Computer vision object detection models: R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN, YOLO
这篇是简介一些用来辨识影像中物体的AI 模型。
在前面有提到,透过CNN模型,你可以输入一张图片,得到该图片属于哪种类别的结果,这过程我们把他称作分类(Classification)。
但在真实世界的应用情境通常要从一张图片中辨识所有出现的物体, 并且标示出位置来(标出位置称之为Object Localization)。你一定在网路上看过类似底下的影片,这段影片可以看出中国闭路摄影机(CCTV)发展的概况,不只是可以框出影像中每个物件,辨别物件种类,侦测出移动物体的动量,甚至是人脸辨识,实现楚门世界的恶梦。要做到这就需要靠深度学习中的Object Detection 演算法,这也是最近几年来深度学习最蓬勃发展的一块领域。
https://youtu.be/aE1kA0Jy0Xg
基本的想法是,既然CNN 对于物体的分类又快又好,那我们可不可以拿CNN 来扫描并辨识图片中的任何物体?答案当然是 — 可以。
最简单的作法就是用Sliding Windows 的概念,也就是用一个固定大小的框框,逐一的扫过整张图片,每次框出来的图像丢到CNN 中去判断类别。由于物体的大小是不可预知的,所以还要用不同大小的框框去侦测。但是Sliding Window 是非常暴力的作法,对单一影像我们需要扫描非常多次,每扫一次都需要算一次CNN,这将会耗费大量的运算资源,而且速度慢,根本无法拿来应用!
所以后来就有人提出了R-CNN (Regions with CNN)
R-CNN
与其用Sliding Window的方式扫过一轮,R-CNN的作法是预先筛选出约2000个可能的区域,再将这2000区域个别去作分类,所以他的演算法流程如下:
产生一群约2000 个可能的区域(Region Proposals)
经由一个预先训练好的CNN 模型如AlexNet 撷取特征,将结果储存起来。
然后再以SVM (Support Vector Machine) 分类器来区分是否为物体或者背景。
最后经由一个线性回归模型来校正bounding box 位置。

Selective Search
R-CNN用来筛选Region Proposals的方法称之为Selective Search,而Selective Search又是基于Felzenszwal于2004年发表的论文Graph Base Image Segmentation。
图像经由Graph Base Image Segmentation 可以切出数个Segment 来,如下图:
而Selective Search 的作法是将Segment 的结果先各自画出bounding box,然后以一个回圈,每次合并相似度最高的两个box,直到整张图合并成单一个box 为止,在这过程中的所有box 便是selective search 出来的region proposals。Selective Search 的演算法如下:
取自Selective Search 论文。先以Graph base image segmentation 取得一些区域,计算每个区域间的相似度,每次合并相似度最高的两个区域,直到整张图片成为单一区域为止。
但是R-CNN 存在一些问题,速度仍然不够快:
R-CNN 一开始必须先产生约2000 个区域,每个区域都要丢进CNN 中去撷取特征,所以需要跑过至少2000 次的CNN
R-CNN 的model 是分开成三部份,分别是用来取出特征的CNN,分类的SVM,以及优化bounding box 的线性回归。所以R-CNN 不容易作训练。
所以R-CNN的其中一个作者Ross Girshick (RBG大神)在2015年又提出了一个改良版本,并称之为Fast R-CNN。
Fast R-CNN
Fast R-CNN的想法很简单,在R-CNN中,2000多个区域都要个别去运算CNN,这些区域很多都是重叠的,也就是说这些重叠区域的CNN很多都是重复算的。所以Fast R-CNN的原则就是全部只算一次CNN就好,CNN撷取出来的特征可以让这2000多个区域共用!
