为了能讲清楚KMP算法,我们不直接讲代码,那样很容易造成理解困难,还是从这个算法的研究角度来理解为什么它比朴素算法要好。
如果主串S=”abcdefgab”,其实还可以更长一些,我们就省略掉只保留前9位,我们要匹配的T=”abcdex”,那么如果用前面的朴素算法的话,前5个字母,两个串完全相等,直到第6个字母,“f”与“x”不等,如图5-7-1的①所示。
接下来,按照朴素模式匹配算法,应该是如图5-7-1的流程②③④⑤⑥。即主串S中当i=2、3、4、5、6时,首字符与子串T的首字符均不等。
似乎这也是理所当然,原来的算法就是这样设计的。可仔细观察发现。对于要匹配的子串T来说,“abcdex”首字母“a”与后面的串“bcdex”中任意一个字符都不相等。也就是说,既然“a”不与自己后面的子串中任何一字符相等,那么对于图5-7-1的①来说,前五位字符分别相等,意味着子串T的首字符“a”不可能与S串的第2位到第5位的字符相等。在图5-7-1中,②③④⑤的判断都是多余。
注意这里是理解KMP算法的关键。如果我们知道T串中首字符“a”与T中后面的字符均不相等(注意这是前提,如何判断后面再讲)。而T串的第二位的“b”与S串中第二位的“b”在图5-7-1的①中已经判断是相等的,那么也就意味着,T串中首字符“a”与S串中的第二位“b”是不需要判断也知道它们是不可能相等了,这样图5-7-1的②这一步判断是可以省略的,如图5-7-2所示。
同样道理,在我们知道T串中首字符“a”与T中后面的字符均不相等的前提下,T串的“a”与S串后面的“c”、“d”、“e”也都可以在①之后就可以确定是不相等的,所以这个算法当中②③④⑤没有必要,只保留①⑥即可,如图5-7-3所示。
之所以保留⑥中的判断是因为在①中T[6]≠S[6],尽管我们已经知道T[1]≠T[6],但也不能断定T[1]一定不等于S[6],因此需要保留⑥这一步。
有人就会问,如果T串后面也含有首字符“a”的字符怎么办呢?
我们来看下面一个例子,假设S=”abcababca”,T=”abcabx”。对于开始的判断,前5个字符完全相等,第6个字符不等,如图5-7-4的①。此时,根据刚才的经验,T的首字符“a”与T的第二位字符“b”、第三位字符“c”均不等,所以不需要做判断,图5-7-4的朴素算法步骤②③都是多余。
因为T的首位“a”与T第四位的“a”相等,第二位的“b”与第五位的“b”相等。而在①时,第四位的“a”与第五位的“b”已经与主串S中的相应位置比较过了,是相等的,因此可以断定,T的首字符“a”、第二位的字符“b”与S的第四位字符和第五位字符也不需要比较了,肯定也是相等的——之前比较过了,还判断什么,所以④⑤这两个比较得出字符相等的步骤也可以省略。
也就是说,对于在子串中有与首字符相等的字符,也是可以省略一部分不必要的判断步骤。如图5-7-5所示,省略掉右图的T串前两位“a”与“b”同S串中的4、5位置字符匹配操作。 
对比这两个例子,我们会发现在①时,我们的i值,也就是主串当前位置的下标是6,②③④⑤,i值是2、3、4、5,到了⑥,i值才又回到了6。即我们在朴素的模式匹配算法中,主串的i值是不断地回溯来完成的。而我们的分析发现,这种回溯其实是可以不需要的——正所谓好马不吃回头草,我们的KMP模式匹配算法就是为了让这没必要的回溯不发生。
既然i值不回溯,也就是不可以变小,那么要考虑的变化就是j值了。通过观察也可发现,我们屡屡提到了T串的首字符与自身后面字符的比较,发现如果有相等字符,j值的变化就会不相同。也就是说,这个j值的变化与主串其实没什么关系,关键就取决于T串的结构中是否有重复的问题。
比如图5-7-3中,由于T=”abcdex”,当中没有任何重复的字符,所以j就由6变成了1。而图5-7-5中,由于T=”abcabx”,前缀的“ab”与最后“x”之前串的后缀“ab”是相等的。因此j就由6变成了3。因此,我们可以得出规律,j值的多少取决于当前字符之前的串的前后缀的相似度。
我们把T串各个位置的j值的变化定义为一个数组next,那么next的长度就是T串的长度。于是我们可以得到下面的函数定义: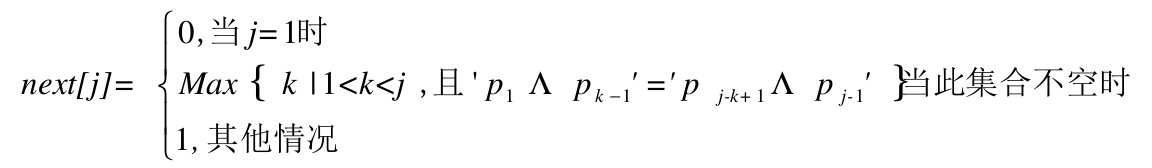

若有收获,就点个赞吧
0 人点赞
