现在我们的新问题是,为什么一定要折半,而不是折四分之一或者折更多呢?
打个比方,在英文词典里查“apple”,你下意识里翻开词典是翻前面的书页还是后面的书页呢?如果再让你查“zoo”,你又怎么查?很显然,这里你绝对不会是从中间开始查起,而是有一定目的的往前或往后翻。
同样的,比如要在取值范围0~10000之间100个元素从小到大均匀分布的数组中查找5,我们自然会考虑从数组下标较小的开始查找。
看来,我们的折半查找,还是有改进空间的。
折半查找代码的第8句,我们略微等式变换后得到: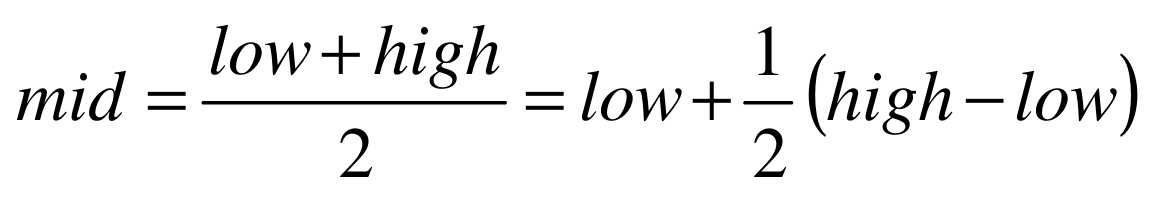
也就是mid等于最低下标low加上最高下标high与low的差的一半。算法科学家们考虑的就是将这个1/2进行改进,改进为下面的计算方案: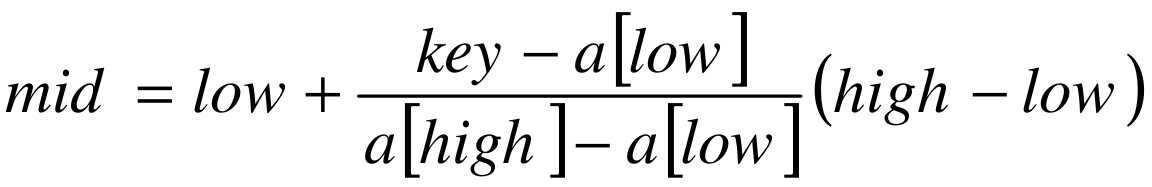
将1/2改成了(key-a[low])/(a[high]-a[low])有什么道理呢?假设a[11]= {0,1,16,24,35,47,59,62,73,88,99},low=1,high=10,则a[low]=1,a[high]=99,如果我们要找的是key=16时,按原来折半的做法,我们需要四次(如图8-4-6)才可以得到结果,但如果用新办法,(key-a[low])/(a[high]-a[low])=(16-1)/(99-1)≈0.153,即mid≈1+0.153×(10-1)=2.377取整得到mid=2,我们只需要二次就查找到结果了,显然大大提高了查找的效率。
换句话说,我们只需要在折半查找算法的代码中更改一下第8行代码如下:
mid=low+ (high-low)*(key-a[low])/(a[high]-a[low]); /* 插值 */
就得到了另一种有序表查找算法,插值查找法。插值查找(Interpolation Search)是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值的计算公式(key-a[low])/(a[high]-a[low])。应该说,从时间复杂度来看,它也是O(logn),但对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好得多。反之,数组中如果分布类似{0,1,2,2000,2001,……,999998,999999}这种极端不均匀的数据,用插值查找未必是很合适的选择。

若有收获,就点个赞吧
0 人点赞
