作者: Ajoy Majumdar,Zhen Li
大多数大公司拥有大量具有不同数据格式和大量数据的数据源。这些数据存储由整个企业中的许多人访问和分析。在Netflix,我们的数据仓库包含大量存储在Amazon S3(通过Hive),Druid,Elasticsearch,Redshift,Snowflake和MySql的数据集。我们的平台支持Spark,Presto,Pig和Hive,用于消费,处理和生成数据集。鉴于数据源的多样性,并确保我们的数据平台可以作为一个“单一”数据仓库在这些数据集之间进行互操作,我们构建了Metacat。在本博客中,我们将讨论构建Metacat的动机,Metacat是一种元数据服务,可以使数据易于发现,处理和管理。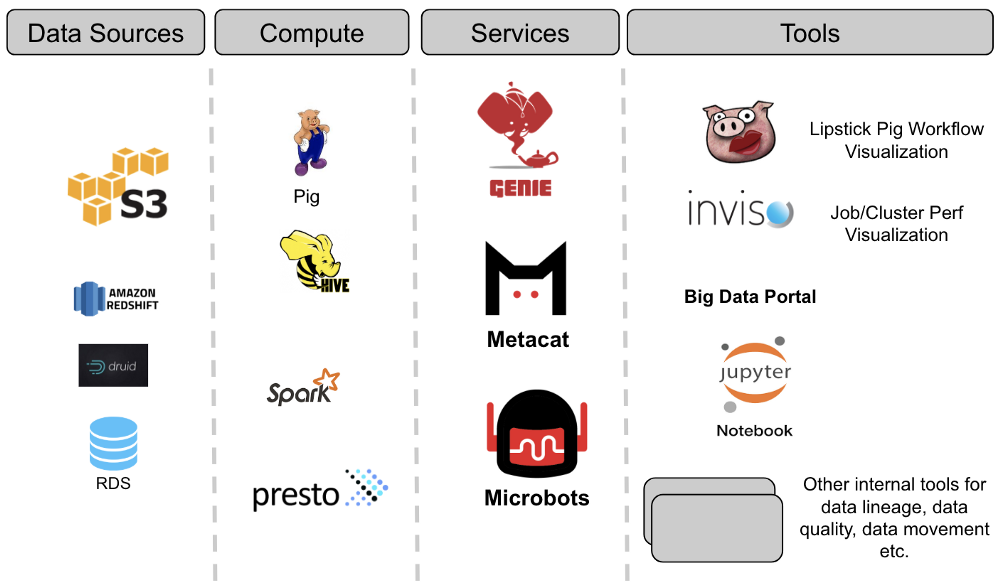
目标
Netflix大数据平台的核心架构涉及三项关键服务。这些是执行服务(Genie),元数据服务和事件服务。这些想法并非Netflix所独有,而是我们认为构建系统所必需的架构的反映,不仅是为了现在,而且是为了我们数据基础架构的未来规模。
许多年前,当我们开始构建平台时,我们采用Pig作为我们的ETL语言,Hive作为我们的临时查询语言。由于Pig本身没有元数据系统,因此构建一个可以在两者之间进行互操作的人似乎是理想的。
因此,Metacat诞生了,这个系统充当我们支持的所有数据存储的联合元数据访问层。我们的各种计算引擎可用于访问不同数据集的集中服务。总的来说,Metacat有三个主要目标:
- 元数据系统的联合视图
- 有关数据集的元数据的统一API
- 数据集的任意业务和用户元数据存储
值得注意的是,拥有大型分布式数据集的其他公司也面临着类似的挑战。Apache Atlas,Twitter的数据抽象层和Linkedin的WhereHows(在Linkedin的数据发现),仅举几例,旨在解决类似的问题,但是在公司各自的架构选择的背景下。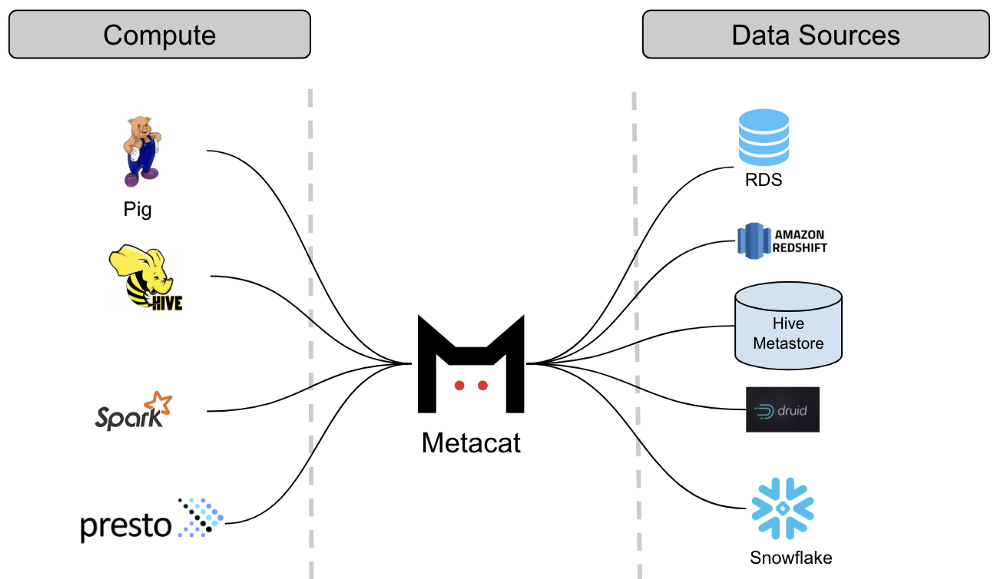
Metacat
Metacat是一种联合服务,提供统一的REST / Thrift接口,用于访问各种数据存储的元数据。相应的元数据存储仍然是模式元数据的真实来源,因此Metacat不会在其存储中实现它。它仅直接存储有关数据集的业务和用户定义的元数据。它还向Elasticsearch发布有关数据集的所有信息,以进行全文搜索和发现。
在更高级别,Metacat功能可分为以下几类:
