使用邮政编码,纬度和经度的快速示例
作者:Kevin Velasco和Alex Shropshire
鉴于2014 - 2015年King County,WA House Sales的数据集(https://www.kaggle.com/harlfoxem/housesalesprediction),我们的任务是创建一个模型来准确预测房屋销售价格。在初步数据探索和清理之后,我们发现了大量可用信息来描述住宅的质量,但没有太多有用的信息来定位。
为什么位置对我们的数据集很重要
我们都听到过度使用的短语“位置,位置,位置”作为房地产市场评估的中心主题。人们普遍认为这是决定人们应该居住的最重要因素。价格和位置经常与买家齐头并进。任何家庭的条件,价格和规模都可能发生变化。一个常数是家的位置。
以我们的数据集的邮政编码功能为例:
在其当前形式中,在“邮政编码”列中具有70个唯一的分类值,机器学习模型不能提取每个邮政编码中包含的任何有用信息以评估与价格的关系。在这些类别中,存在一系列独特的有意义的房地产因素,如公园,学校,咖啡馆,商店,杂货店以及通行和主要道路。所有这些都是表明西雅图沃灵福德(Wallingford)社区与亚基马谷(Yakima Valley)中间的住宅区之间隐含差异的主要因素。解开价格方面的邮政编码的内在质量对于纳入我们的价格预测模型非常重要,因此我们必须适应以保持该类别的力量。
快速浏览上面的信息表明,我们需要设计新功能来理解邮政编码以及纬度和经度!
转换和理解分类数据
我们以独特的方式正确应用纬度和经度信息的方法涉及创建一个特征来衡量与贝尔维尤和西雅图主要经济中心的距离,以便改进我们的价格预测。我们决定通过如下所示的Haversine公式计算距离,而不是通过创建数学函数重新发明轮子: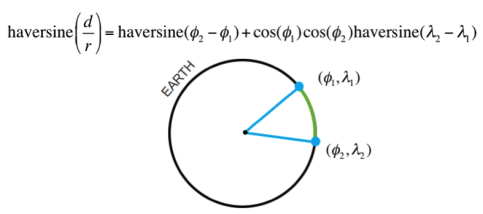
hasrsine模块(https://pypi.org/project/haversine/)为我们节省了大量时间。Haversine接收两个纬度和经度元组,并计算特定单位中两个地理点之间的地理距离。我们假设房价与西雅图市中心和贝尔维尤市区之间存在显着的关系,因为它们是该地区最大的就业和经济活动中心。我们认为较小的通勤时间和良好的主要城市资源的获取通常会增加需求,并且随之而来的是价格。
对于公式,我们需要转换每个房子的坐标。给定单独列中的纬度和经度,我们应用zip函数来创
建一个新的坐标元组列:

对于数据集中每个家庭的单点,以及两个参考点,创建了半胱氨酸公式的所有变量。将函数直接应用到现有Dataframe的新列中证明是棘手的。为了创建一个指示距离的新列,我们必须从列表数据类型创建一个Pandas系列,然后将其添加到现有的Dataframe中。
最后,我们创建了另一个列,该列选择了“distance_from_epicenter”列的两个点之间的最小距离。这一步对于获取两个城市附近的信息非常重要,以确保我们对经济中心的最短距离的解释已准备好供我们的模型解释。
对于邮政编码,我们实施了一个热编码pd.get_dummies()方法,通过该方法将分类变量转换为可以提供给ML算法的表格,以更准确地预测价格。就我们的数据而言,我们想要取一个类别的邮政编码,并将其转换为二进制是[1],此行是此邮政编码的成员,或者不是[0],它不是。绝对数量的邮政编码似乎令人震惊,在我们的数据框中添加了许多列:

