我们本节名称叫B树,但到了现在才开始提到它,似乎这主角出来的实在太晚了,可其实,我们前面一直都在讲B树。
B树(B-tree)是一种平衡的多路查找树,2-3树和2-3-4树都是B树的特例。结点最大的孩子数目称为B树的阶(order),因此,2-3树是3阶B树,2-3-4树是4阶B树。
一个m阶的B树具有如下属性:
- 如果根结点不是叶结点,则其至少有两棵子树。
- 每一个非根的分支结点都有k-1个元素和k个孩子,其中。每一个叶子结点n都有k-1个元素,其中。
- 所有叶子结点都位于同一层次。
- 所有分支结点包含下列信息数据 (n,A 0 ,K 1 ,A 1 ,K 2 ,A 2 ,…,K n ,A n ),其中:K i (i=1,2,…,n)为关键字,且K i <K i+1 (i=1,2,…,n-1);A i (i=0,2,…,n)为指向子树根结点的指针,且指针A i-1 所指子树中所有结点的关键字均小于K i (i=1,2,…,n),A n 所指子树中所有结点的关键字均大于K n ,n(≤n≤m-1)为关键字的个数(或n+1为子树的个数)。
例如,在讲2-3-4树时插入9个数后的图转成B树示意就如图8-8-17的右图所示。左侧灰色方块表示当前结点的元素个数。 
在B树上查找的过程是一个顺指针查找结点和在结点中查找关键字的交叉过程。
比方说,我们要查找数字7,首先从外存(比如硬盘中)读取得到根结点3、5、8三个元素,发现7不在当中,但在5和8之间,因此就通过A 2再读取外存的6、7结点,查找到所要的元素。
至于B树的插入和删除,方式是与2-3树和2-3-4树相类似的,只不过阶数可能会很大而已。
我们在本节的开头提到,如果内存与外存交换数据次数频繁,会造成了时间效率上的瓶颈,那么B树结构怎么就可以做到减少次数呢?
我们的外存,比如硬盘,是将所有的信息分割成相等大小的页面,每次硬盘读写的都是一个或多个完整的页面,对于一个硬盘来说,一页的长度可能是211到214个字节。
在一个典型的B树应用中,要处理的硬盘数据量很大,因此无法一次全部装入内存。因此我们会对B树进行调整,使得B树的阶数(或结点的元素)与硬盘存储的页面大小相匹配。比如说一棵B树的阶为1001(即1个结点包含1000个关键字),高度为2,它可以储存超过10亿个关键字,我们只要让根结点持久地保留在内存中,那么在这棵树上,寻找某一个关键字至多需要两次硬盘的读取即可。这就好比我们普通人数钱都是一张一张的数,而银行职员数钱则是五张、十张,甚至几十张一数,速度当然是比常人快了不少。
通过这种方式,在有限内存的情况下,每一次磁盘的访问我们都可以获得最大数量的数据。由于B树每结点可以具有比二叉树多得多的元素,所以与二叉树的操作不同,它们减少了必须访问结点和数据块的数量,从而提高了性能。可以说,B树的数据结构就是为内外存的数据交互准备的。
那么对于n个关键字的m阶B树,最坏情况是要查找几次呢?我们来作一分析。
第一层至少有1个结点,第二层至少有2个结点,由于除根结点外每个分支结点至少有|m/2|棵子树,则第三层至少有2×|m/2|个结点,……,这样第k+1层至少有2×(|m/2|) k-1 个结点,而实际上,k+1层的结点就是叶子结点。若m阶B树有n个关键字,那么当你找到了叶子结点,其实也就等于查找不成功的结点为n+1,因此n+1≥2×(|m/2|) k-1 ,即: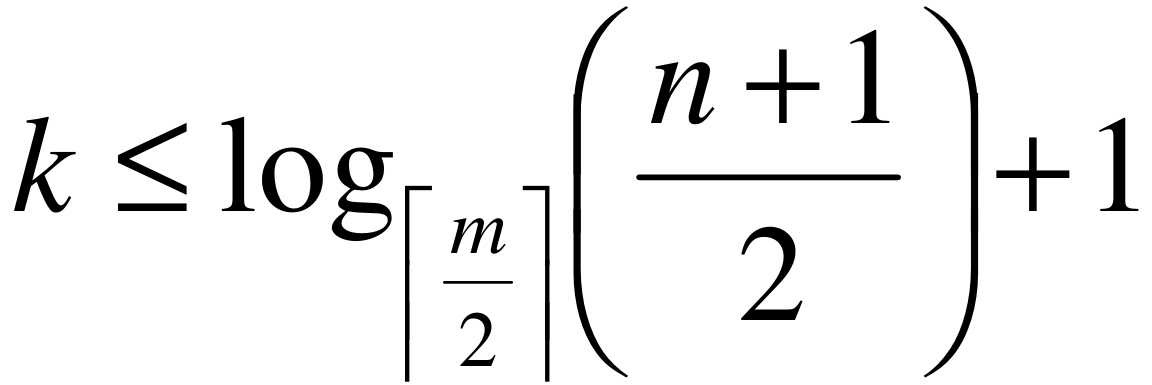
也就是说,在含有n个关键字的B树上查找时,从根结点到关键字结点的路径上涉及的结点数不超过log |m/2| ((n+1)/2)+1。

若有收获,就点个赞吧
0 人点赞
