案例数据
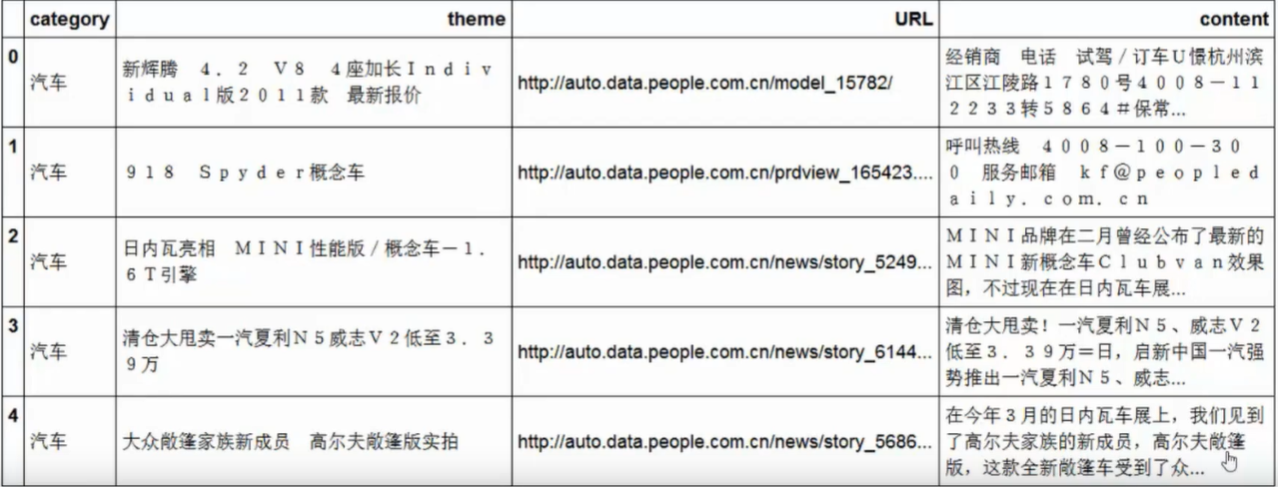
停用词



- 在所有的文档库中出现这个词的个数

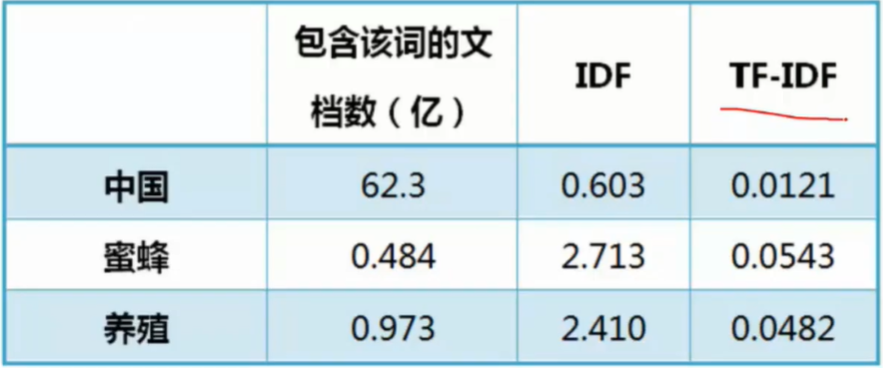
相似度


- 存在缺点,词频破环了原来的语义
- 可以考虑wordIvec Gensim
Python案例
-
数据导入
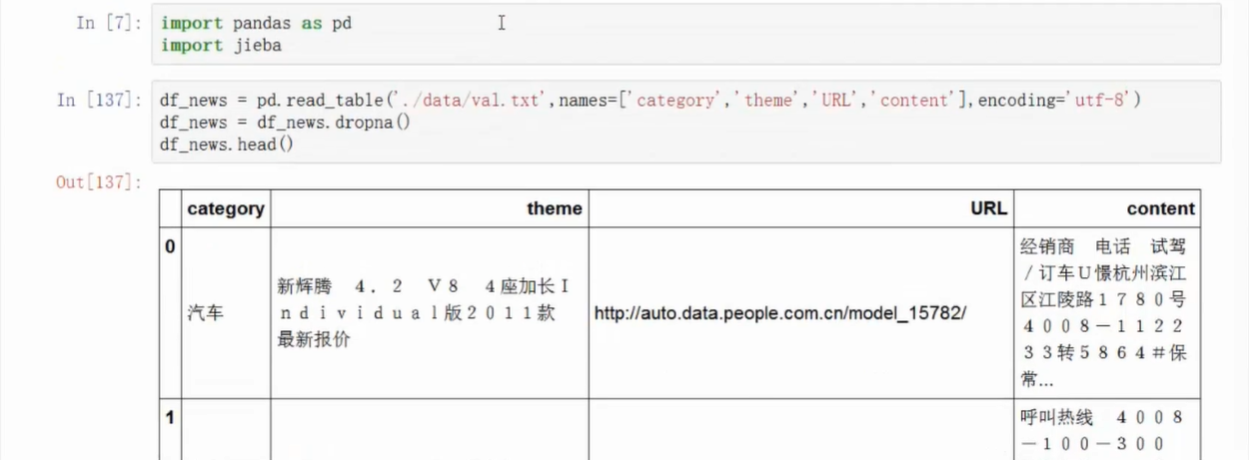
数据库来源:搜狗实验室
- http://www.sogo.com/labs/resource/ca.php
- 仅用到了一小部分

