统计学基础
定义:通过对总体所抽样的样本数据(收集、整理、分析、展示),来分析总体的情况,切记不是为了分析样本,核心是推断总体的真实情况,然后用展示来将结论告知给被告知者。
样本
1. 样本 Sample
-
2. 代表性样本 Representative Sample
-
3. 随机样本 Random Sample
-
4. 好样本的特征
有清晰定义的总体
- 总体中没一个个体都有被抽选的机会
- 样本是总体的缩影,样本具有代表性
- 目标:样本是总体的缩影
抽样方法
- 简单随机抽样 Random Sampling
- 系统抽样 Systemic sampling
- 分层抽样 Stratified sampling
- 整群抽样 Cluster sampling
1. 简单随机抽样 Random Sampling
- 前提:总体数据分布具有较强均匀性
- 统计人口一个子集
- 总体钟每个个体都有被抽取相同的概率
- 一个简单随机抽样样本,是一个群体的【无偏】代表
- 优点:保证目标群体的代表性和抽样偏差消除
- 缺点:现实情况极难实现,都是成本和时间克服随机抽样缺点,还有其他抽样方法

2. 系统抽样 Systemic sampling
- 是简单随机抽样的简单变形

3. 分层抽样 Stratified sampling
- 根据总体之中每一个个体的特征分成几种类型,称为“层”,再从每一层,用随机抽样方式,抽取一个样本
- 分层抽样的原因:可得到各层信息。而且样本分配较均匀,提高估计准确度
- 分层随机抽样原则:同层内个体性质差异小,而不同层间个体差异越大越好

4. 整群抽样 Cluster sampling
- 先将总体区分位许多个不同的群体,然后随机抽取少数整体当成样本,从中选的整体全部调查
- 整群抽样假设每一个群体都是总体的缩影,因此不同群体间个体差异要小,而群体内个体差异要大
- 群大多是相似,如此导致采样误差增加,如果群都是一致,则进行一次以上观察,没有意义,因为观察结果都一样。精度损失与群的多样性有关,而多样性只有在采样之后才能知道

