回想一下图书馆是如何藏书的。显然它不会是顺序摆放后,给我们一个稠密索引表去查,然后再找到书给你。图书馆的图书分类摆放是一门非常完整的科学体系,而它最重要的一个特点就是分块。
稠密索引因为索引项与数据集的记录个数相同,所以空间代价很大。为了减少索引项的个数,我们可以对数据集进行分块,使其分块有序,然后再对每一块建立一个索引项,从而减少索引项的个数。
分块有序,是把数据集的记录分成了若干块,并且这些块需要满足两个条件:
- 块内无序,即每一块内的记录不要求有序。当然,你如果能够让块内有序对查找来说更理想,不过这就要付出大量时间和空间的代价,因此通常我们不要求块内有序。
- 块间有序,例如,要求第二块所有记录的关键字均要大于第一块中所有记录的关键字,第三块的所有记录的关键字均要大于第二块的所有记录关键字……因为只有块间有序,才有可能在查找时带来效率。
对于分块有序的数据集,将每块对应一个索引项,这种索引方法叫做分块索引。如图8-5-4所示,我们定义的分块索引的索引项结构分三个数据项:
- 最大关键码,它存储每一块中的最大关键字,这样的好处就是可以使得在它之后的下一块中的最小关键字也能比这一块最大的关键字要大;
- 存储了块中的记录个数,以便于循环时使用;
- 用于指向块首数据元素的指针,便于开始对这一块中记录进行遍历。

在分块索引表中查找,就是分两步进行:
- 在分块索引表中查找要查关键字所在的块。由于分块索引表是块间有序的,因此很容易利用折半、插值等算法得到结果。例如,在图8-5-4的数据集中查找62,我们可以很快可以从左上角的索引表中由57<62<96得到62在第三个块中。
- 根据块首指针找到相应的块,并在块中顺序查找关键码。因为块中可以是无序的,因此只能顺序查找。
应该说,分块索引的思想是很容易理解的,我们通常在整理书架时,都会考虑不同的层板放置不同类别的图书。例如,我家里就是最上层放不太常翻阅的小说书,中间层放经常用到的如菜谱、字典等生活和工具用书,最下层放大开本比较重的计算机书。这就是分块的概念,并且让它们块间有序了。至于上层中《红楼梦》是应该放在《三国演义》的左边还是右边,并不是很重要。毕竟要找小说《三国演义》,只需要对这一层的图书用眼睛扫过一遍就能很容易查找到。
我们再来分析一下分块索引的平均查找长度。设n个记录的数据集被平均分成m块,每个块中有t条记录,显然n=m×t,或者说m=n/t。再假设Lb 为查找索引表的平均查找长度,因最好与最差的等概率原则,所以L b的平均长度为(m+1)/2。L w 为块中查找记录的平均查找长度,同理可知它的平均查找长度为(t+1)/2。
这样分块索引查找的平均查找长度为: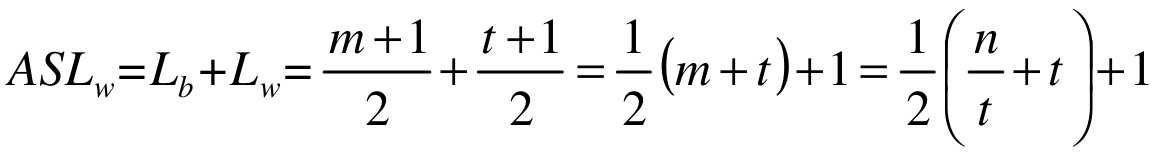
注意上面这个式子的推导是为了让整个分块索引查找长度依赖n和t两个变量。从这里了我们也就得到,平均长度不仅仅取决于数据集的总记录数n,还和每一个块的记录个数t相关。最佳的情况就是分的块数m与块中的记录数t相同,此时意味着n=m×t=t 2 ,即ASL w=1/2·(n/t+t)+1=t+1=sqrt(n)+1。
可见,分块索引的效率比之顺序查找的O(n)是高了不少,不过显然它与折半查找的O(logn)相比还有不小的差距。因此在确定所在块的过程中,由于块间有序,所以可以应用折半、插值等手段来提高效率。
总的来说,分块索引在兼顾了对细分块不需要有序的情况下,大大增加了整体查找的速度,所以普遍被用于数据库表查找等技术的应用当中。

若有收获,就点个赞吧
0 人点赞