- 直接去掉缺失值

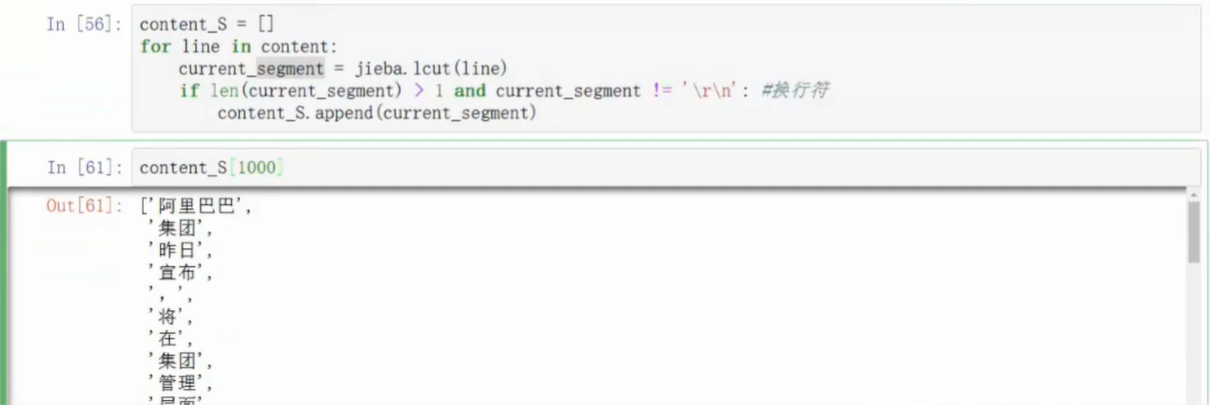
分词
- 使用结巴分词器
pip install jieba

- 先进行数据转化,转换为list格式,分词器要求
数据清洗
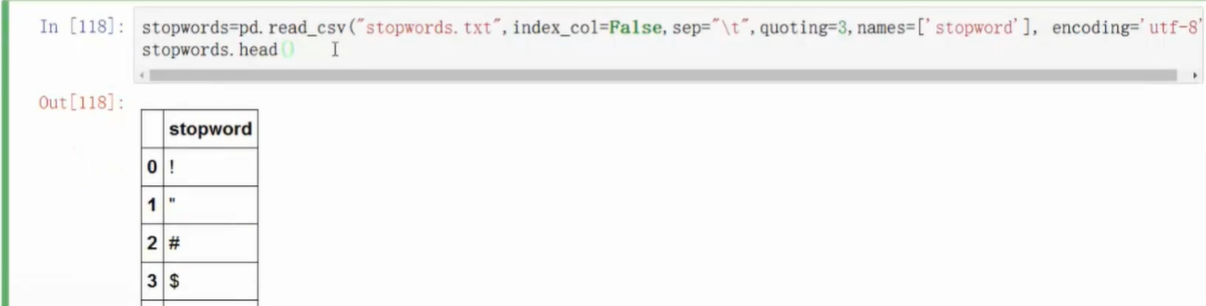
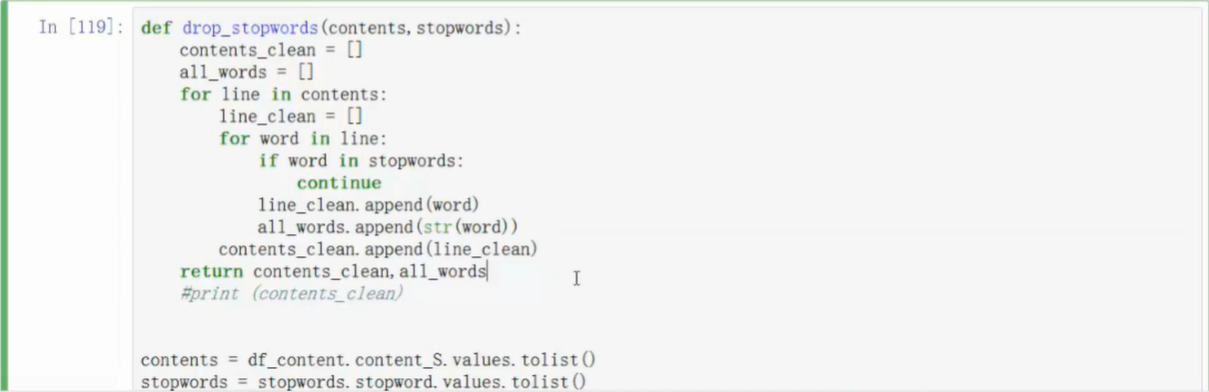
