 你有过或曾经参加过Kaggle比赛吗?大多数获奖者通过使用助推算法来做到这一点。为什么AdaBoost,GBM和XGBoost是冠军的首选算法?
你有过或曾经参加过Kaggle比赛吗?大多数获奖者通过使用助推算法来做到这一点。为什么AdaBoost,GBM和XGBoost是冠军的首选算法?
首先,如果您从未听说过Ensemble Learning或Boosting,请查看我的帖子“Ensemble Learning:当每个人都猜测……我猜!”这样您就可以更好地理解这些算法了。
更有见识?好,我们开始吧!
因此,提升任何其他整体算法的想法是将几个弱学习者组合成一个更强大的学习者。Boosting算法的一般思想是按顺序尝试预测器,其中每个后续模型都试图修复其前任的错误。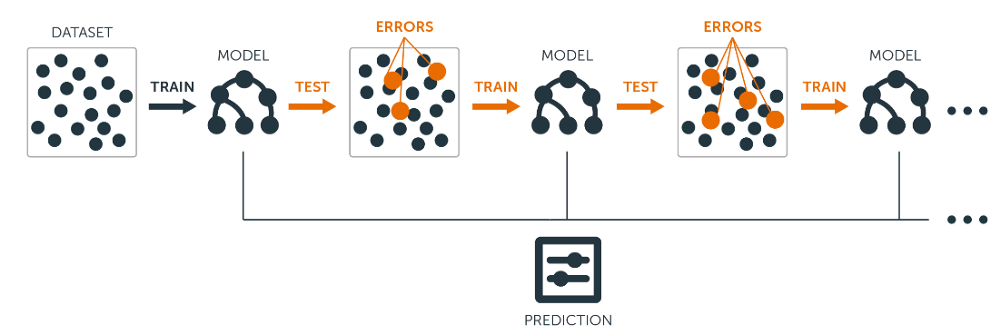
自适应提升
自适应Boosting或最常见的AdaBoost是Boosting算法。令人震惊!该算法用于纠正其前身的方法是通过以前的模型更多地关注配备不足的训练实例。因此,在每个新的预测器中,焦点将是每次都在更难的情况下。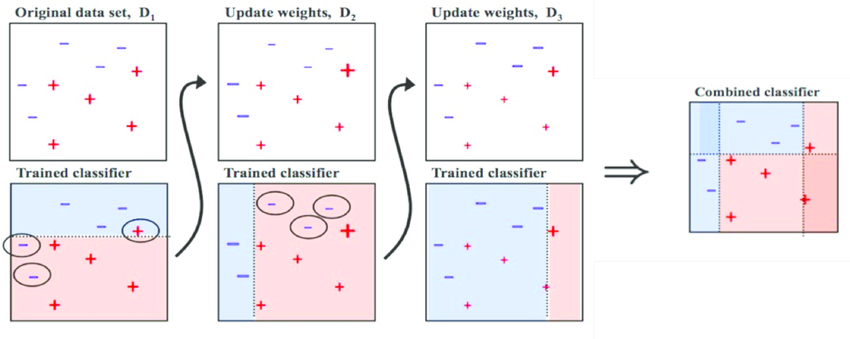
我们以图像为例。要构建AdaBoost分类器,假设我们作为第一个基本分类器训练决策树算法,以对我们的训练数据进行预测。现在,遵循AdaBoost的方法,增加了错误分类的训练实例的权重。第二个分类器经过训练并确认更新的权重,并且一遍又一遍地重复该过程。
在每个模型预测结束时,我们最终会提高错误分类实例的权重,以便下一个模型能够更好地完成它们,依此类推。
这种顺序学习技术听起来有点像Gradient Descent,除了不是调整单个预测器的参数以最小化成本函数,AdaBoost会向整体添加预测器,逐渐使其变得更好。该算法的最大缺点是模型不能并行化,因为每个预测器只能在前一个预测器经过训练和评估后才能进行训练。
以下是执行AdaBoost算法的步骤:
- 最初,所有观察都给予相同的权重。
- 模型建立在数据子集上。
- 使用此模型,可以对整个数据集进行预测。
- 通过比较预测值和实际值来计算误差。
- 在创建下一个模型时,会对未正确预测的数据点赋予更高的权重。
- 可以使用误差值确定权重。例如,误差越大,分配给观察的权重越大。
- 重复该过程,直到误差函数没有改变,或达到估计量的最大限制。
超参数**base_estimators**:指定基本类型估计器,即用作基础学习器的算法。**n_estimators**:它定义了基本估算器的数量,默认值为10,但您可以增加它以获得更好的性能。**learning_rate** :与梯度下降算法相同的影响**max_depth** :个体估算器的最大深度n_jobs :表示系统允许使用的处理器数量。值“-1”表示没有限制;random_state :使模型的输出可复制。当您给它一个固定值以及相同的参数和训练数据时,它将始终产生相同的结果。
渐变提升