Fast R-CNN 采用的作法就是RoIPooling (Region of Interest Pooling)。
Fast RCNN 一样要预选Region proposals,但是只做一次CNN。在跑完Convolution layers 的最后一层时,会得到一个HxW 的feature map,同时也要将region proposals 对应到HxW 上,然后在feature map 上取各自region 的MaxPooling,每个region 会得到一个相同大小的矩阵(例如2x2)。
from https://blog.deepsense.ai/region-of-interest-pooling-explained/
然后各自连接上FC 网路,以及softmax 去作分类。在分类的同时也作bounding box 的线性回归运算。
Fast RCNN 的优点是:
只需要作一次CNN,有效解省运算时间
使用单一网络,简化训练过程
Faster R-CNN
不管是R-CNN还是Fast R-CNN都还是要先透过selective search预选region proposals,这是一个缓慢的步骤。在2015年时,Microsoft的Shaoqing Ren , Kaiming He , Ross Girshick ,以及Jian Sun提出了Faster R-CNN,一个更快的R-CNN。
Faster R-CNN 的想法也很直觉,与其预先筛选region proposals,到不如从CNN 的feature map 上选出region proposals。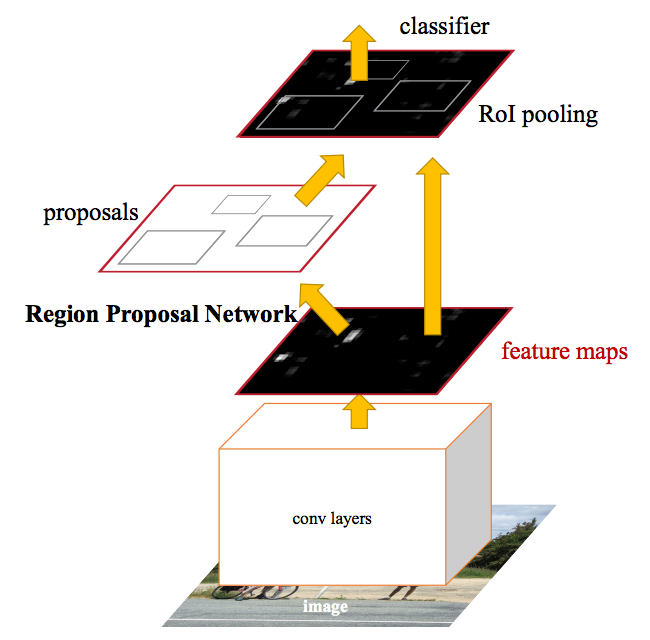
Region Proposal Network
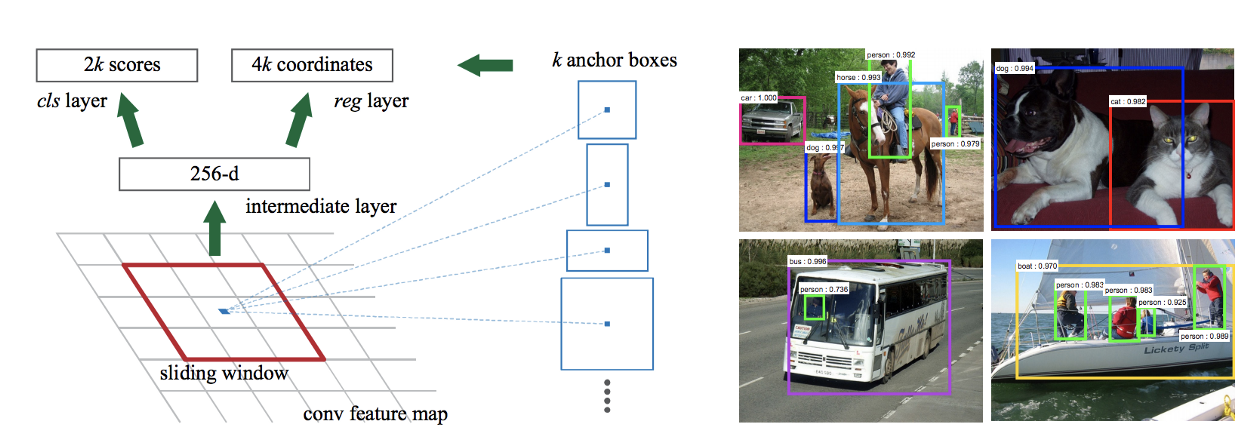
RPN (Region Proposal Network) 也是一个Convolution Network,Input 是之前CNN 输出的feature map,输出是一个bounding box 以及该bounding box 包含一个物体的机率。
RPN 在feature map 上取sliding window,每个sliding window 的中心点称之为anchor point,然后将事先准备好的k 个不同尺寸比例的box 以同一个anchor point 去计算可能包含物体的机率(score) ,取机率最高的box。这k 个box 称之为anchor box。所以每个anchor point 会得到2k 个score,以及4k 个座标位置(box 的左上座标,以及长宽,所以是4 个数值)。在Faster R-CNN 论文里,预设是取3 种不同大小搭配3 种不同长宽比的anchor box,所以k 为3x3 = 9 。
经由RPN 之后,我们便可以得到一些最有可能的bounding box,虽然这些bounding box 不见得精确,但是透过类似于Fast RCNN 的RoIPooling, 一样可以很快的对每个region 分类,并找到最精确的bounding box 座标。
Mask R-CNN
