TL; DR(适用于mlflow用户)
在您的工作流程中更改此:
mlflow ui
对此:
neptune mlflow
并进行你的mlflow实验:
- 主持,
- 备份,
- 组织,
- 易于与他人分享和讨论。
分享您的工作可以和我分享此MLflow实验一样简单。
MLflow:伟大的,好的,所以如此
MLFlow是一个非常棒的开源项目,最近获得了很多人的欢迎。简而言之,它可以让你:
- 跟踪您的机器学习项目
- 可以轻松重现结果
- 允许您将模型部署到生产中
如果你还没有听说过MLFlow,你一定要看一下。这篇博文由mlflow的作者撰写,应该会给你一个很好的图片。简而言之,在跟踪机器学习模型的跟踪,再现性和部署方面,mflow有可能成为行业标准。它已经做得很好,并且拥有如此出色的团队,我相信mlflow会留下来。
但是,当你想要添加组织和协作时,事情还不是很好的。您需要托管您的mlflow服务器,确保合适的人员有权访问,备份等等。另外,mlflow提供的实验比较界面边缘有点粗糙,特别是如果你想把它作为一个团队使用的话。
MLflow专注于跟踪,可重复性和部署,而不是组织和协作。就如此容易。
这里是我唱歌和跳舞的地方,并告诉您,您可以从MLflow中获取您喜欢的内容,并在海王星为您提供的美丽托管UI中享受组织和协作。
我们最近创建并开源[neptune-mlflow](https://github.com/neptune-ml/neptune-mlflow),让您将Neptune和MLflow与一个命令集成在一起。
**
neptune mlflow
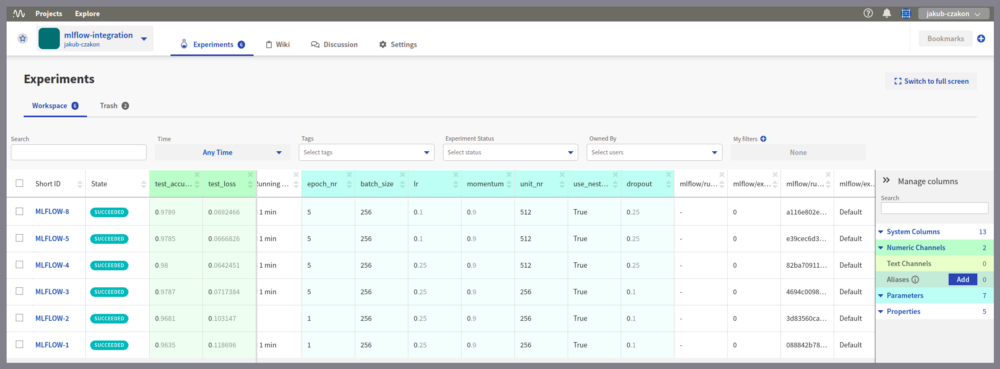
在海王星举办了MLflow实验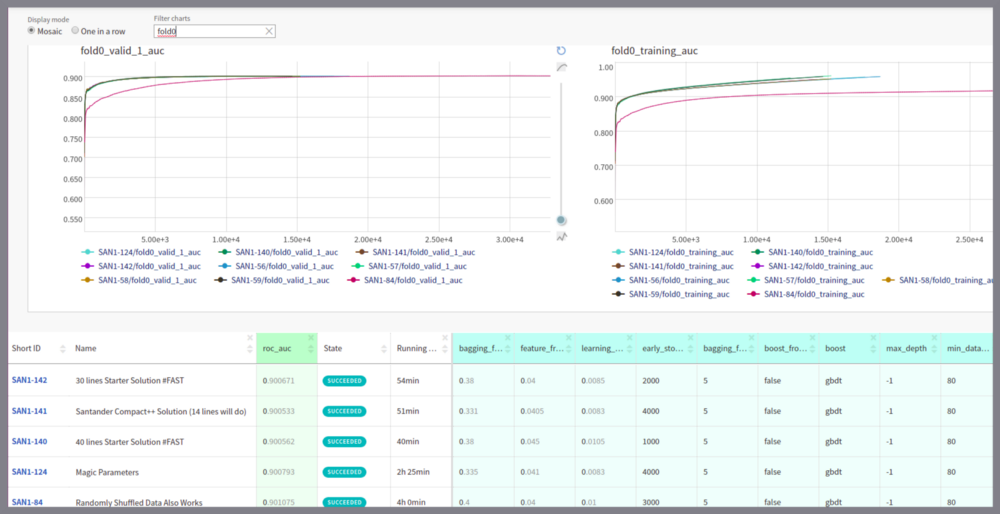
实验运行的比较。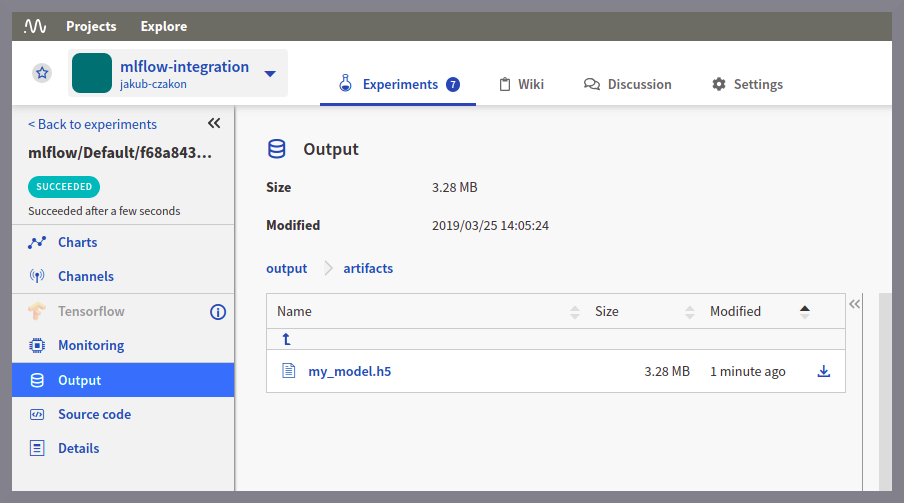
如果你想了解更多关于海王星的信息,请查看 此博文。
你有兴趣吗?
让我们深入了解细节。
跟踪MLflow
建立
我们需要从为我们的实验设置mlflow跟踪开始。举个例子,我将在mnist数据集上训练一些神经网络。
让我们看看这个简单的训练脚本,然后添加mlflow。
