- 原梯度下降算法在海量数据的情况下计算量会非常大
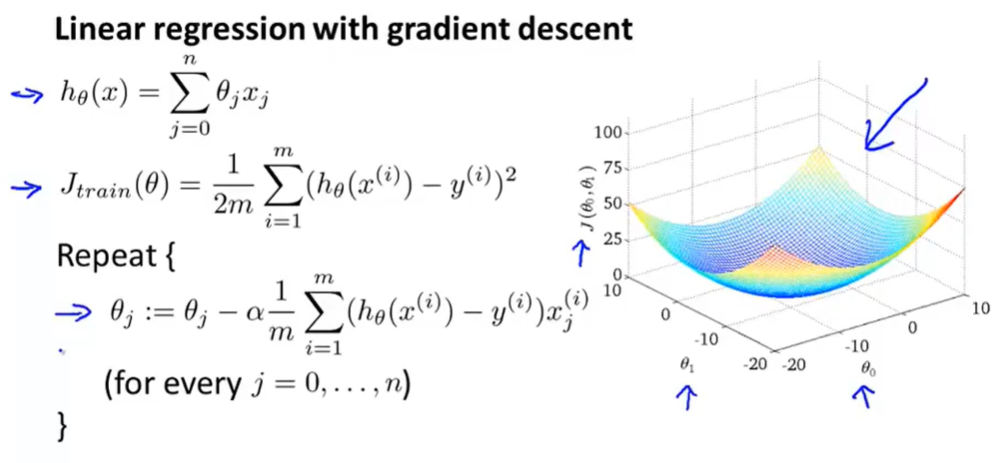
- 也被称为批量梯度下降
- Batch gradient desent
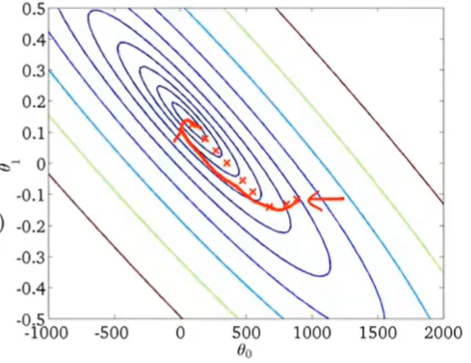
- 每次计算梯度下降都要考虑整个样本集(每一步都要计算所有的样本数)

- 不需要对每个样本计算导数项后求和,只需要对其中的单独向求导,然后迭代
- 即从第一个样本就已经开始在学习中了(依次拟合每一个样本点)
- 一开始的随机排布是为了算法更快收敛
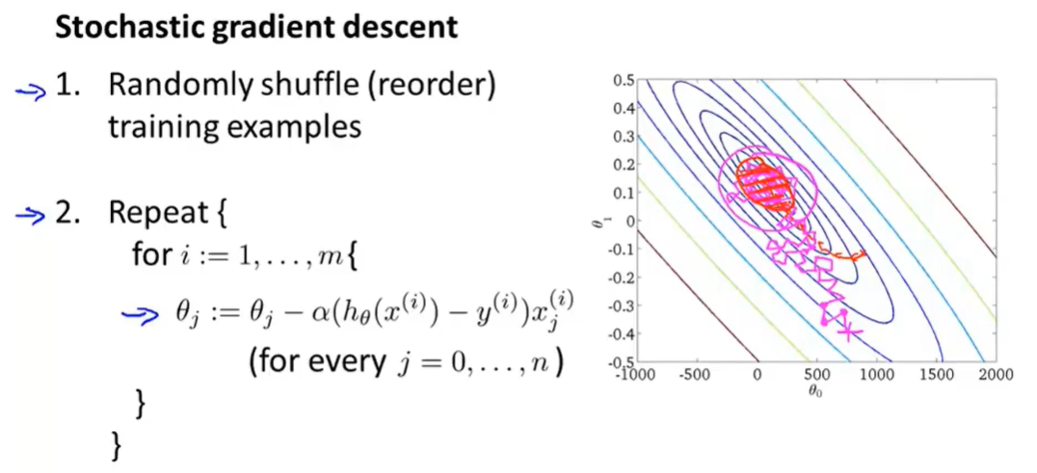
- 下降路线会更加曲折
- 最终会在最小值区域范围内徘徊
- 绝大多数时候,内层循环执行一次就可以得到很好的假设(仅执行了一次所有样本数的遍历)

若有收获,就点个赞吧
0 人点赞