前述几个方法都是在找到物体外围的bounding box,bounding box基本上都是方形,另外一篇有趣的论文是Facebook AI researcher Kaiming He所提出的Mask R-CNN,透过Mask R-CNN不只是找到bounding box,可以做到接近pixel level的遮罩(图像分割Image segmentation)。
要了解Mask R-CNN 如何取遮罩,要先看一下FCN (Fully Convolutional Network)
FCN (Fully Convolutional Network) for Image Segmentation
有别于CNN 网络最后是连上一个全连接(Fully Connected)的网络,FCN (Fully Convolutional Network)最后接上的是一个卷积层。一般的CNN 只能接受固定大小的Input,但是FCN 则能接受任何大小的Input,例如W x H 。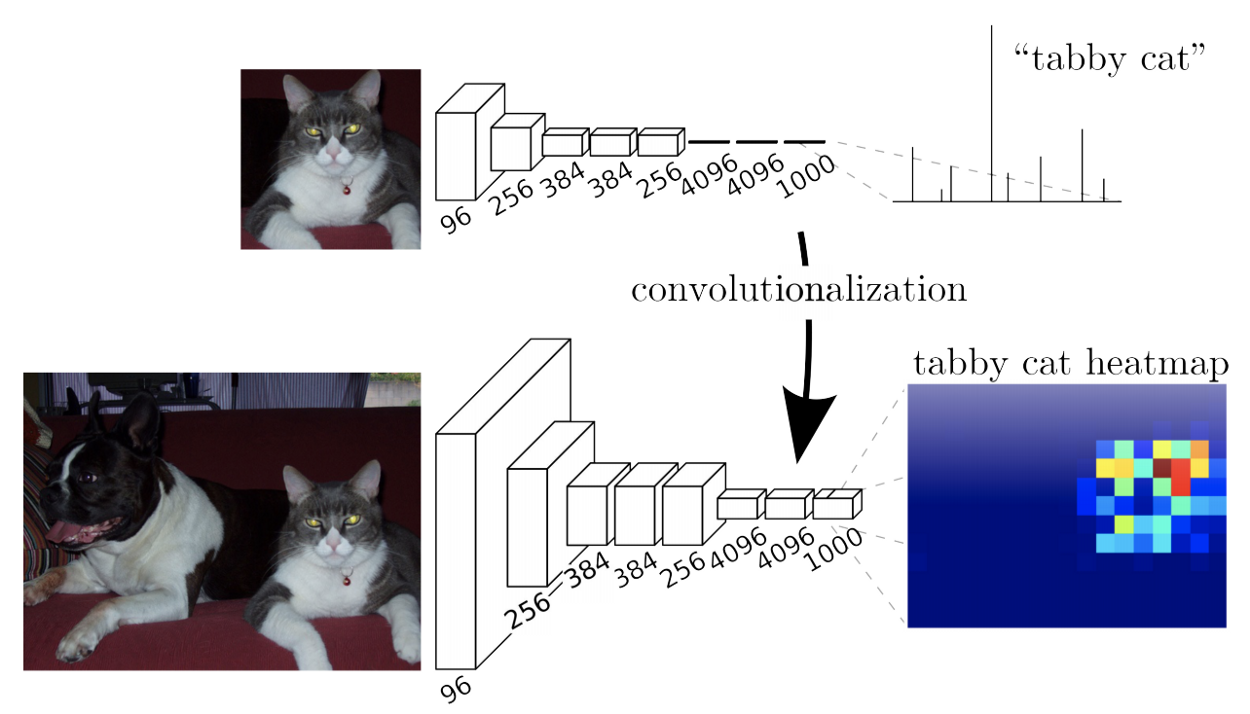
图上方一般的CNN 网络,只能接受大小固定的输入,得到单一维度的输出,分别代表每个类别的机率。图下则是FCN 网路,最后两层由卷积取代,输出为hxwx 1000,代表每个pixel 种类的机率,可以视为一个heapmap。
在CNN 的过程中会一直作downsampling,所以FCN 最后的输出可能为H/32 x W/32,实际上得到的会是一个像heapmap 的结果。但是由于这过程是downsampling,所以Segment 的结果是比较粗糙,为了让Segment 的效果更好,要再做upsampling,来补足像素。upsamping 的作法是取前面几层的结果来作差补运算。
FCN 的结果会跟前面几层的输出作差补运算
Mask R-CNN是建构于Faster R-CNN之上,如果是透过RoIPooling取得Region proposals之后,针对每个region会再跑FCN取得遮罩分割,但是由于RoIPooling在做Max pooling时,会使用最近插值法( Nearest Neighbor Interpolation )取得数值,所以出来的遮罩会有偏移现象,再加上pooling下来的结果,会让region的尺寸出现非整数的情况,然后取整数的结果就是没办法做到Pixel层级的遮罩。所以Mask R-CNN改采用双线性插值法( Bilinear Interpolation )来改善RoIPooling,称之为RoIAlign,RoIAlign会让遮罩位置更准确。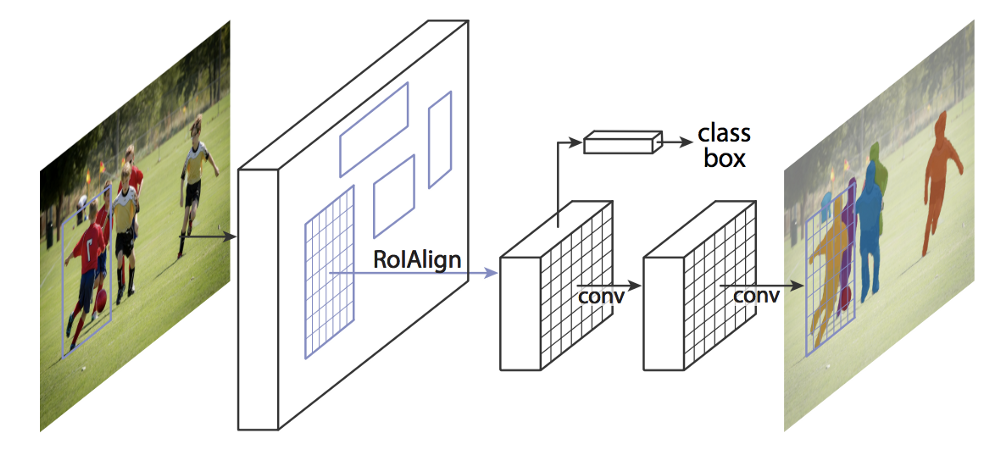
Mask RCNN 架构,将原有的RoIPooling 改成 RoIAlign。
Fast R-CNN 的RoIPool。将一个7x5 的Anchor box 取2x2 的MaxPool,由于使用最近插值法,会有偏差。
RoIAlign的作法是使用双线性插值法( Bilinear Interpolation ),减少mis-alignment的问题。
YOLO: You Only Look Once
