而不是对缺失值进行估算并不总是正确的选择
现在很容易在数据科学任务中获得不错的结果:只需要对流程有一个大致的了解,Python的基本知识和10分钟的时间来实例化XGBoost并适应模型。好的,如果这是你的第一次,那么你可能会花几分钟通过pip收集所需的包,但就是这样。这种方法的唯一问题是它运作得很好🤷🏻♂️:几年前我在大学竞赛中排名前5位,只是通过一些基本的特征工程将数据集提供给XGBoost,表现优于团队非常复杂的架构和数据管道。 XGBoost最酷的特征之一就是它如何处理缺失值:决定每个样本,这是最好的方法来判断它们。对于我在过去几个月中遇到的许多项目和数据集,此功能非常有用;为了更加值得以我的名义撰写的数据科学家的头衔,我决定深入挖掘,花几个小时阅读原始论文,试图了解XGBoost究竟是什么以及它如何处理它以某种神奇的方式缺少价值。
从决策树到XGBoost
决策树可能是机器学习中最简单的算法:树的每个节点都是对特征的测试,每个分支代表测试的结果; leaves包含模型的输出,无论是离散标签还是实数。 决策树可能被描述为一个功能: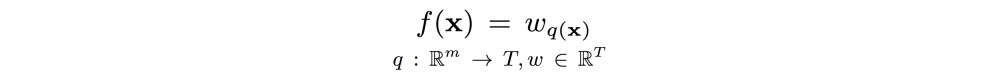
函数f根据从根到叶子的路径,根据树结构T分配m大小的样本x所遵循的权重w。
现在想象一下,不只有一棵决策树而且还有K; 最终产生的输出不再是与叶子相关的权重,而是与每棵树产生的叶子相关的权重之和。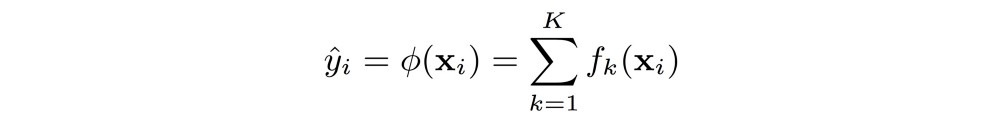
这些结构不是固定的,并且与网络结构不变的经典梯度下降框架中发生的不同,并且在每个步骤更新权重时,在每次迭代时添加新函数(树)以改善模型的性能。 为了避免过度拟合和/或非常复杂的结构,误差由两部分组成:第一部分对在第k次迭代中获得的模型的优度进行评分,第二部分在相关权重的大小中惩罚复杂性。 叶子和发达的树木的深度和结构。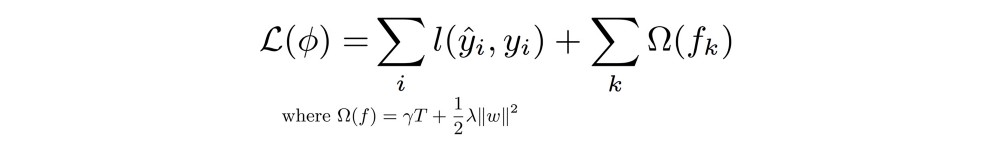
然后使用二阶梯度统计简化该目标函数,并且 - 不输入太多细节 - 可以直接用于以封闭形式计算与固定树结构相关联的最佳叶子权重。 权重可以直接与错误相关联,因此与所使用的固定结构的优点相关联(3)。
训练XGBoost是一个迭代过程,它在每个步骤计算第k个树的最佳可能分割,该第k个树枚举路径中该点仍然可用的所有可能结构。 所有可能的分裂的详尽列举非常适合本文的范围,但在实践中是不可行的,并且它被一个近似版本所取代,该版本不会尝试所有可能的分裂,而是根据百分位数列举相关的分裂。 每个功能分布。
XGBoost和缺失值:魔术发生的地方
一旦树结构被训练,就不难考虑测试集中是否存在缺失值:它足以将默认方向附加到每个决策节点。如果缺少样本的特征并且决策节点在该特征上分裂,则路径采用分支的默认方向并且路径继续。但是为每个分支分配默认方向更复杂,这可能是本文中最有趣的部分。
已经解释的拆分查找算法可以稍微调整一下,不仅返回每一步的最佳拆分,而且还返回分配给新插入的决策节点的默认方向。给定一个特征集I,枚举所有可能的分割,但是现在相应的丢失不会被计算一次而是两次,每个默认方向一次丢失该特征的缺失值。两者中最好的是根据特征m的值j进行分割时分配的最佳默认方向。最佳分割仍然是最大化计算分数的分割,但现在我们已经为其附加了默认方向。
这种算法被称为稀疏感知的分裂发现,它是XGBoost背后的许多魔力所在。最后不要太复杂。稀疏性感知方法仅保证在已经遍历的分裂的情况下平均采用默认方向导致最佳可能结果,并不保证已经遍历的分裂(可能通过采用默认方向来解决)是最好的考虑整个样本。如果样本中缺失值的百分比增加,则内置策略的性能可能会恶化很多。
好的,默认方向是最佳选择,只要它到达当前位置,但考虑到当前样本的所有特征,无法保证当前位置是最佳情况。
克服此限制意味着处理同时考虑其所有特征的样本,并直接处理同一实现中可能同时存在多个缺失值。
改变缺失值并改善表现
为了击败XGBoost内置策略,我们必须同时考虑样本的所有功能,并以某种方式处理可能存在的缺失值。 这种方法的一个很好的例子是K-Nearest Neighbors(KNN),它具有ad-hoc距离度量以正确处理缺失值。 一般而言,KNN是众所周知的算法,其将K(例如,3,10,50,……)最接近的样本检索到所考虑的样本。 它可以用于对看不见的输入进行分类或者用于估算缺失值,在分配给目标值的情况下,考虑K个最近邻居的均值或中值。 这种方法需要距离度量(或相应地,相似性度量)来实际对训练集中的所有样本进行排序并检索最相似的K.