- 去掉停用词
- 可以在网上下载停词表


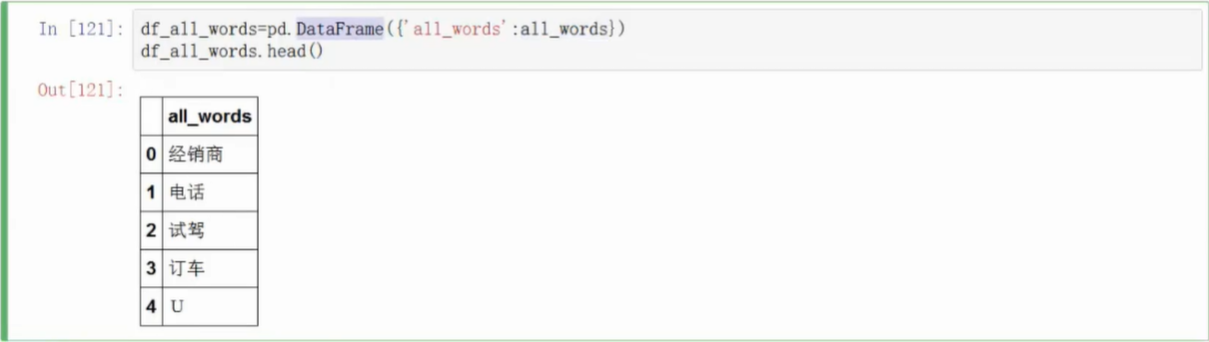
计算词频(Wordcloud)



- 需要安装Wordcloud的库

TF-IDF

LDA主题模型
- 不知道这些新闻有哪些主题可以划分
- 可以指定要划分类型的数量
gensim库(自然语言处理)