YOLO有个很讨喜的名字,取自You Only Live Once,但用在Object detection上则为You only look once,意思是说YOLO模型的特性只需要对图片作一次CNN便能够判断里面的物体类别跟位置,大大提升辨识速度。
R-CNN 的概念是先提出几个可能包含物体的Region proposal,再针对每个region 使用CNN 作分类,最后再以regression 修正bounding box 位置,速度慢且不好训练。YOLO 的好处是单一网路设计,判断的结果会包含bounding box 位置,以及每个bounding box 所属类别及概率。整个网路设计是end-to-end 的,容易训练,而且速度快。
YOLO 速度快,在Titan X GPU 上可以达到每秒45 祯的速度,简化版的YOLO 甚至可以达到150 fps 的速度。这意味着YOLO 已经可以对影像作即时运算了。准确度(mAP) 也狠甩其他深度学习模型好几条街。看看底下YOLO2 的demo 视频,这侦测速度会吓到吃手手了https://youtu.be/VOC3huqHrss
有别于R-CNN 都是先提region 再做判断,看的范围比较小,容易将背景的background patch 看成物体。YOLO 在训练跟侦测时都是一次看整张图片,背景错误侦测率(background error, 抑或false positive) 都只有Fast R-CNN 的一半。
YOLO 的泛用性也比R-CNN 或者DPM 方式来得好很多,在新的domain 使用YOLO 依旧可以很稳定。
YOLO 的概念是将一张图片切割成S x S 个方格,每个方格以自己为中心点各自去判断B 个bounding boxes 中包含物体的confidence score 跟种类。
confidence score = Pr(Object) * IOU (ground truth)
如果该bounding box 不包含任何物体(Pr(Object) = 0),confidence score 便为零,而IOU 则为bounding box 与ground truth 的交集面积,交集面积越大,分数越高。
每个方格预测的结果包含5 个数值,x 、y 、w 、 h 跟confidence,x 与y 是bounding box 的中间点,w 与h 是bounding box 的宽跟高。

S = 7,B = 2,PASCAL VOC label 20 种种类,所以tensor 为S x S x (5 * B + C) = 7 x 7 x 30
YOLO 的网路设计包含了24 个卷积层,跟2 层的FC 网络。
另外一个版本的YOLO Fast 则只有9 个卷积层,不过最后的输出都是7x7x30 的tensor。
YOLO 的缺点
由于YOLO 对于每个方格提两个bounding box 去作侦测,所以不容易去区分两个相邻且中心点又非常接近的物体
只有两种bounding box,所以遇到长宽比不常见的物体的检测率较差
YOLO 与其他模型的比较


YOLO2
YOLO2建构于YOLO之上,但是有更好的准确度,更快速的判断速度,能够判断更多的物件种类(多达9000种),所以是更好(Better)、更快(Faster)、更强大(Stronger)!