- 数据抽象和互操作性
- 业务和用户定义的元数据存储
- 数据发现
- 数据更改审核和通知
- Hive Metastore优化
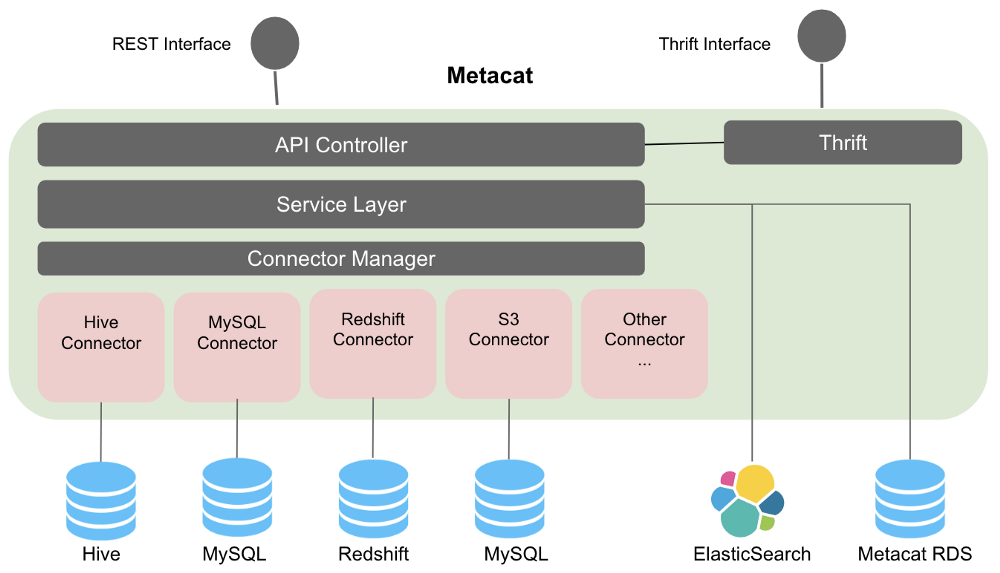
数据抽象和互操作性
Netflix使用Pig,Spark,Presto和Hive等多个查询引擎来处理和使用数据。通过引入共同的抽象层,数据集可以由不同的引擎互换地访问。例如:从Hive读取数据的Pig脚本将能够在Pig类型中读取具有Hive列类型的表。对于从一个数据存储区到另一个数据存储区的数据移动,Metacat通过使用目标表数据类型帮助在目标数据存储中创建新表来简化该过程。Metacat具有受支持的规范数据类型的已定义列表,并且具有从这些类型到每个相应数据存储类型的映射。例如,我们的数据移动工具使用上述功能将数据从Hive移动到Redshift或Snowflake。
Metacat thrift服务支持Hive thrift接口,可轻松与Spark和Presto集成。这使我们能够通过一个系统汇集所有元数据更改,这进一步使我们能够发布有关这些更改的通知,以启用数据驱动的ETL。当新数据到达时,Metacat可以通知相关作业启动。
业务和用户定义的元数据
Metacat在其存储中存储有关数据集的其他业务和用户定义的元数据。我们目前使用业务元数据来存储连接信息(例如,对于RDS数据源),配置信息,度量(Hive / S3分区和表)以及表TTL(生存时间)以及其他用例。顾名思义,用户定义的元数据是一种自由格式元数据,可由用户根据自己的用途进行设置。
业务元数据还可以大致分为逻辑和物理元数据。关于诸如表的逻辑构造的业务元数据被视为逻辑元数据。我们使用元数据进行数据分类并标准化ETL处理。表所有者可以提供有关业务元数据中的表的审计信息。它们还可以提供列默认值和验证规则,以用于写入表中。
关于存储在表或分区中的实际数据的元数据被视为物理元数据。我们的ETL处理存储有关作业完成时数据的指标,稍后将用于验证。可以使用相同的度量来分析数据的成本+空间。鉴于两个表可以指向相同的位置(如在Hive中),因此必须区分逻辑元素和物理元数据,因为两个表可以具有相同的物理元数据但具有不同的逻辑元数据。
数据发现
作为数据的消费者,我们应该能够轻松浏览和发现各种数据集。Metacat向Elasticsearch发布模式元数据和业务/用户定义的元数据,有助于全文搜索数据仓库中的信息。这也可以在我们的大数据门户SQL编辑器中自动建议和自动完成SQL。将数据集组织为目录有助于消费者浏览信息。标签用于根据组织和主题区域对数据进行分类。我们还使用标签来标识数据生命周期管理的表。
