
如果您想知道如何使用dropout,这里有您要的答案。
我注意到有很多资源可以用来学习深度学习的内容和原因。 不幸的是,当需要制作模型时,他们很少有资源来解释何时以及如何。
我正在为试图实施深度学习的其他数据科学家撰写本文。 因此,您不必像我一样通过研究文章和Reddit讨论。
在本文中,您将了解为什么dropout在卷积体系结构中不再受欢迎。
DROPOUT
如果你正在读这篇文章,我认为你已经了解了什么是dropout,以及它在正则化神经网络方面的作用。 如果您想要复习,请阅读Amar Budhiraja的这篇文章。
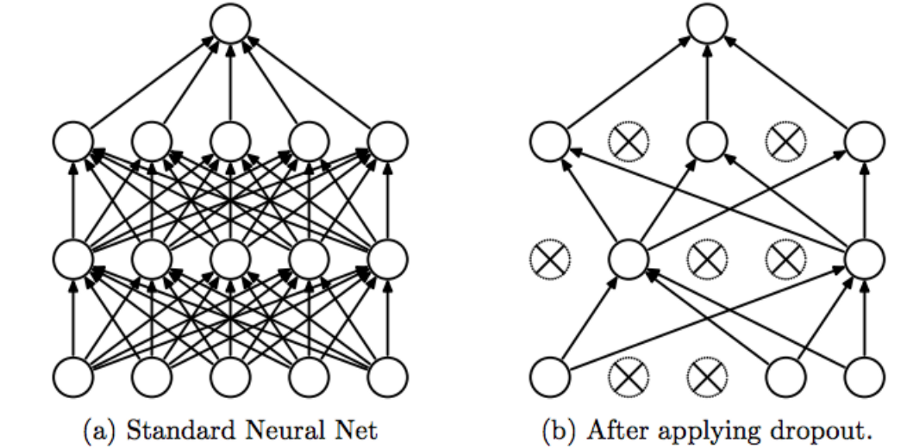
通常,当我们的网络存在过度拟合的风险时,我们只需要实现正规化。 如果网络太大,如果您训练时间过长,或者您没有足够的数据,则会发生这种情况。
如果在卷积网络末端有完全连接的层,则实现dropout很容易。
使用Keras
keras.layers.Dropout(rate, noise_shape=None, seed=None)
以0.5的dropout率开始并将其调低,直到性能最大化。 (资源)
例如
model=keras.models.Sequential()model.add(keras.layers.Dense(150, activation="relu"))model.add(keras.layers.Dropout(0.5))
请注意,这仅适用于您的convnet的完全连接区域。 对于所有其他地区,您不应使用dropout。
相反,您应该在卷积之间插入批量标准化。 这将使您的模型正常化,并使您的模型在训练期间更加稳定。
批正则化
批标准化是规范卷积网络的另一种方法。
除了正则化效应之外,批量归一化还可以使您的卷积网络在训练期间抵抗消失的梯度。 这可以减少训练时间并获得更好的性能。
批量标准化可以消除消失的梯度
Keras实施
要在Keras中实现批量标准化,请使用以下命令:
keras.layers.BatchNormalization()
构建具有批量规范化的卷积体系结构时:
在卷积和激活层之间插入批量标准化层。 (资源)
您可以在此功能中调整一些超参数,并使用它们。
您也可以在激活功能之后插入批量标准化,但根据我的经验,这两种方法都具有相似的性能。
例如
model.add(Conv2D(60,3, padding = "same"))model.add(BatchNormalization())model.add(Activation("relu"))
批量标准化取代了dropout。
即使您不需要担心过度拟合,实现批量标准化也有很多好处。 正因为如此,它的正规化效应,批量归一化已经在很大程度上取代了现代卷积体系结构中的dropout。
“我们提出了一种使用批量规范化网络构建,训练和执行推理的算法。 由此产生的网络可以通过饱和非线性进行训练,更能容忍增加的训练率,并且通常不需要Dropout进行正规化。“ - Ioffe and Svegedy 2015
至于为什么dropout在最近的应用中失宠,主要有两个原因。
首先,在对卷积层进行正则化时,dropout通常不太有效。
原因? 由于卷积层具有很少的参数,因此它们开始时需要较少的正则化。 此外,由于在特征图中编码的空间关系,激活可以变得高度相关。 这使得dropout无效。(资源)
其次,擅长正规化的dropout现在已经过时了。
像VGG16这样在网络末端包含完全连接的层的大型模型。 对于这样的模型,过度拟合是通过在完全连接的层之间包括dropout来解决的。
不幸的是,最近的架构远离了这个完全连接块。
通过用全局平均池替换密集层,现代的网络可以减少模型大小,同时提高性能。
我将在未来再写一篇文章,详细说明如何在卷积网络中实现全球平均汇集。 在此之前,我建议阅读ResNet论文,以了解GAP的好处。
一个实验
我创建了一个实验来测试批量标准化是否会减少在卷积之间插入时的泛化错误。 (链接)
我构建了5个相同的卷积体系结构,并在卷积之间插入了dropout,批量规范或任何(控制)。
通过在Cifar100数据集上训练每个模型,我获得了以下结果。
批量标准化模型的良好表现说明应在卷积之间使用批量标准化。
此外,不应在卷基层之间放置dropout,因为dropout的模型往往比控制模型表现更差。
有关更多信息,请查看我的GitHub上的完整文章。
小贴士
如果你想知道是否应该在卷积网络中实现dropout,现在你知道了。 仅在完全连接的层上使用dropout,并在卷积之间实现批量标准化。
如果您想了解有关批量标准化的更多信息,请阅读:
https://towardsdatascience.com/intuit-and-implement-batch-normalization-c05480333c5b

若有收获,就点个赞吧
0 人点赞
