人类能够通过捕获反射光线来观察图像,这是一项非常复杂的任务。那么如何对机器进行编程以执行类似的任务呢?计算机将图像视为矩阵,需要对其进行处理才能获得意义。
图像分割是将图像分割成各个片段的方法,每个片段具有不同的实体。卷积神经网络对于更简单的图像是成功的,但是对于复杂图像没有给出好的结果。这是U-Net和Res-Net等其他算法发挥作用的地方。
背景 - 卷积神经网络(CNN)
CNN类似于具有各种中子的神经网络,具有可学习的重量和偏差。给每个神经元提供多个输入,执行加权和,应用激活函数并给出输出。网络具有丢失功能,用于最小化权重误差。机器将图像看作像素矩阵,图像分辨率为hxwxd,其中h是高度,w是宽度,d是尺寸。d取决于色标,如RGB刻度为3,灰度为1。在CNN中,图像被转换成主要用于分类问题的向量。但是在U-Net中,图像被转换为矢量,然后使用相同的映射将其再次转换为图像。这通过保留图像的原始结构来减少失真。
当需要将整个图像分类为类标签时,主要使用CNN。但是许多任务需要对图像的每个像素进行分类。这由U-net和Res-Net解决。
U-Net架构

U-Net包括卷积操作,最大池,ReLU激活,级联和上采样层以及三个部分:收缩,瓶颈和扩展部分。收缩部分有4个收缩块。每个收缩块获得一个输入,应用两个3X3卷积ReLu层,然后是2X2最大池。每个池层的要素图数量增加一倍。瓶颈层使用两个3X3 Conv层和2X2 up卷积层。扩展部分由几个扩展块组成,每个块将输入传递到两个3X3 Conv层,以及一个2X2上采样层,将特征通道数量减半。它还包括与合同路径中相应裁剪的特征映射的串联。到底,1X1 Conv层用于使要素图的数量与输出中所需的段数相同。U-net对图像的每个像素使用损失函数。这有助于轻松识别分割图中的单个细胞。Softmax应用于每个像素,然后是损失函数。这会将分割问题转换为分类问题,我们需要将每个像素分类到其中一个类。
残差网络(Res-Net)
在传统的神经网络中,更多的层意味着更好的网络,但由于消失的梯度问题,第一层的权重将不会通过反向传播正确更新。当误差梯度向后传播到较早的层时,重复乘法会使梯度变小。因此,随着网络中更多层,其性能变得饱和并开始迅速减少。Res-Net通过使用单位矩阵解决了这个问题。当通过身份函数完成反向传播时,梯度将仅乘以1.这样可以保留输入并避免信息丢失。
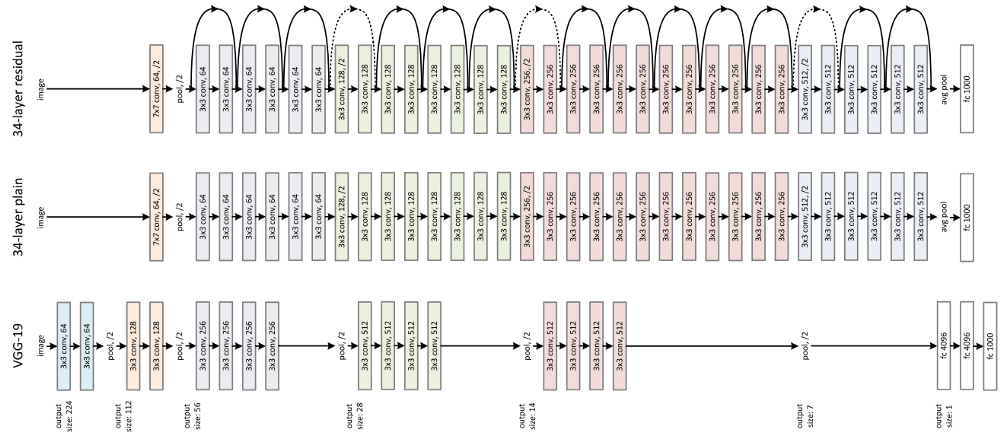
网络的组件包括3X3滤波器,具有步幅2的CNN下采样层,全局平均汇集层和最终具有softmax的1000路全连接层。
ResNet使用跳过连接,其中原始输入也被添加到卷积块的输出。这有助于通过允许梯度的替代路径流过来解决消失梯度的问题。此外,它们使用身份功能,这有助于更高层执行与更低层一样好,而不是更糟。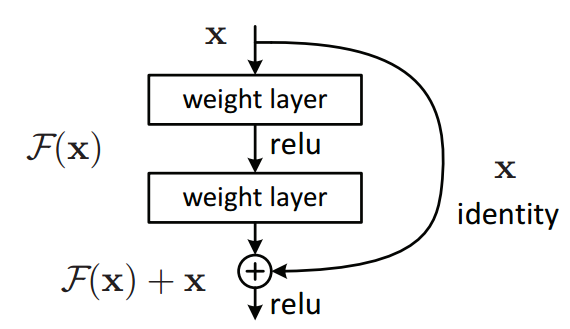
在传统的神经网络中,每层都会进入下一层。但是在具有残余块的网络中,每个层都会进入下一层,并直接进入层中的一些跳跃。
考虑一个神经网络块,其输入为x,我们希望学习真正的分布H(x)。输出和输入之间的残差可以表示为
R(x)=输出 - 输入= H(x) - x
传统网络中的层学习真实输出(H(x)),而残余网络中的层学习残差(R(x))。
希望这篇文章对Res-Nets和U-Nets有用。谢谢阅读!另外,在评论中添加我应该添加的任何其他要点或概念!

若有收获,就点个赞吧
0 人点赞
