我们将说明如何使用一系列工具(即Kafka,MLFlow和Sagemaker)来帮助生产ML。为此,我们将设置一个简单的场景,我们希望它类似于一些真实用例,然后描述一个潜在的解决方案。可以在此处找到包含所有代码的伴随仓库。
场景
公司使用一系列服务收集数据,这些服务在用户/客户与公司的网站或应用程序交互时生成事件。当这些交互发生时,算法需要实时运行,并且需要根据算法的输出(或预测)采取一些立即行动。最重要的是,经过ñ相互作用(或意见)的算法需要重新训练不停止的预测 服务,因为用户将保持互动。
对于这里的练习,我们使用了成人数据集,其目标是根据年龄,原籍国等来预测个人是否获得高于/低于50k的收入。为了使该数据集适应前面描述的情景,可以假设通过在线问卷/表格收集该年龄,本国等,我们需要预测用户是否实时获得高/低收入。如果收入高,那么我们会立即给他们打电话/给他们发电子邮件。然后,在N个新观察之后,我们重新训练算法,同时我们继续预测新用户。
解决方案
图1是潜在解决方案的图示。为了实现这个解决方案,我们使用了Kafka-Python(可以在这里找到一个很好的教程),以及LightGBM和Hyperopt或HyperparameterHunter。
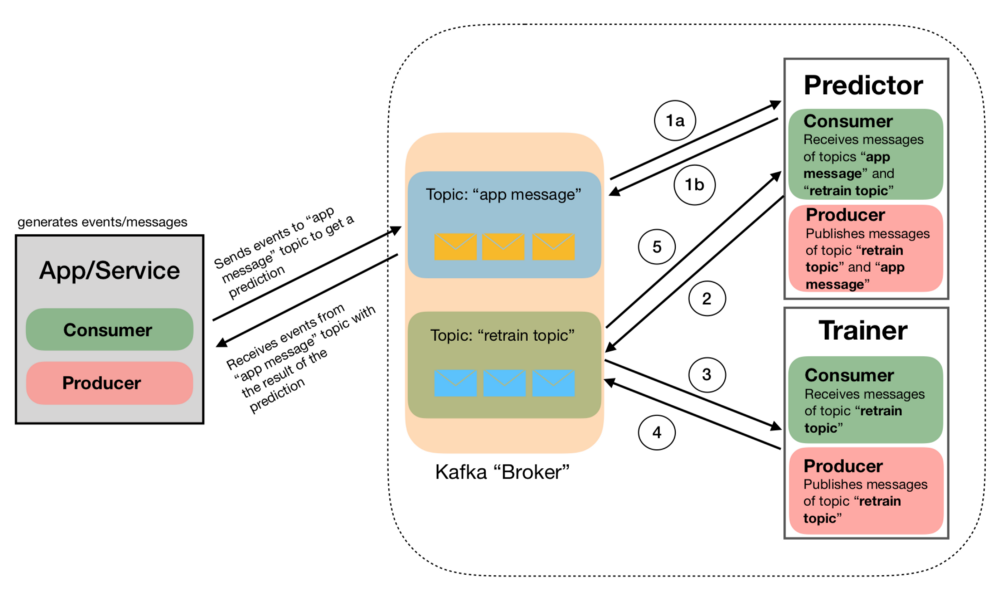
图1. 实时预测ML管道。以下提供完整描述
我们将在本练习中使用的唯一Python“局外人”是Apache-Kafka(我们将使用python API Kafka-Python,但仍然需要在您的系统中安装Kafka)。如果你在Mac上,只需使用Homebrew:
brew install kafka
这也将安装zookeeper依赖项。
如前所述,我们使用了Adult数据集。这是因为我们的目的是说明潜在的ML管道并提供有用的代码,同时保持相对简单。但请注意,此处描述的管道原则上与数据无关。当然,预处理将根据数据的性质而改变,但如果不相同,管道组件将保持相似。
初始化实验
您可以在我们的仓库中找到用于此帖子的代码(以及更多)。在那里,有一个名为的脚本initialize.py 。该脚本将下载数据集,设置目录结构,预处理数据,在训练数据集上训练初始模型并优化该模型的超参数。在现实世界中,这将对应于通常的实验阶段和离线训练初始算法的过程。
在这篇文章中,我们希望主要关注管道和相应的组件而不是ML。尽管如此,让我们简单地提一下我们在本练习中使用的ML工具。
鉴于我们正在使用的数据集,数据预处理非常简单。我们编写了一个名为的自定义类[FeatureTools](https://github.com/jrzaurin/ml_pipelines/blob/master/utils/feature_tools.py),可以utils在repo 中的模块中找到。这个类有.fit和 .transform方法将标准化/缩放数字特征,编码分类特征并生成我们称之为“交叉列”,这是两个(或更多)分类特征之间的笛卡尔积的结果。
处理完数据后,我们使用LightGBM将模型与Hyperopt或HyperparameterHunter相匹配,以执行超参数优化。可以在train模块中找到与此任务相关的代码,其中可以找到两个脚本[train_hyperop](https://github.com/jrzaurin/ml_pipelines/blob/master/train/train_hyperopt.py).py和[train_hyperparameterhunter](https://github.com/jrzaurin/ml_pipelines/blob/master/train/train_hyperparameterhunter.py).py 。
我们可能会在python(Skopt,Hyperopt和HyperparameterHunder)中编写一个单独的帖子来比较超参数优化包,但是现在,请知道:如果你想要速度,那么使用Hyperopt。如果您不关心速度并且想要详细跟踪优化例程,请使用HyperparameterHunter。用Hunter McGushion 的话来说,包装的创造者:
“长期以来,超参数优化一直是一个耗时的过程,只是指向了进一步优化的方向,然后你基本上不得不重新开始。”
HyperparameterHunter就是为了解决这个问题,它做得非常好。目前,该软件包是建立在Skopt之上的,这就是为什么它比Hyperopt慢得多。但是,我知道有人努力将Hyperopt作为HyperparameterHunter的另一个后端包含在内。当发生这种情况时,不会有任何争议,HyperparameterHunter应该是您的首选工具。