数据变更通知和审计
Metacat是数据存储的中央门户,可捕获任何元数据更改和数据更新。我们还围绕表和分区更改构建了推送通知系统。目前,我们正在使用此机制将事件发布到我们自己的数据管道(Keystone)以进行分析,以便更好地了解我们的数据使用情况和趋势。我们还发布到Amazon SNS。我们正在将我们的数据平台架构发展为事件驱动架构。将事件发布到SNS允许我们的数据平台中的其他系统相应地“响应”这些元数据或数据更改。例如,当删除表时,我们的S3仓库管理员服务可以订阅此事件并适当地清理S3上的数据。
Hive Metastore优化
由RDS支持的Hive Metastore在高负载下表现不佳。我们已经注意到使用metatore API编写和读取分区的许多问题。鉴于此,我们不再使用这些API。我们对Hive连接器进行了改进,该连接器直接与支持的RDS进行通信,以便读写分区。之前,Hive Metastore调用添加几千个分区通常会超时,但是通过我们的实现,这不再是一个问题。
下一步
我们在构建Metacat方面取得了很大进展,但我们还远未完成。以下是我们仍需要处理的一些其他功能,以增强我们的数据仓库体验。
- 用于提供表的历史记录的架构和元数据版本控制。例如,跟踪特定列的元数据更改或能够随时查看表大小趋势非常有用。能够询问过去某个元数据的外观对于审计,调试很重要,对于重新处理和回滚用例也很有用。
- 提供有关数据沿袭表的上下文信息。例如,表访问频率等元数据可以在Metacat中聚合并发布到数据沿袭服务,以用于对表的关键性进行排序。
- 添加对Elasticsearch和Kafka等数据存储的支持。
- 可插入元数据验证。由于业务和用户定义的元数据是自由格式,为了保持元数据的完整性,我们需要进行验证。Metacat应具有可插入的体系结构,以包含可在存储元数据之前执行的验证策略。
随着我们不断开发功能以支持我们的用例,我们始终乐于接受社区的反馈和贡献。您可以通过Github与我们联系,或通过我们的Google网上论坛向我们发送消息。我们希望在今年晚些时候分享我们的团队正在进行的工作!
如果您对这样的大数据挑战感兴趣,我们一直在寻找我们团队的重要补充。您可以在此处查看我们所有的开放数据平台角色。

若有收获,就点个赞吧
0 人点赞
