所描述的方法有助于找到一种为XGBoost选择机器学习模型训练参数的方法

选择机器学习模型培训的参数时,总会有一些运气。最近,我特别使用渐变增强树和XGBoost。我们在企业中使用XGBoost来自动执行重复的人工任务。在使用XGBoost训练ML模型时,我创建了一个选择参数的模式,这有助于我更快地构建新模型。我将在这篇文章中分享它,希望你会发现它也很有用。
我正在使用皮马印第安人糖尿病数据库进行培训,可以从这里下载CSV数据。
这是运行XGBoost训练步骤并构建模型的Python代码。通过传递成对的训练/测试数据来执行训练,这有助于在模型构建期间临时评估训练质量:
%%timemodel = xgb.XGBClassifier(max_depth=12,subsample=0.33,objective='binary:logistic',n_estimators=300,learning_rate = 0.01)eval_set = [(train_X, train_Y), (test_X, test_Y)]model.fit(train_X, train_Y.values.ravel(), early_stopping_rounds=15, eval_metric=["error", "logloss"], eval_set=eval_set, verbose=True)
validation_0-error:0.231518 validation_0-logloss:0.688982 validation_1-error:0.30315 validation_1-logloss:0.689593Multiple eval metrics have been passed: 'validation_1-logloss' will be used for early stopping.Will train until validation_1-logloss hasn't improved in 15 rounds.[1] validation_0-error:0.206226 validation_0-logloss:0.685218 validation_1-error:0.216535 validation_1-logloss:0.686122[2] validation_0-error:0.196498 validation_0-logloss:0.681505 validation_1-error:0.220472 validation_1-logloss:0.682881[3] validation_0-error:0.196498 validation_0-logloss:0.67797 validation_1-error:0.220472 validation_1-logloss:0.679601[4] validation_0-error:0.180934 validation_0-logloss:0.674278 validation_1-error:0.208661 validation_1-logloss:0.676067[5] validation_0-error:0.177043 validation_0-logloss:0.670627 validation_1-error:0.212598 validation_1-logloss:0.673761[6] validation_0-error:0.175097 validation_0-logloss:0.667069 validation_1-error:0.216535 validation_1-logloss:0.671441[7] validation_0-error:0.18677 validation_0-logloss:0.663582 validation_1-error:0.212598 validation_1-logloss:0.668586[8] validation_0-error:0.180934 validation_0-logloss:0.660353 validation_1-error:0.23622 validation_1-logloss:0.665983[9] validation_0-error:0.161479 