尽管如此,如果有人感兴趣,我在回购中包含了一个笔记本,比较了Skopt和Hyperopt的表现。
让我们现在转到管道流程本身。
App Messages Producer
这意味着生产管道的哪个部分可能看起来相对简单。因此,我们直接使用Adult数据集生成消息(JSON对象)。
在现实世界中,人们将拥有许多可以生成事件的服务。从那里,有一个选项。这些事件中的信息可能存储在数据库中,然后通过常规查询进行汇总。从那里,Kafka服务将消息发布到管道中。或者,这些事件中的所有信息可以直接发布到不同的主题中,“聚合服务”可以将所有信息存储在单个消息中,然后将其发布到管道中(当然,也可以组合使用他们俩)。
例如,可能允许用户通过Facebook或Google注册,收集他们的姓名和电子邮件地址。然后他们可能会被要求填写调查问卷,我们会继续收集他们进展的事件。在此过程中的某个时刻,所有这些事件将在单个消息中聚合,然后通过Kafka生产者发布。这篇文章中的管道将从聚合了所有相关信息的点开始。我们这里的消息是Adult数据集中的单个观察。下面我们将包含消息内容的示例:
’{“age”:25,”workclass”:”Private”,”fnlwgt”:226802,”education”:”11th”,”marital_status”:”Never-married”,”occupation”:”Machine-op-inspct”,”relationship”:”Own-child”,”race”:”Black”,”gender”:”Male”,”capital_gain”:0,”capital_loss”:0,”hours_per_week”:40,”native_country”:”United-States”,”income_bracket”:”<=50K.”}’
App / Service的核心(图1中最灰色,最左边的框)是下面的代码段:
df_test = pd.read_csv(PATH/'adult.test')df_test['json'] = df_test.apply(lambda x: x.to_json(), axis=1)messages = df_test.json.tolist()def start_producing():producer = KafkaProducer(bootstrap_servers=KAFKA_HOST)for i in range(200):message_id = str(uuid.uuid4())message = {'request_id': message_id, 'data': json.loads(messages[i])}producer.send('app_messages', json.dumps(message).encode('utf-8'))producer.flush()print("\033[1;31;40m -- PRODUCER: Sent message with id {}".format(message_id))sleep(2)def start_consuming():consumer = KafkaConsumer('app_messages', bootstrap_servers=KAFKA_HOST)for msg in consumer:message = json.loads(msg.value)if 'prediction' in message:request_id = message['request_id']print("\033[1;32;40m ** CONSUMER: Received prediction {} for request id {}".format(message['prediction'], request_id))
请注意,我们使用测试数据集来生成消息。这是因为我们设计了一个尽可能与真实世界相似的场景(在一定限度内)。考虑到这一点,我们使用训练数据集来构建初始model和dataprocessor对象。然后,我们使用测试数据集生成消息,目的是模拟随时间接收新信息的过程。
关于上面的代码片段,简单地说,生产者会将消息发布到管道(start_producing())中并使用带有最终预测(start_consuming())的消息。与我们在此描述的管道不同的方式不包括流程的开始(事件收集和聚合),我们也跳过最后,即如何处理最终预测。尽管如此,我们还是简要讨论了一些用例,这些用例可能会在帖子结尾处有用,这将说明最后阶段。
