模型选择
- 想要确定对于一个数据集最合适的多项式次数
- 怎样选用正确的特征
- 正则化参数选择

- 对测试集的符合情况也不能证明模型对新样本的泛化能力有多强

- 会新增一个参数 d ,决定了采用的多项式的阶数
-
存在问题

会发生一个问题,通过测试集选择的一个确定的模型参数 d ,对新的数据集可能是不公平的
就会导致输出的预测函数,对数据集表现好过对于新的它没见过的样本
解决办法
重新分割数据集为三部分(训练集,交叉验证集,测试集)6:2:2
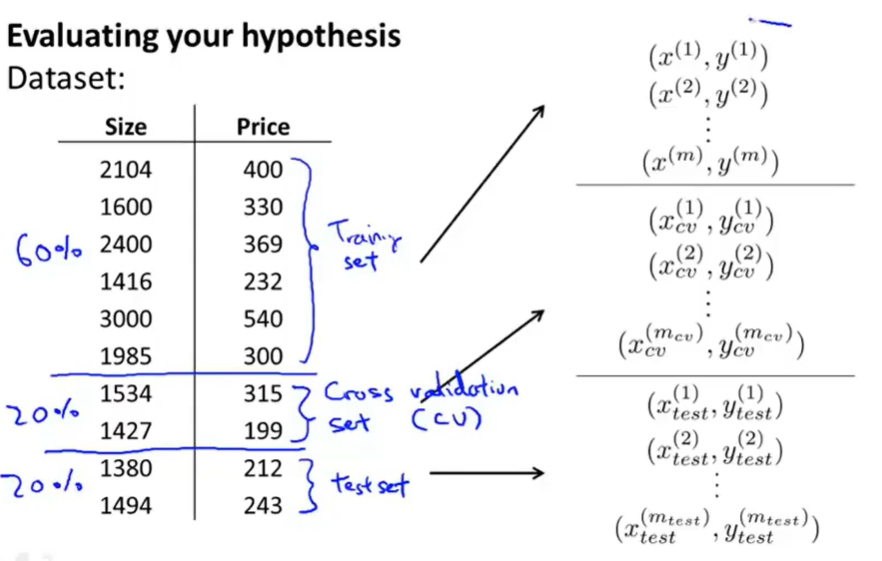

- 要通过验证集来选择模型,而不是原来的测试集

- 这样就省下了测试集,可以用来估计算法选出的模型的泛化误差

若有收获,就点个赞吧
0 人点赞