validation_0-logloss:0.656739 validation_1-error:0.228346 validation_1-logloss:0.662987[10] validation_0-error:0.167315 validation_0-logloss:0.653582 validation_1-error:0.228346 validation_1-logloss:0.660091[259] validation_0-error:0.122568 validation_0-logloss:0.34313 validation_1-error:0.220472 validation_1-logloss:0.475866[260] validation_0-error:0.124514 validation_0-logloss:0.34261 validation_1-error:0.220472 validation_1-logloss:0.476068[261] validation_0-error:0.120623 validation_0-logloss:0.342156 validation_1-error:0.216535 validation_1-logloss:0.476165[262] validation_0-error:0.120623 validation_0-logloss:0.341714 validation_1-error:0.216535 validation_1-logloss:0.476143[263] validation_0-error:0.124514 validation_0-logloss:0.341209 validation_1-error:0.216535 validation_1-logloss:0.476063[264] validation_0-error:0.120623 validation_0-logloss:0.340779 validation_1-error:0.220472 validation_1-logloss:0.47595[265] validation_0-error:0.120623 validation_0-logloss:0.340297 validation_1-error:0.212598 validation_1-logloss:0.475858[266] validation_0-error:0.120623 validation_0-logloss:0.339908 validation_1-error:0.212598 validation_1-logloss:0.476057[267] validation_0-error:0.120623 validation_0-logloss:0.339312 validation_1-error:0.220472 validation_1-logloss:0.476228[268] validation_0-error:0.120623 validation_0-logloss:0.338874 validation_1-error:0.216535 validation_1-logloss:0.476266[269] validation_0-error:0.120623 validation_0-logloss:0.338543 validation_1-error:0.216535 validation_1-logloss:0.476202[270] validation_0-error:0.120623 validation_0-logloss:0.33821 validation_1-error:0.216535 validation_1-logloss:0.47607[271] validation_0-error:0.120623 validation_0-logloss:0.337716 validation_1-error:0.212598 validation_1-logloss:0.476229[272] validation_0-error:0.118677 validation_0-logloss:0.337295 