动机
我目前正在做一个fast.ai Live MOOC,名为《Practical Deep learning for Coders》,将于2019年1月在fast.ai网站上公开发布。 以下代码基于该课程的第1课。 我将使用位于Pytorch 1.0顶部的fastai V1库。 fastai库提供了许多有用的功能,使我们能够快速,轻松地构建神经网络并训练我们的模型。 我正在撰写此博客,作为在数据集上试验课程示例的一部分,该数据集在结构和复杂性上有所不同,并表明使用fastai库是多么容易。
在下面的例子中,您将看到在PlantVintage数据集上进行转移学习并获得世界级结果是多么荒谬。 PlantVintage数据包含植物叶片的图像,其中包括通常在作物上发现的38种疾病类别,是来自斯坦福大学背景图像开放数据集的一个背景类别—DAGS。 我从这个Github Repo上给出的链接下载了数据。 我对这个例子特别感兴趣,因为在我写这篇博客的时候,我为一个帮助农民发展业务的组织工作,提供产品和技术解决方案,以便更好地管理农场。 让我们开始吧!
PS:这个博客也在我的GitHub个人资料中作为jupyter笔记本发布。
导入快速AI库
让我们导入fastai库并将我们的batch_size参数定义为64.通常,图像数据库很大,所以我们需要使用批量将这些图像提供给GPU,批量大小64意味着我们将一次提供64个图像来更新深度参数 学习模式。 如果由于GPU RAM较小而导致内存不足,则可以将批量大小减小到32或16。
from fastai import *from fastai.vision import *bs =64
看数据
我们处理问题时首先要做的是查看数据。 在我们弄清楚如何解决问题之前,我们总是需要很好地理解问题是什么以及数据是什么样的。 查看数据意味着了解数据目录的结构,标签是什么以及一些示例图像是什么样的。 我们的数据已经在train和validation文件夹中分割,在每个子目录中,我们的文件夹名称代表该子文件夹中存在的所有图像的类名。 幸运的是,fastai库有一个方便的功能,ImageDataBunch.from_folder自动从文件夹名称中获取标签名称。 fastai库提供了很棒的文档来浏览它们的库函数,并提供有关如何使用它们的实例。 加载数据后,我们还可以使用.normalize到ImageNet参数来规范化数据。
## Declaring path of datasetpath_img = Path('/home/jupyter/fastai_v3_experimentation/data/PlantVillage/')## Loading datadata = ImageDataBunch.from_folder(path=path_img, train='train', valid='valid', ds_tfms=get_transforms(),size=224, bs=bs, check_ext=False)## Normalizing data based on Image net parametersdata.normalize(imagenet_stats)
要查看随机的图像样本,我们可以使用.show_batch()函数ImageDataBunch类。 正如我们在下面所看到的,我们有一些不同作物上的疾病病例加上来自DAGS数据集的一些背景噪声图像,这些图像将作为噪声。
data.show_batch(rows=3, figsize=(10,8))

让我们打印数据库中存在的所有数据类。 总的来说,我们在动机部分中提到了39个课程中的图像。
print(data.classes)len(data.classes),data.c

使用预先训练的模型转移学习:ResNet 50
现在我们将开始训练我们的模型。 我们将使用卷积神经网络骨干ResNet 50和具有单个隐藏层的完全连接头作为分类器。 如果您想了解所有架构细节,也可以阅读ResNet论文。 要创建转移学习模型,我们需要使用Learner类中的函数create_cnn,并从模型类中提供预先训练的模型。
## To create a ResNET 50 with pretrained weightslearn = create_cnn(data, models.resnet50, metrics=error_rate)
由create_cnn函数创建的ResNet50模型具有冻结的初始层,我们将学习最后完全连接的层的权重。
learn.fit_one_cycle(5)

正如我们在上面看到的那样,只使用默认设置运行五个周期,我们对这个细粒度分类任务的准确度在验证数据集上约为99.64%。 让我们保存模型,因为我们稍后会对其进行微调。 如果你想知道这个结果有多好,它已经超过了这个Github Page的96.53%的浅层学习(仅培训最后一层)基准。
learn.save('plant_vintage_stage1')
FastAI库还提供了更快地探索结果的功能,并查找我们的模型是否正在学习应该学习的内容。 我们将首先看到模型最混淆的类别。 我们将尝试使用ClassificationInterpretation类来查看模型预测的是否合理。
interp = ClassificationInterpretation.from_learner(learn)interp.plot_top_losses(4, figsize=(20,25))

在这种情况下,该模型在从玉米植株上的灰色叶斑病和番茄叶片中的早/晚疫病检测北叶枯病方面变得混乱,其在视觉上看起来非常相似。 这是我们的分类器正常工作的指示器。 此外,当我们绘制混淆矩阵时,我们可以看到大多数事物都被正确分类,并且它几乎是一个接近完美的模型。
interp.plot_confusion_matrix(figsize=(20,20), dpi=60)

所以到目前为止,我们只训练了最后的分类层,但是如果我们想要优化早期的层也会如此。 在迁移学习中,应谨慎调整初始图层,学习率应保持在较低水平。 FastAI库提供了一个功能,可以查看要训练的理想学习速率,让我们绘制它。 lr_find函数以多学习速率运行数据子集的模型,以确定哪种学习速率最佳。
learn.lr_find()learn.recorder.plot()
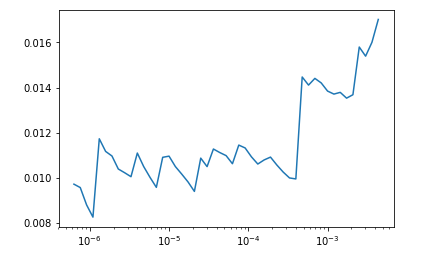
看起来我们应该保持低于10e-4的学习率。 对于网络中的不同层,我们可以使用切片函数来对数分布10e-6到10e-4之间的学习速率。 保持初始层的最低学习速率,并为后续层增加它。 让我们解冻所有层,以便我们可以使用unfreeze()函数训练整个模型。
learn.unfreeze()learn.fit_one_cycle(2, max_lr=slice(1e-7,1e-5))

正如我们通过训练所有层次所看到的,我们将准确度提高到99.7%,这与使用Inception-v3模型的Github基准测试中的99.76%相当。
结论
Fast.ai是Jeremy Howard和他的团队的一项出色的倡议,我相信fastai库可以通过使构建深度学习模型变得非常简单,真正实现将深度学习民主化的动机。
我希望你喜欢阅读,并随意使用我的代码为你的目的尝试。 此外,如果对代码或博客文章有任何反馈,请随时联系LinkedIn或发送电子邮件至aayushmnit@gmail.com。
PS:如果你喜欢这些内容,请留下评论或鼓掌,并希望我更频繁地写这样的博客。

若有收获,就点个赞吧
0 人点赞