实际上,除了忽略过程的开始和结束之外,我们认为这条管道在现实世界中可以使用的管道相当好。因此,我们希望我们的仓库中包含的代码对您的某些项目有用。
预测者和训练师
该实现的主要目标是实时运行算法并在不停止预测服务的情况下每N次观察重新训练它。为此,我们实现了两个组件,Predictor(在repo中)和Trainer()。[predictor](https://github.com/jrzaurin/ml_pipelines/blob/master/predictor.py).py``[trainer](https://github.com/jrzaurin/ml_pipelines/blob/master/trainer.py).py
现在让我们逐一描述图1中显示的数字,使用代码片段作为我们的指南。请注意,下面的过程假设有一个运行initialize.py脚本,因此初始文件model.p和dataprocessor.p文件存在于相应的目录中。另外,请强调下面的代码包含Predictor和Trainer的核心。有关完整代码,请参阅回购。
预报器
Predictor代码的核心如下所示
def start(model_id, messages_count, batch_id):for msg in consumer:message = json.loads(msg.value)if is_retraining_message(msg):model_fname = 'model_{}_.p'.format(model_id)model = reload_model(MODELS_PATH/model_fname)print("NEW MODEL RELOADED {}".format(model_id))elif is_application_message(msg):request_id = message['request_id']pred = predict(message['data'], column_order)publish_prediction(pred, request_id)append_message(message['data'], MESSAGES_PATH, batch_id)messages_count += 1if messages_count % RETRAIN_EVERY == 0:model_id = (model_id + 1) % (EXTRA_MODELS_TO_KEEP + 1)send_retrain_message(model_id, batch_id)batch_id += 1
(1a)predictor.py片段中的第12行。预测器将从应用程序/服务接收消息,它将进行数据处理并在接收消息时实时运行模型。所有这些都是使用函数中的现有对象dataprocessor和model对象发生的predict。
(1b)predictor.py片段中的第13行。一旦我们运行预测,Predictor将发布publish_prediction()最终将由App / Service接收的result()。
(2)predictor.py片段中的第17-20行。每条RETRAIN_EVERY消息,Predictor都会发布一条“ 重新训练 ”消息(send_retrain_message()),由培训师阅读。
训练者
def start():consumer = KafkaConsumer(RETRAIN_TOPIC, bootstrap_servers=KAFKA_HOST)for msg in consumer:message = json.loads(msg.value)if 'retrain' in message and message['retrain']:model_id = message['model_id']batch_id = message['batch_id']message_fname = 'messages_{}_.txt'.format(batch_id)messages = MESSAGES_PATH/message_fnametrain(model_id, messages)publish_traininig_completed(model_id)
(3)trainer.py片段中的第12行。培训师将阅读该消息并使用新的累积数据集(train())触发重新训练过程。