validation_1-error:0.212598 validation_1-logloss:0.47612[273] validation_0-error:0.118677 validation_0-logloss:0.336927 validation_1-error:0.212598 validation_1-logloss:0.476152[274] validation_0-error:0.118677 validation_0-logloss:0.33651 validation_1-error:0.212598 validation_1-logloss:0.476127[275] validation_0-error:0.120623 validation_0-logloss:0.336017 validation_1-error:0.216535 validation_1-logloss:0.476117[276] validation_0-error:0.120623 validation_0-logloss:0.335497 validation_1-error:0.212598 validation_1-logloss:0.476063[277] validation_0-error:0.116732 validation_0-logloss:0.335159 validation_1-error:0.216535 validation_1-logloss:0.476113[278] validation_0-error:0.114786 validation_0-logloss:0.334812 validation_1-error:0.216535 validation_1-logloss:0.476143[279] validation_0-error:0.114786 validation_0-logloss:0.334481 validation_1-error:0.216535 validation_1-logloss:0.476163[280] validation_0-error:0.116732 validation_0-logloss:0.333843 validation_1-error:0.216535 validation_1-logloss:0.476359Stopping. Best iteration:[265] validation_0-error:0.120623 validation_0-logloss:0.340297 validation_1-error:0.212598 validation_1-logloss:0.475858CPU times: user 690 ms, sys: 310 ms, total: 1 sWall time: 799 ms
假设您已经选择了max_depth(更复杂的分类任务,更深的树),子样本(等于评估数据百分比),目标(分类算法):XGBoost中的关键参数(会大大影响模型质量的那些)
- n_estimators - XGBoost将尝试学习的运行次数
- learning_rate - 学习速度
- early_stopping_rounds - 过度预防,如果学习没有改善就提前停止
当使用verbose = True执行model.fit时,您将看到打印出的每个训练运行评估质量。在日志的末尾,您应该看到哪个迭代被选为最佳迭代。可能是训练轮的数量不足以检测最佳迭代,然后XGBoost将选择最后一次迭代来构建模型。
使用matpotlib库,我们可以绘制每次运行的训练结果(来自XGBoost输出)。这有助于理解为构建模型而选择的迭代是否是最好的。在这里,我们使用sklearn库来评估模型的准确性,然后用matpotlib绘制训练结果:
# make predictions for test datay_pred = model.predict(test_X)predictions = [round(value) for value in y_pred]
# evaluate predictionsaccuracy = accuracy_score(test_Y, predictions)print("Accuracy: %.2f%%" % (accuracy * 100.0))
Accuracy: 78.74%