要超越XGBoost内置默认策略,我们需要两件事:
- 考虑缺失值的距离指标(感谢AirBnb的这篇文章的灵感)
def dist_with_miss(a,b,l=0.0):if(len(a) != len(b)):return np.infls = l * np.ones(len(a))msk = ~ (np.isnan(a) | np.isnan(b))res = np.sum((np.abs(a-b)[msk]))+np.sum((ls[~msk]))return res
- 规范化数据集以获得有意义的距离,获得了不同域之间特征之间的差异(XGBoost并不严格要求,但KNN估算需要它!)。
使用K个最接近样本的所述特征的中值来估算特征的缺失值,并且在非特定情况下,在K个检索的邻居中不发现至少一个非缺失值,整个列的中值 用来。
实验结果
我使用scikit-learn中免费提供的三个众所周知的数据集(两个分类和一个回归)进行了一些测试。 通过k-fold交叉验证比较三种不同的插补策略,测量了性能:
XGBoost算法中内置的默认值
一个简单的列中位插值
一个KNN,如前一段所述
对于KNN案例,我已经绘制了针对考虑的缺失值百分比获得的最佳性能,其中k与(要考虑的邻居的数量)和λ(当至少一个特征缺失时要添加到距离的常数) 两个样本)。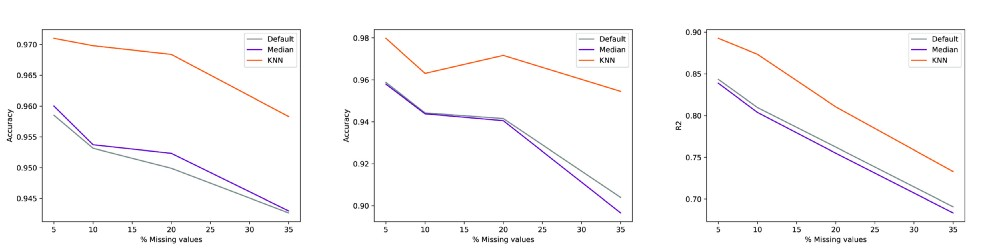
使用稀疏性感知KNN来估算缺失值与其他两种方法的表现一致。 差异的程度当然是数据集依赖的。 作为第一个天真的结论:数据集的质量越低,更好的插补策略的影响越大。 如图2所示,内置策略最终具有接近于平凡的列中值插值的性能。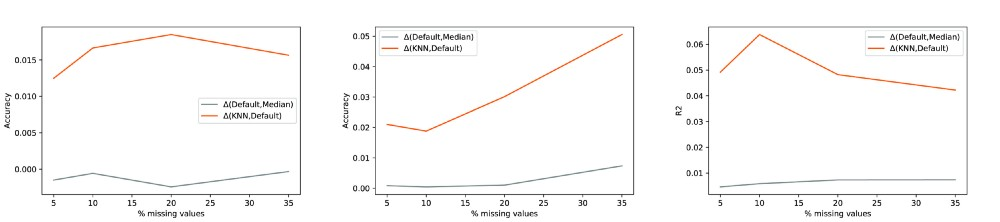
看看k和λ如何影响最终结果以及如何引入惩罚因素不仅仅是纸上谈兵,这是非常有趣的。 距离度量不仅丢弃缺失值而且还为每一个增加权重对于用该方法获得的性能是至关重要的,即使其值与缺失值的增加百分比不直接相关。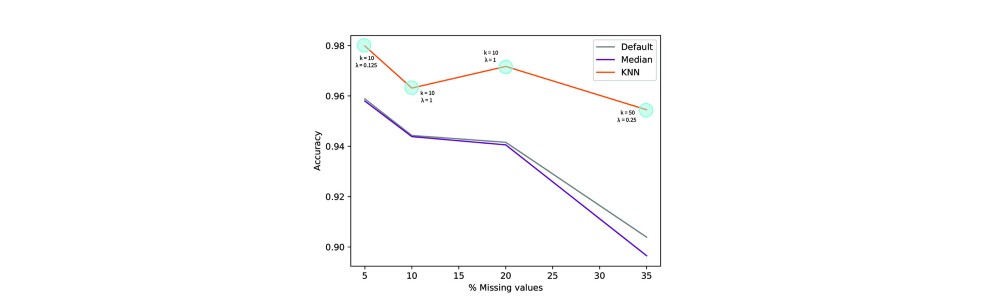
测试表明,根据经验,缺失值的数量越多,为更好的插补而考虑的邻居数量越多。 再次,一个非常直观的结论。

若有收获,就点个赞吧
0 人点赞