- 每一篇文章都必须分好词了

- 指定分类数目

- 打印第一类主题中最具代表性的五个词

- 打印所有的主题

分类准备
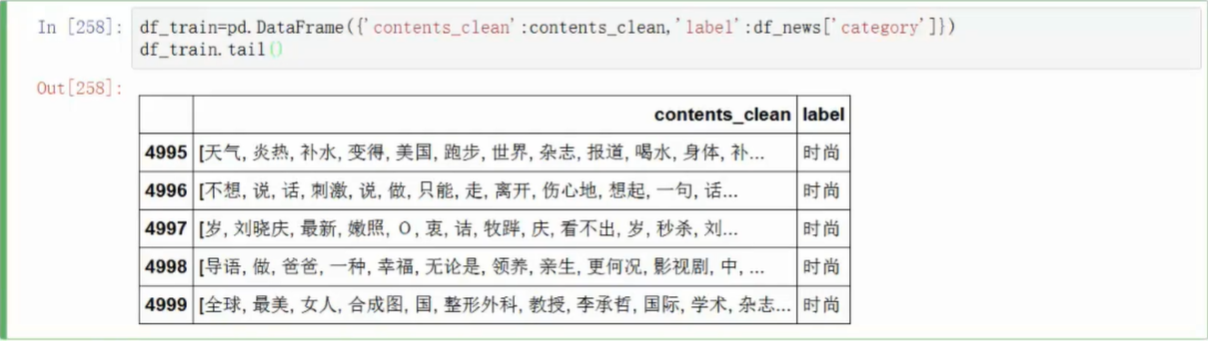
- 列举label中不重复的值

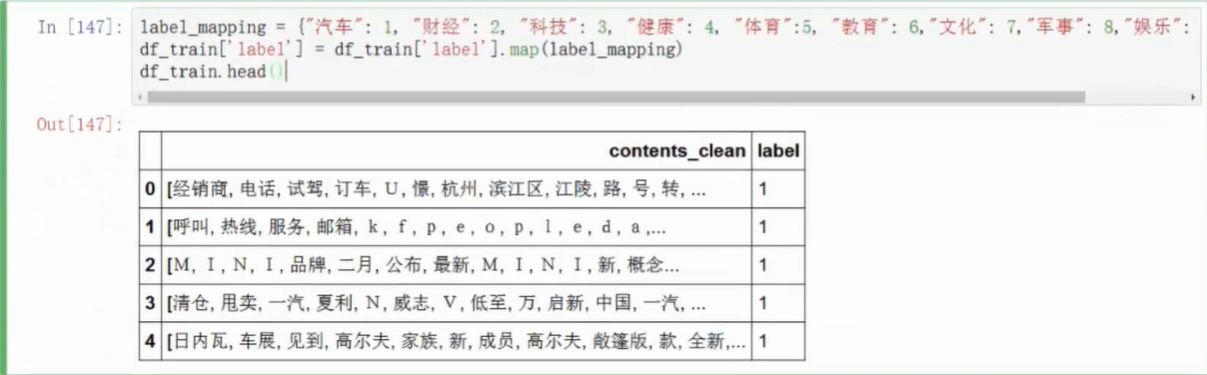
- 离散数据映射
- 划分数据集


- 向量映射举例