# retrieve performance metricsresults = model.evals_result()epochs = len(results['validation_0']['error'])x_axis = range(0, epochs)# plot log lossfig, ax = pyplot.subplots()ax.plot(x_axis, results['validation_0']['logloss'], label='Train')ax.plot(x_axis, results['validation_1']['logloss'], label='Test')ax.legend()pyplot.ylabel('Log Loss')pyplot.title('XGBoost Log Loss')pyplot.show()# plot classification errorfig, ax = pyplot.subplots()ax.plot(x_axis, results['validation_0']['error'], label='Train')ax.plot(x_axis, results['validation_1']['error'], label='Test')ax.legend()pyplot.ylabel('Classification Error')pyplot.title('XGBoost Classification Error')pyplot.show()

让我们描述我为XGBoost训练选择参数(n_estimators,learning_rate,early_stopping_rounds)的方法。
第1步。从您的经验或有意义的开始,您感觉最好
- n_estimators = 300
- learning_rate = 0.01
- early_stopping_rounds = 10
结果:
- 停止迭代= 237
- 准确度= 78.35%
结果图: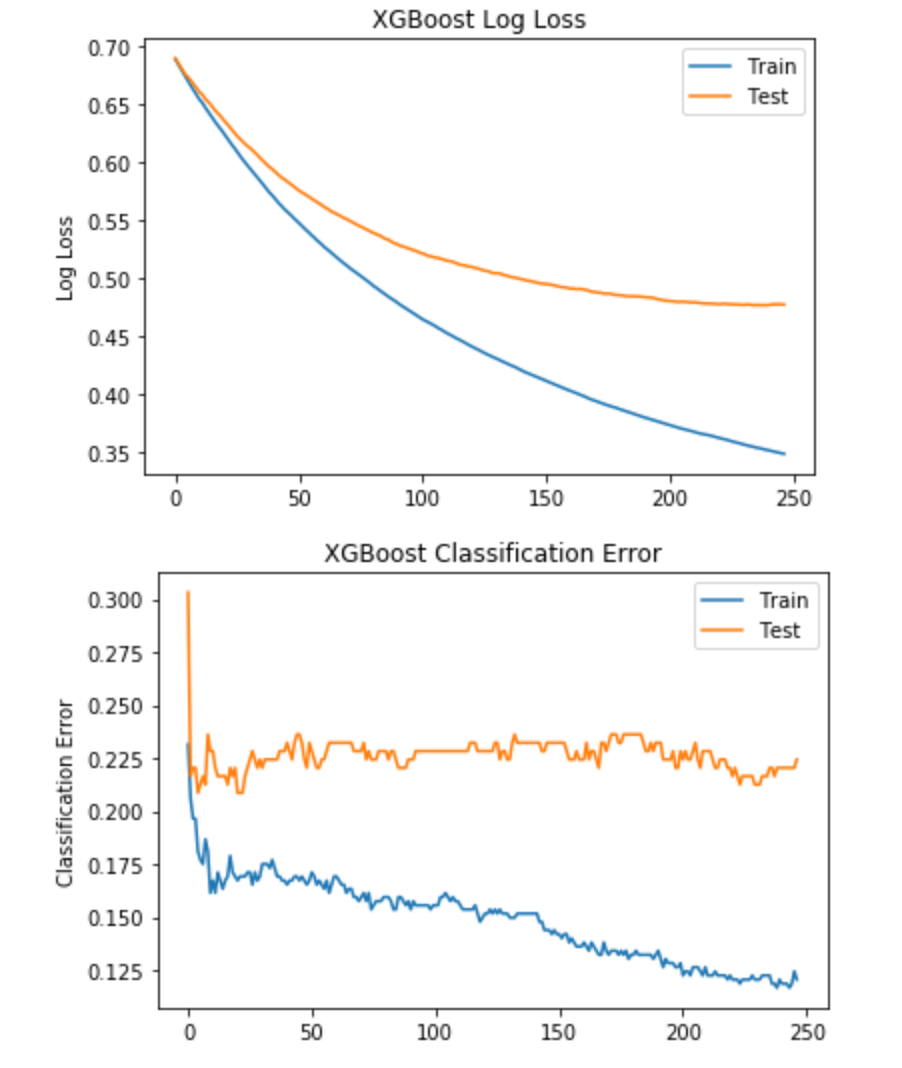
通过第一次尝试,我们已经为Pima Indians Diabetes数据集获得了良好的结果。在迭代237停止训练。分类错误图显示迭代237周围的较低错误率。这意味着学习率0.01适合于该数据集并且提前停止10次迭代(如果结果在接下来的10次迭代中没有改善) 。
第2步。尝试学习率,尝试设置较小的学习率参数并增加学习迭代次数
- n_estimators = 500
- learning_rate = 0.001
- early_stopping_rounds = 10
结果:
- 停止迭代=没有停止,花了所有500次迭代
- 准确度= 77.56%
结果图: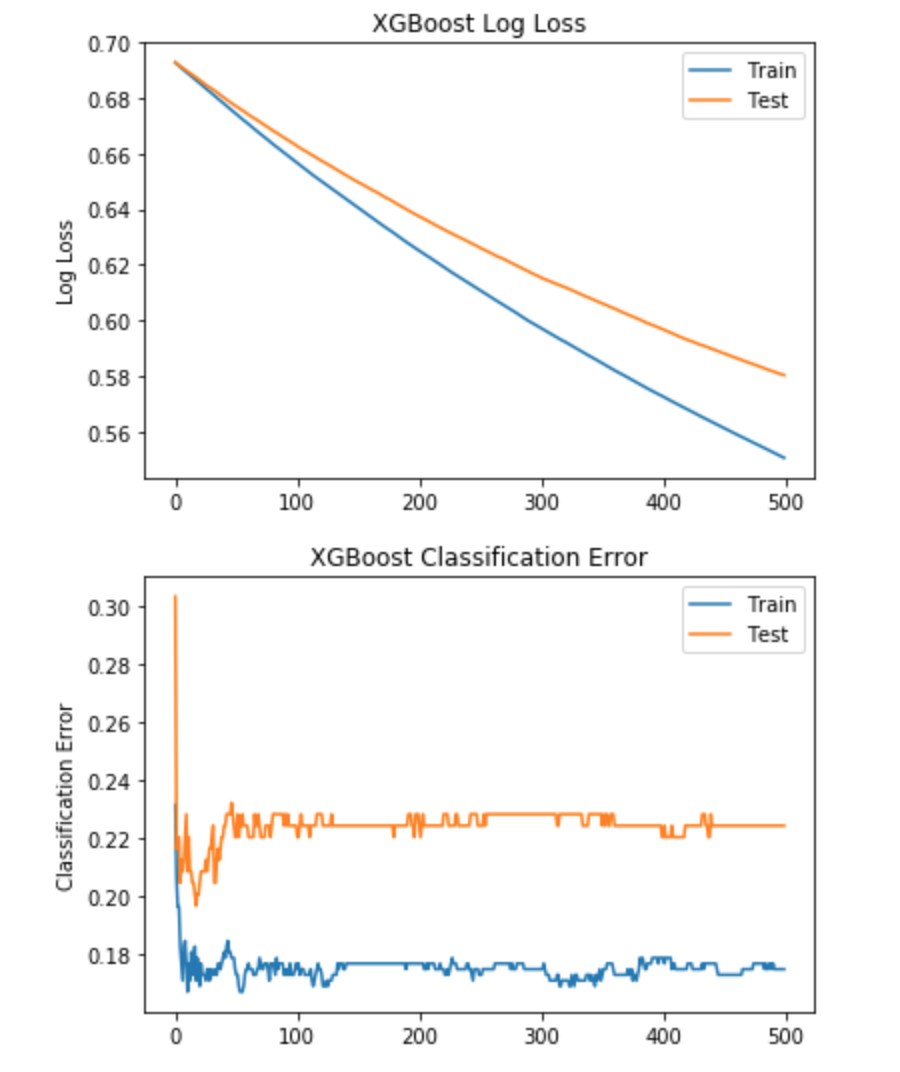
较小的学习率对此数据集无效。分类错误几乎不会改变,即使500次迭代,XGBoost日志丢失也不会稳定。
第3步。尽量提高学习率。
- n_estimators = 300
- learning_rate = 0.1
- early_stopping_rounds = 10
结果:
- 停止迭代= 27
- 准确度= 76.77%
结果图:
随着学习速度的提高,算法学得更快,在迭代次数Nr时就停止了。27. XGBoost日志丢失错误正在稳定,但整体分类精度并不理想。
第4步。从第一步中选择最佳学习率并增加早期停止(以使算法有更多机会找到更好的结果)。
- n_estimators = 300
- learning_rate = 0.01
- early_stopping_rounds = 15
结果:
- 停止迭代= 265
- 准确度= 78.74%
结果图:
产生稍好的结果,准确度为78.74% - 这在分类误差图中可见。
资源:
GitHub上的 Jupyter笔记本
博客文章 - Jupyter Notebook - 忘记CSV,用Python从DB获取数据
博客文章 - 通过Python中的XGBoost提前停止来避免过度拟合

若有收获,就点个赞吧
0 人点赞