YOLO2 在准确度上比YOLO 好,且追上什至超越其他模型像是Faster R-CNN 或者SSD 等,速度还是别人的2–10 倍以上。
YOLO2 采用了许多改善方式,例如batch normalization、anchor box 等,使用了这些改良方式让YOLO2 不管在辨识速度还是准确率上都有了提升,此外对于不同图档大小也有很好的相容性,提供了在速度与准确性上很好的平衡,所以也很适合运用在一些便宜的GPU 或者CPU 上,依旧提供水准以上的速度与准确率。
结语
物体辨识(Object detection)的进展飞快,为了整理这篇大概也看了七八篇论文,还有很多都还没涵盖到的,例如SSD ( Single Shot Mulitbox Detector )。如果想更了解AI在Computer Vision最近几年的发展,也可以参考这篇搜文 A Year in Computer vision,内容涵盖了Classification、Object detection、Object tracking、Segmentation、Style transfer、Action recognition、3D object、Human post recognition等等,看完会大致知道在Computer Vision中有哪些AI所做的努力,以及各自的进展。
Google的Tensorflow也有提供Object detection API,透过使用API ,不用理解这些模型的实作也能快速实作出速度不错涵盖率又广的object detection。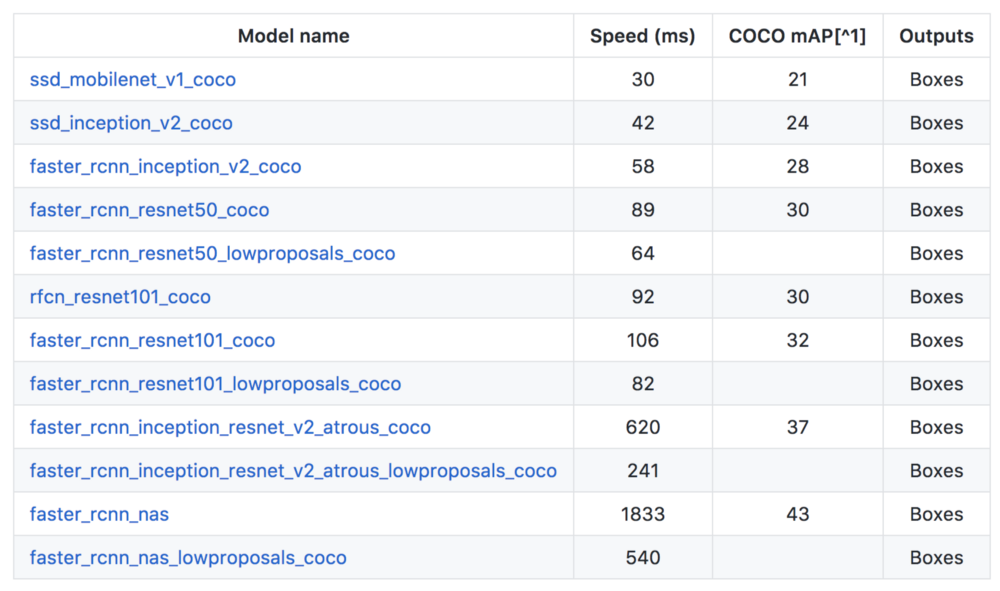

若有收获,就点个赞吧
0 人点赞