- 使用向量构造器
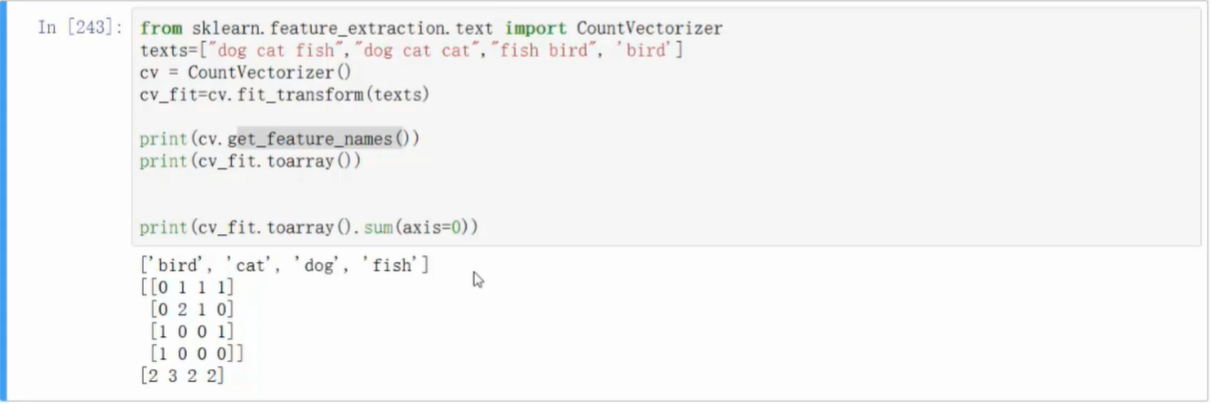
- 支持词的组合,使向量更复杂
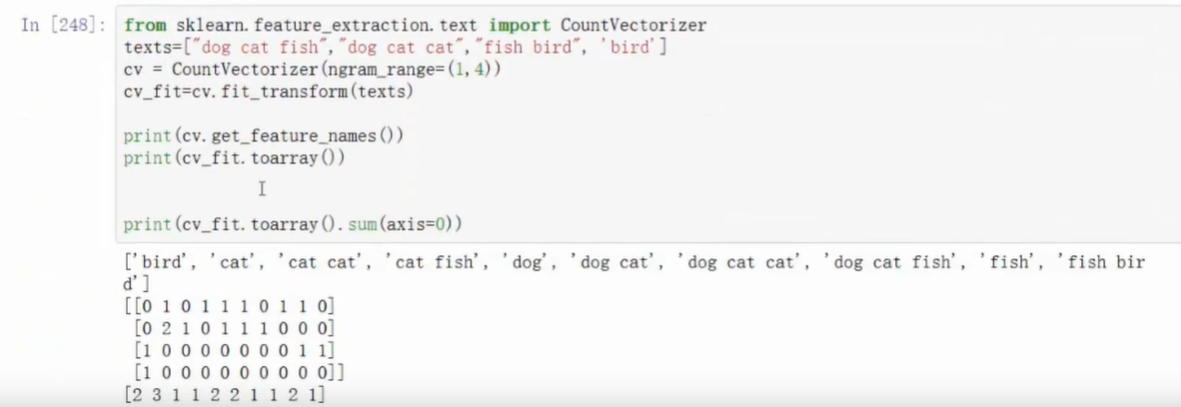
- 转换格式,list of list转成字符串组成的list
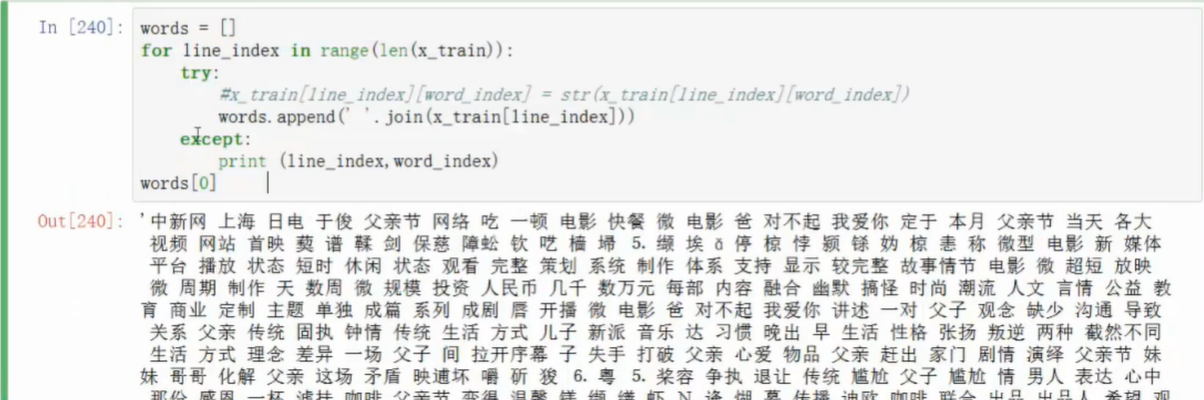

