这篇文章旨在介绍我们使用MLflow的初步经验。
我们将通过记录所有探索性迭代,开始使用自己的跟踪服务器发现MLflow 。然后,我们将展示使用UDF将Spark与MLflow相关联的经验。
上下文
我们利用机器学习和人工智能的力量,使人们能够控制自己的健康和福祉。机器学习模型因此是我们正在开发的数据产品的核心,这就是为什么MLFLow,一个涵盖ML生命周期所有方面的开源平台引起了我们的注意。
MLflow
MLflow的主要目标是在ML之上提供额外的层,允许数据科学家与几乎任何机器学习库(h2o,keras,mleap,pytorch,sklearn和tensorflow)一起工作,同时,它将他们的工作带到另一个层次。
MLflow提供三个组件:
MLflow(目前处于alpha版本)是一个管理ML生命周期的开源平台,包括实验,可重复性和部署。
设置MLflow
为了使用MLflow,我们首先需要设置所有Python环境以使用MLflow,我们将使用PyEnv (在Mac中设置 → Python)。这将提供一个虚拟环境,我们可以在其中安装运行它所需的所有库。
pyenv install 3.7.0pyenv global 3.7.0 # Use Python 3.7mkvirtualenv mlflow # Create a Virtual Env with Python 3.7workon mlflow
安装所需的库
pip install mlflow==0.7.0 \Cython==0.29 \numpy==1.14.5 \pandas==0.23.4 \pyarrow==0.11.0
注意:我们使用PyArrow将模型作为UDF启动。PyArrow和Numpy版本需要修复,因为最新的版本之间存在一些冲突。
启动跟踪UI
MLflow Tracking允许我们使用Python和REST API 记录和查询实验。此外,还可以定义我们将存储模型工件的位置(Localhost,Amazon S3,Azure Blob存储,Google云存储或SFTP服务器)。由于我们使用AWS ,因此我们将尝试将S3作为工件存储。
# Running a Tracking Servermlflow server \--file-store /tmp/mlflow/fileStore \--default-artifact-root s3://<bucket>/mlflow/artifacts/ \--host localhost--port 5000
MLflow建议使用持久性文件存储。这file-store是服务器存储运行和实验元数据的位置。因此,在运行服务器时,请确保这指向持久文件系统位置。在这里,我们只是/tmp用于实验。
请记住,如果我们想使用mlflow服务器运行旧实验,它们必须存在于文件存储中。但是,如果没有它们,我们仍然可以在UDF中使用它们,因为只需要模型路径。
注意:请记住跟踪UI,模型客户端必须能够访问工件位置。这意味着,无论跟踪UI是否在EC2实例上,如果我们在本地运行MLflow,我们的机器应该可以直接访问S3来编写工件模型。
运行模型
跟踪服务器运行后,我们可以开始训练我们的模型。
作为一个例子,我们将使用MLflow Sklearn示例中提供的wine示例的修改。
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \--alpha 0.9--l1_ration 0.5--wine_file ./data/winequality-red.csv
如前所述,MLflow允许记录模型的参数,度量和工件,因此我们可以跟踪这些在不同迭代中如何演变。此功能非常有用,因为我们可以通过检查Tracking Server来重现我们的最佳模型,或者验证哪些代码正在执行所需的迭代,因为它记录(免费)git哈希提交。
with mlflow.start_run():... model ...mlflow.log_param("source", wine_path)mlflow.log_param("alpha", alpha)mlflow.log_param("l1_ratio", l1_ratio)mlflow.log_metric("rmse", rmse)mlflow.log_metric("r2", r2)mlflow.log_metric("mae", mae)mlflow.set_tag('domain', 'wine')mlflow.set_tag('predict', 'quality')mlflow.sklearn.log_model(lr, "model")

服务模型
使用“ > mlflow服务器> ”启动的> MLflow跟踪服务器还托管REST API,用于跟踪运行并将数据写入本地文件系统。您可以使用“ > MLFLOW_TRACKING_URI> ”环境变量指定跟踪服务器URI,MLflow跟踪API会自动与该URI处的跟踪服务器通信,以创建/获取运行信息,记录指标等。
参考:文档//运行跟踪服务器
为了提供模型,我们只需要运行一个跟踪服务器(参见启动UI)和一个模型运行ID。