但是,通过将zipcode功能转换为包含二进制信息的多个列,我们可以将其作为一个功能来包含训练模型。为了正确解释我们的模型将为所有列生成的系数,我们首先必须在pd.get_dummies()方法之后选择要删除的各种邮政编码之一,以编辑冗余信息。换句话说,我们删除一个邮政编码列,因为每个其他邮政编码列中都存在零,表示该行是我们删除的邮政编码的成员。该信息是剩余的n-1列二进制形式中固有的。我们选择删除98103的邮政编码,其中包括Wallingford,Greenlake,Phinney Ridge,Greenwood和Fremont等地区。我们之所以选择这个邮政编码,是因为它代表了一个位于西雅图市中心的中心区,我们希望可以很容易地将其解释为更具西雅图意识的观众的价格基准。我们想选择一个拉链,既不是比尔盖茨的邮政编码也不是更接近相反的极端,所以很多其他邮政编码的意思是房价高于和低于98103。最重要的是,整个过程确保我们得到的系数可以解释为98103邻域。
我们的模型改进工作的结果
经过仔细的数据清理和特征工程,我们的模型包含10个预测变量,包括一个初始的“distance_from_seattle”预测器。在通过statsmodels的普通最小二乘线性回归模型运行数据集之后,我们的总结输出得到了不错的R平方(一种快速,方便的方式来初步评估模型质量):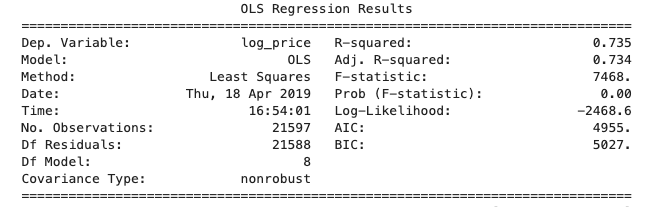
在0.735,我们的情况并不好,但还有改进的余地。意识到R平方作为模型质量的度量的局限性,为了说明基本模型迭代的场景之前和之后,它可以有勇士地服务。也就是说,在结合我们的’distance_from_epicenter’功能后,整合了西雅图市中心和贝尔维尤市中心的经济距离:
一个可观的改进!最后,通过使用单热编码将难以格式化的邮政编码类别转换为有用的数字格式: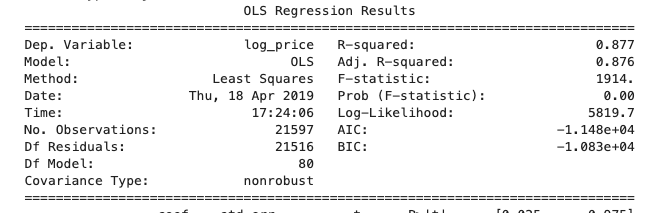
通过如此显着的提升,并且根据业务案例的潜在背景,我们可能已准备好部署我们的预测器或引入新数据,设计新功能,或者只是继续在现有数据集内迭代。我们的模型现在导致调整后的R平方为0.876。换句话说,86.7%的响应变量变化可以用我们的线性模型来解释。
最后的想法
回顾原始数据集和提供的信息,最初看起来很少有关于位置的可操作信息实际上包含强大的分类邮政编码数据和可转换的纬度和经度数据,这些数据在我们的机器学习算法中产生了巨大的改进。每个都解锁了。在理解房屋市场价格方面,“位置,位置,位置”的古老格言毕竟是真正的力量。为了从这里升级,可以考虑诸如时间,更大的地理界限和来自其他需求影响模式的数据之类的变量,特别是当房地产/房地产技术领域的高增长公司进入分析军备竞赛时才是最有见识的。我相信你们是个好人,但是我们会来找你Zillow。
有关项目详细信息,最准确的价格预测代码以及相关幻灯片,请查看我们的GitHub回购:
Alex Shropshire:
as6140 / kingcountyWA_home_price_predictor
_通过在GitHub上创建一个帐户,为as6140 / kingcountyWA_home_price_predictor开发做出贡献。_github.com
凯文韦拉斯科:
kevintheduu / dsc-1-final-project-seattle-ds-career-040119
_通过在GitHub上创建一个帐户,为kevintheduu / dsc-1-final-project-seattle-ds-career-040119开发做出贡献。_github.com

若有收获,就点个赞吧
0 人点赞