这是原始数据集加上RETRAIN_EVERY新的观察结果。列车功能将独立于1a和1b中描述的过程运行“初始化实验” 部分中描述的整个过程。换句话说,训练者将重新训练模型,而预测器在消息到达时保持预测。
在这个阶段值得一提的是,在这里我们发现我们的实现与将在现实世界中使用的实现之间存在进一步的差异。在我们的实现中,一旦处理了RETRAIN_EVERY多个观察结果,就可以重新训练算法。这是因为我们使用Adult测试数据集来生成消息,其中包括目标列(“ income_braket ”)。在真实的单词中,基于算法输出所采取的动作的真实结果通常在算法运行之后不容易访问,但是一段时间之后。在那种情况下,另一个过程应该是收集真实的结果,一旦收集的真实结果的数量等于RETRAIN_EVERY算法将被重新训练。
例如,假设此管道实现了电子商务的实时推荐系统。我们已经离线训练了一个推荐算法,目标列是我们的用户喜欢我们建议的分类表示:0,1,2和3对于不喜欢或与项目交互的用户,喜欢该项目(例如点击像按钮),将项目添加到他们的篮子,并分别购买该项目。当系统提供建议时,我们仍然不知道用户最终会做什么。
因此,随着用户信息在网站(或应用程序)中导航时收集和存储用户信息,第二个过程应该收集我们建议的最终结果。只有当两个进程都收集了RETRAIN_EVERY消息和结果时,才会对算法进行重新训练。
(4)trainer.py片段中的第13行。重新训练完成后,将发布带有相应信息的消息(published_training_completed())。
(5)predictor.py片段中的第5-8行。Predictor的消费者订阅了两个主题:[‘app_messages’, ‘retrain_topic’]。一旦它通过“retrain_topic”接收到重新训练完成的信息,它将加载新模型并像往常一样保持过程,而不会在过程中的任何时间停止。
如何运行管道
在配套仓库中,我们已经包含了如何运行管道(本地)的说明。其实很简单。
- 启动zookeper和kafka:
$ brew services start zookeeper==> Successfully started `zookeeper` (label: homebrew.mxcl.zookeeper)$ brew services start kafka==> Successfully started `kafka` (label: homebrew.mxcl.kafka)
2.运行initialize.py:
python initialize.py
3.在终端#1中运行预测器(或训练器):
python predictor.py
4.在终端#2中运行训练器(或预测器):
python trainer.py
5.在终端#3中运行示例应用程序
python samplea_app.py
然后,一旦处理了N条消息,您应该看到如下内容:
右上方终端:我们重新训练了模型,Hyperopt已经进行了10次评估(在实际练习中,这些应该是几百次)。左上方终端:一旦对模型进行了重新训练和优化,我们就会看到预测器如何加载新模型(在新LightGBM版本的恼人警告消息之后)。底部终端:服务照常进行。

一些潜在的用例
以下是(很多)其他一些潜在用例。
实时调整在线旅程
让我们考虑出售一些商品的电子商务。当用户浏览网站时,我们会收集有关其行为信息的活动。我们之前已经培训了一种算法,我们知道在10次交互之后,我们可以很好地了解客户是否最终会购买我们的产品。此外,我们也知道他们可能购买的产品可能会很昂贵。因此,我们希望“在旅途中”定制他们的旅程,以促进他们的购物体验。这里的定制可能意味着什么,从缩短行程到改变页面布局。
2. 电子邮件/致电您的客户
与之前的用例类似,我们现在假设客户决定停止旅程(无聊,缺乏时间,可能太复杂等)。如果算法预测该客户具有很大的潜力,我们可以立即使用像本文所述的管道,或者使用受控延迟,发送电子邮件或调用它们。
下一步
记录和监控:在即将发布的帖子中,我们将通过MLFlow在管道记录和监控功能中插入。与HyperparameterHunter一起,该解决方案将自动跟踪模型性能和超参数优化,同时提供可视化监控。
流量管理:此处描述的解决方案以及相应的代码已经过设计,因此可以在笔记本电脑中轻松地在本地和手动运行。然而,人们会认为在现实生活中,这将需要大规模运行云,而不是手动(请)。在那个阶段,如果我们可以使用涵盖整个机器学习工作流程的完全托管服务,那将是理想的,因此我们不需要关心维护服务,版本控制等。为此目的,我们将使用Sagemaker,它是构建的正是为了这个目的。

若有收获,就点个赞吧
0 人点赞