# Serve a sklearn model through 127.0.0.0:5005MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \--port 5005 \--run_id 0f8691808e914d1087cf097a08730f17 \--model-path model
要使用MLflow服务功能为模型提供服务,我们需要访问跟踪UI,因此只需指定即可检索模型信息--run_id 。
一旦跟踪服务器为模型提供服务,我们就可以查询新的模型端点。
# Query Tracking Server Endpointcurl -X POST \http://127.0.0.1:5005/invocations \-H 'Content-Type: application/json' \-d '[{"fixed acidity": 3.42,"volatile acidity": 1.66,"citric acid": 0.48,"residual sugar": 4.2,"chloridessssss": 0.229,"free sulfur dsioxide": 19,"total sulfur dioxide": 25,"density": 1.98,"pH": 5.33,"sulphates": 4.39,"alcohol": 10.8}]'> {"predictions": [5.825055635303461]}
从Spark运行模型
虽然通过训练模型和使用服务功能(ref:mlflow // docs // models #local)实时为模型提供服务非常强大,但使用Spark(批量或流式传输)应用模型更是如此强大,因为它加入了分配力量。
想象一下,进行离线训练,然后以更简单的方式将输出模型应用于所有数据。这就是Spark和MLflow共同完美的地方。
安装PySpark + Jupyter + Spark
参考:PySpark开始 - Jupyter
展示我们如何将MLflow模型应用于Spark数据帧。我们需要使用PySpark设置Jupyter笔记本。
首先下载最新的稳定Apache Spark(当前版本2.3.2)。cd ~/Downloads/tar -xzf spark-2.3.2-bin-hadoop2.7.tgzmv ~/Downloads/spark-2.3.2-bin-hadoop2.7 ~/ln -s ~/spark-2.3.2-bin-hadoop2.7 ~/spark̀
在我们的virtualEnv中安装PySpark和Jupyterpip install pyspark jupyter
设置Environmnet变量export SPARK_HOME=~/sparkexport PATH=$SPARK_HOME/bin:$PATHexport PYSPARK_DRIVER_PYTHON=jupyterexport PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"通过定义notebook-dir,我们将能够将我们的笔记本存储和保存在所需的文件夹中。
从PySpark启动Jupyter
由于我们将Jupyter配置为PySpark驱动程序,现在我们可以使用附加到我们笔记本的PySpark上下文启动Jupyter。
(mlflow) afranzi:~$ pyspark[I 19:05:01.572 NotebookApp] sparkmagic extension enabled![I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).[C 19:05:01.574 NotebookApp]Copy/paste this URL into your browser when you connect for the first time,to login with a token:http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
如上所示,MLflow提供了将模型工件记录到S3的功能。因此,一旦我们选择了一个模型,我们就可以使用该mlflow.pyfunc模块将其作为UDF导入。
import mlflow.pyfuncmodel_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)columns = [ "fixed acidity", "volatile acidity", "citric acid","residual sugar", "chlorides", "free sulfur dioxide","total sulfur dioxide", "density", "pH","sulphates", "alcohol"]df.withColumn('prediction', wine_udf(*columns)).show(100, False)
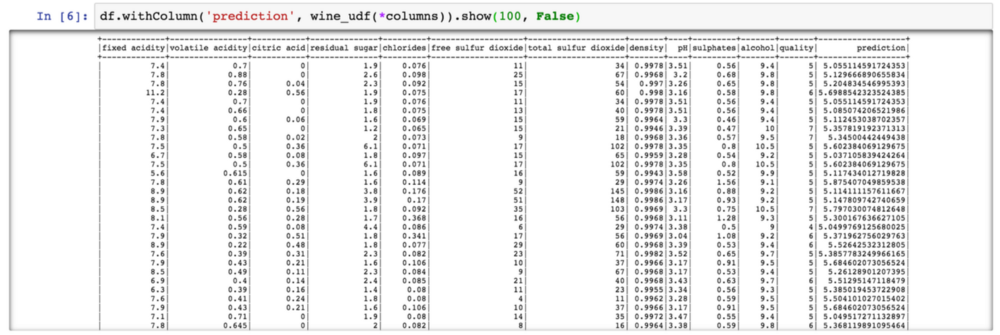
到目前为止,我们已经展示了如何通过在我们所有的葡萄酒数据集中运行葡萄酒质量预测来将PySpark与MLflow结合使用。但是当您需要使用Scala Spark的Python MLflow模块时会发生什么?