基本贝叶斯算法

测试
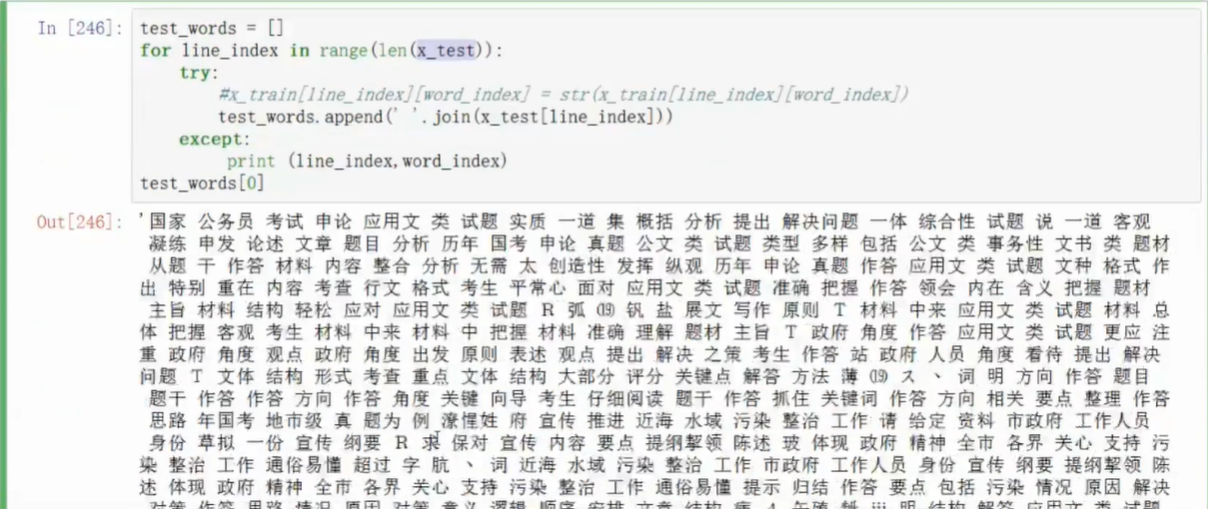
- 基本贝叶斯测试结果

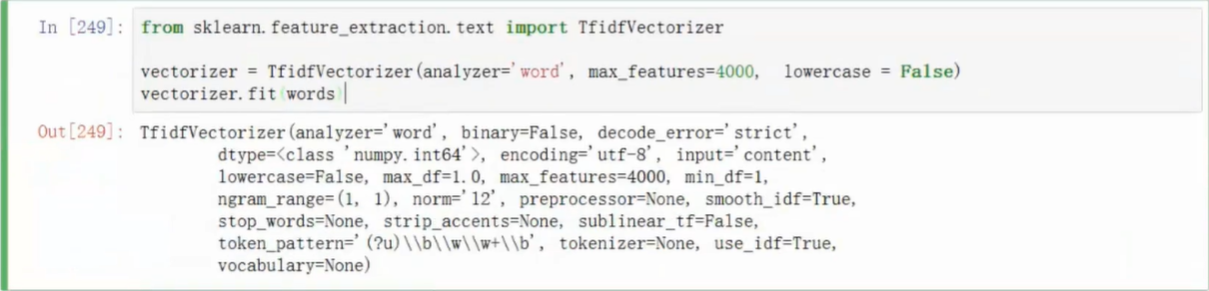
TF-IDF构造向量


若有收获,就点个赞吧
0 人点赞
