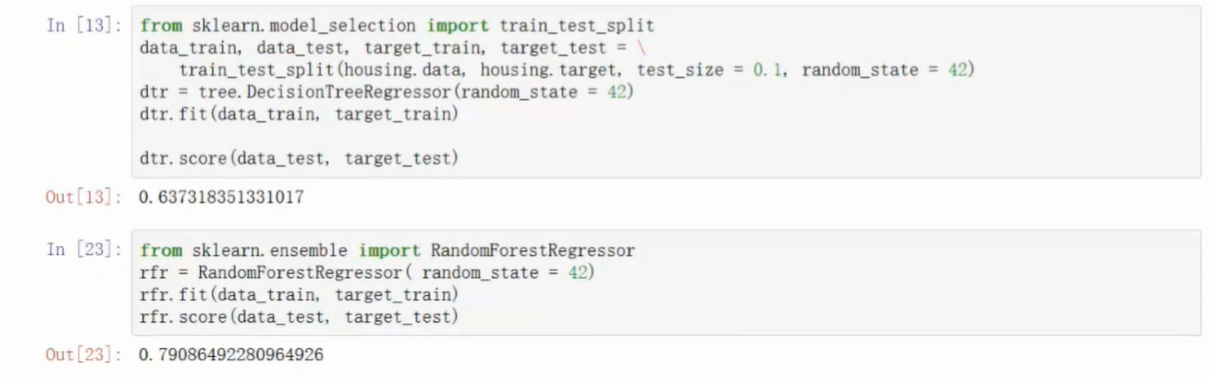
random_state随机数种子,方便对比效果复现时能生成相同的随机数参数选择
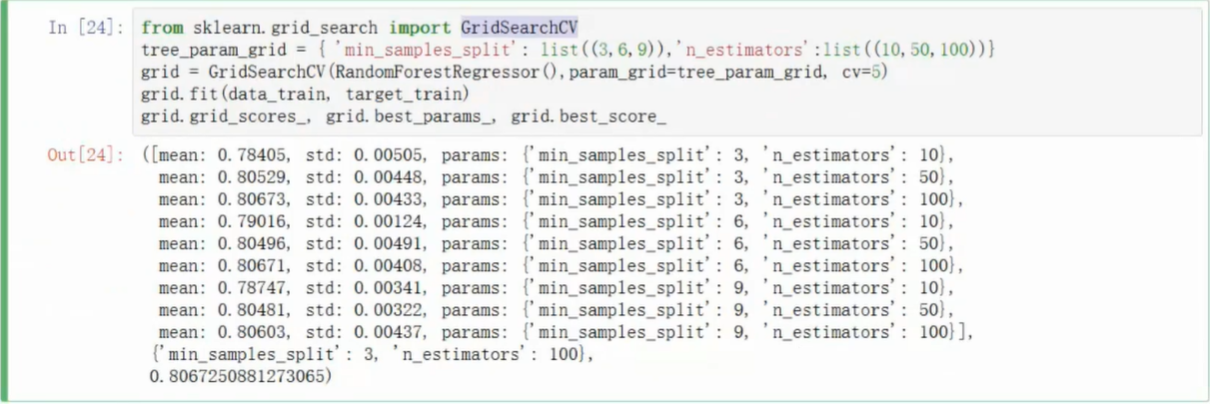
可以帮助实现参数的自动遍历,方便进行参数的选择
- GridsearchCV模块
- 将待选参数写成字典的格式
- GridSearchCV函数带入模型函数,参数字典,cv指定进行几次的交叉验证(即拆分数据集份数)

若有收获,就点个赞吧
0 人点赞