我们还设法通过在Scala和Python之间共享Spark Context来测试它。这意味着我们注册的MLflow UDF在Python,然后从斯卡拉用它(叶氏,不是一个很好的解决方案,但至少它的东西🍭)。
Scala Spark + MLflow
对于此示例,我们将Toree 内核添加到现有的Jupyter中。
安装Spark + Toree + Jupyter
pip install toreejupyter toree install --spark_home=/Users/afranzi/spark --sys-prefixjupyter kernelspec list
Available kernels:apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scalapython3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
正如您在附带的笔记本中看到的,UDF在Spark和PySpark之间共享。我们希望这最后一部分对那些喜欢Scala并且必须将ML模型投入生产的团队有所帮助。
In [1]:import org.apache.spark.sql.functions.colimport org.apache.spark.sql.types.StructTypeimport org.apache.spark.sql.{Column, DataFrame}import scala.util.matching.Regexval FirstAtRe: Regex = "^_".rval AliasRe: Regex = "[\\s_.:@]+".rdef getFieldAlias(field_name: String): String = {FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")}def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {val fieldsToSelect: List[Column] = columns.map(field =>col(field).as(getFieldAlias(field)))df.select(fieldsToSelect: _*)}def normalizeSchema(df: DataFrame): DataFrame = {val schema = df.columns.toListdf.transform(selectFieldsNormalized(schema))}FirstAtRe = ^_AliasRe = [\s_.:@]+getFieldAlias: (field_name: String)StringselectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFramenormalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrameOut[1]:[\s_.:@]+In [2]:val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csvmodelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/modelOut[2]:/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/modelIn [3]:val df = spark.read.format("csv").option("header", "true").option("delimiter", ";").load(winePath).transform(normalizeSchema)df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]Out[3]:[fixed_acidity: string, volatile_acidity: string ... 10 more fields]In [4]:%%PySparkimport mlflowfrom mlflow import pyfuncmodel_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)spark.udf.register("wineQuality", wine_quality_udf)Out[4]:<function spark_udf.<locals>.predict at 0x1116a98c8>In [6]:df.createOrReplaceTempView("wines")In [10]:%%SQLSELECTquality,wineQuality(fixed_acidity,volatile_acidity,citric_acid,residual_sugar,chlorides,free_sulfur_dioxide,total_sulfur_dioxide,density,pH,sulphates,alcohol) AS predictionFROM winesLIMIT 10Out[10]:+-------+------------------+|quality| prediction|+-------+------------------+| 5| 5.576883967129615|| 5| 5.50664776916154|| 5| 5.525504822954496|| 6| 5.504311247097457|| 5| 5.576883967129615|| 5|5.5556903912725755|| 5| 5.467882654744997|| 7| 5.710602976324739|| 7| 5.657319539336507|| 5| 5.345098606538708|+-------+------------------+In [17]:spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)+-----------+--------+-----------+---------+-----------+|name |database|description|className|isTemporary|+-----------+--------+-----------+---------+-----------+|wineQuality|null |null |null |true |+-----------+--------+-----------+---------+-----------+
下一步
尽管MLflow目前处于Alpha(🥁),但它看起来很有希望。只需能够运行多个机器学习框架并从同一端点使用它们,它就能将所有推荐系统提升到新的水平。
此外,MLflow 通过在它们之间建立公共层,使> 数据工程师和数据科学家> 更加接近 。>
在对MLflow进行这项研究之后,我们确信我们将进一步研究它并开始在Spark管道和我们的推荐系统中使用它。
让文件存储与数据库同步而不是使用FS会很好。这应该允许多个端点使用相同的文件存储。就像使用相同的Glue Metastore有多个Presto和Athena实例一样。
最后,感谢MLflow背后的所有社区,使其成为可能,让我们的数据更有趣。
如果您正在玩MLflow,请随时联系我们并提供有关您如何使用它的一些反馈!更重要的是,如果您在生产中使用MLflow。

若有收获,就点个赞吧
0 人点赞