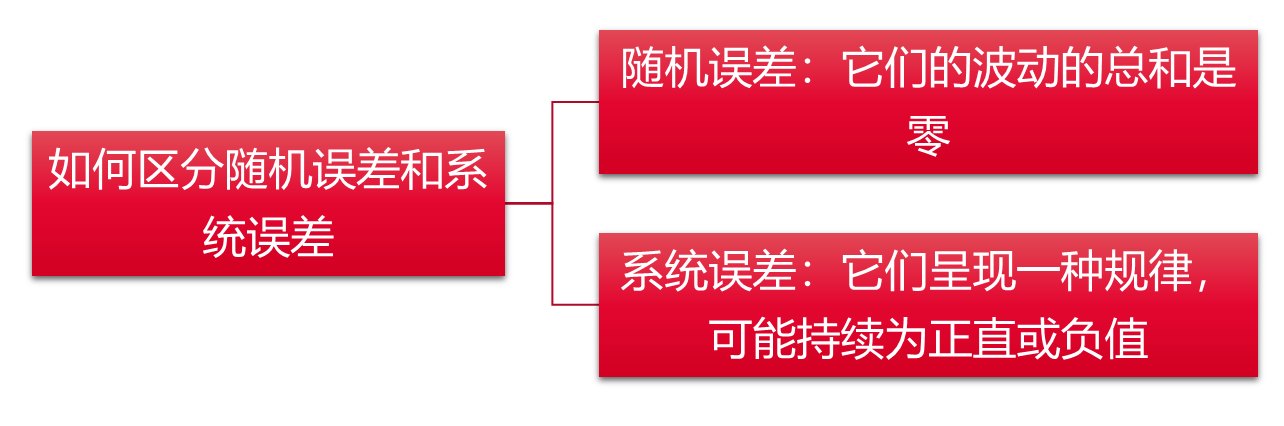
随机误差&系统误差
- 随机误差:测量物体观察值的误差,原因不明,偶然发生的误差。因为偶然,导致样本统计量和总体真值的差异。切记,随机误差永远不能被消除,但有办法降低
- 假如总体(真值)的平均值μ,样本(统计值)的平均值是M,那么随机误差:Δ=μ-M
- 系统误差:因系统问题,制度或流程问题造成的误差,可以通过改善消除。
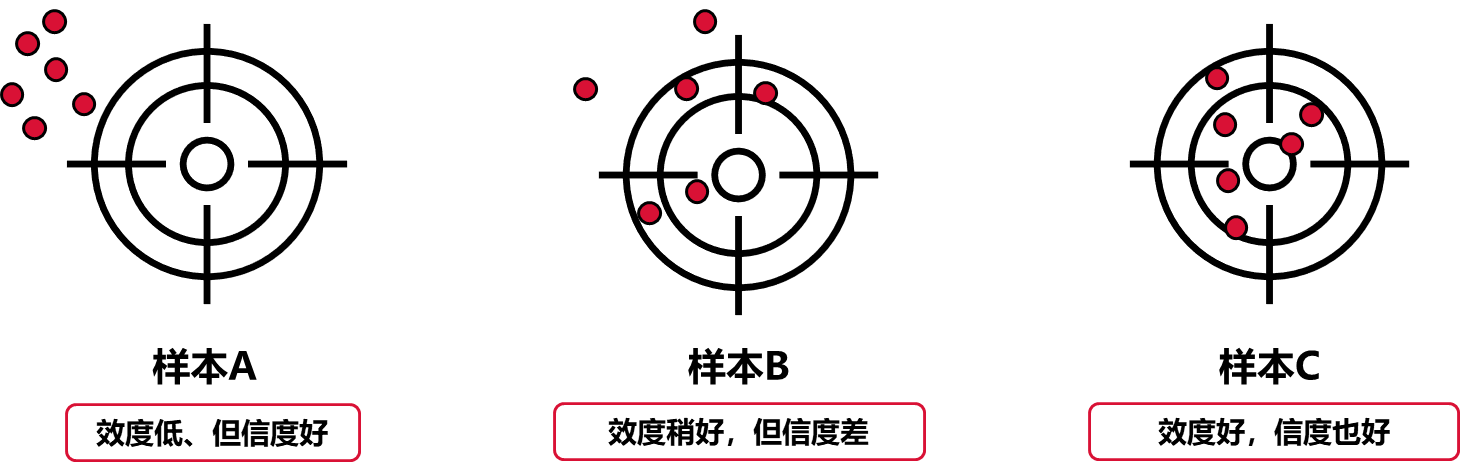
数据的衡量
1. 随机误差
4. 边际误差
- 边际误差(Margin of error)
- 符号:MOE
- 表达式:
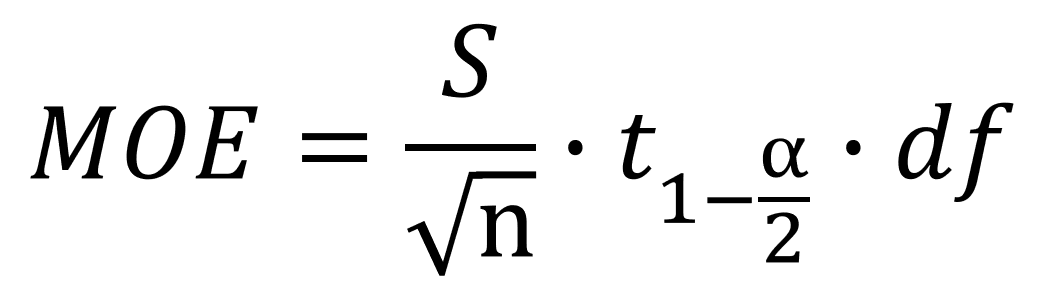
- 符号:S,是样本的标准差,n是总体样本数量,α是置信度,t是标准分布表
5. 置信区间(误差范围)[x ̅ - MOS,x ̅ + MOS]
- 接受计算结果误差范围多大?例如±5%
- 置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围;置信水平是指总体参数值落在样本统计值某一区内的概率;置信区间越大,置信水平越高。
- 符号: x ̅ ,是样本的平均值
- 置信区间: x ̅ ± MOS
-
6. 置信水平 1-α/2
对于真实结果落入置信区间内,信心有多大
-
7. 标准差σ
标准差:
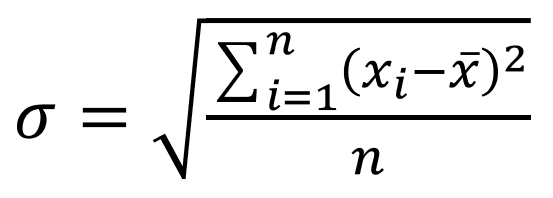
8. 方差σ²:衡量数据变异程度


若有收获,就点个赞吧
0 人点赞