这是另一种非常流行的Boosting算法,其工作基础与我们在AdaBoost中看到的一样。渐变增强通过将先前预测变量未完成的预测顺序添加到整体来工作,从而确保先前产生的错误得到纠正。
不同之处在于它对前任的不足之处的价值所起的作用。与在每次交互时调整实例权重的AdaBoost相反,此方法尝试将新预测器拟合到先前预测器所产生的残差。
因此,您可以了解Gradient Boosting,首先了解Gradient Descent非常重要。
以下是执行Gradien Boosting算法的步骤:
- 模型建立在数据子集上。
- 使用此模型,可以对整个数据集进行预测。
- 通过比较预测值和实际值来计算误差。
- 使用计算为目标变量的误差创建新模型。我们的目标是找到最佳分割以最小化错误。
- 这个新模型的预测与之前的预测结合起来。
- 使用此预测值和实际值计算新错误。
- 重复该过程,直到误差函数没有改变,或达到估计量的最大限制。
超参数
min_samples_split**:**在要考虑拆分的节点中所需的最小观察次数。它用于控制过度拟合。min_samples_leaf:终端或叶节点中所需的最小样本数。应该为不平衡的阶级问题选择较低的值,因为少数群体占大多数的地区将非常小。min_weight_fraction_leaf:类似于前一个但是定义了观察总数的一小部分而不是整数。max_depth:树的最大深度。用于控制过度拟合。max_lead_nodes:树中最大叶子数。如果定义了这个max_depth则被忽略。max_features:搜索最佳拆分时应考虑的功能数量。XGBoost
Extreme Gradient Boosting是Gradient Boosting的高级实现。该算法具有高预测能力,比任何其他梯度增强技术快十倍。此外,还包括各种正规化,可减少过度拟合并提高整体性能。
好处
- 实施正规化有助于减少过度拟合(GB没有);
- 实现并行处理比GB快得多;
- 允许用户定义自定义优化目标和评估标准,为模型添加全新维度;
- XGBoost有一个内置的例程来处理缺失值;
- XGBoost进行分割
max_depth,然后开始向后修剪树,并删除没有正增益的分裂; - XGBoost允许用户在增强过程的每次迭代中运行交叉验证,因此很容易在一次运行中获得精确的最佳增强迭代次数。
轻GB
对于非常大的数据集,Light Gradient Boosting是最好的,与其他所有相比,因为它需要更少的时间来运行。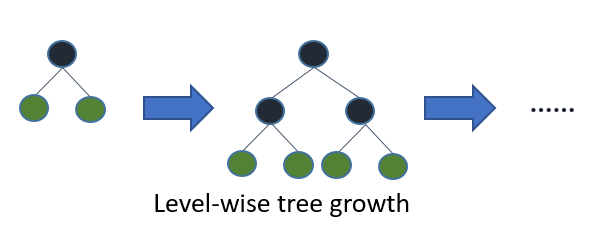
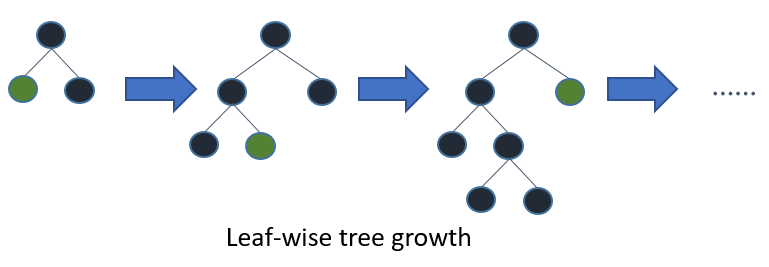
该算法基于叶子树生长,与其他工作在水平方式模式中相反。你可以在这里看到XGBoost和Light GB之间的比较。
如果您喜欢它,请关注我以获取更多出版物,请不要忘记,请给予掌声!
你是强大的读者鼓掌!
资源:
- 第7章,AurélienGéron 使用Scikit-Learn和TensorFlow进行实践机器学习
- Analytics Vidhya,集成学习综合指南(使用Python代码)

若有收获,就点个赞吧
0 人点赞