import tensorflow as tfPARAMS = {'epoch_nr': 5,'batch_size': 256,'lr': 0.1,'momentum': 0.9,'use_nesterov': True,'unit_nr': 512,'dropout': 0.25}mnist = tf.keras.datasets.mnist(x_train, y_train),(x_test, y_test) = mnist.load_data()x_train, x_test = x_train / 255.0, x_test / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(PARAMS['unit_nr'], activation=tf.nn.relu),tf.keras.layers.Dropout(PARAMS['dropout']),tf.keras.layers.Dense(10, activation=tf.nn.softmax)])optimizer = tf.keras.optimizers.SGD(lr=PARAMS['lr'],momentum=PARAMS['momentum'],nesterov=PARAMS['use_nesterov'],)model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy',metrics=['accuracy'])model.fit(x_train, y_train,epochs=PARAMS['epoch_nr'],batch_size=PARAMS['batch_size'])test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)print('test_loss {}'.format(test_loss))print('test_acc {}'.format(test_acc))model.save('my_model.h5')
好的,我们定义参数,加载数据,创建模型和优化器,训练和评估我们的网络并保存它。很标准。
现在,为了开始使用mlflow进行跟踪,我们需要创建mlflow调用的内容run :
import mlflowwith mlflow.start_run():
在这里,我们现在可以将信息记录到mlflow。
我将从超参数开始:
PARAMS = {'epoch_nr': 5,'batch_size': 256,'lr': 0.1,'momentum': 0.9,'use_nesterov': True,'unit_nr': 512,'dropout': 0.25}for name, value in PARAMS.items():mlflow.log_param(name, value)
训练完成后,我想知道测试集的损失和准确性。让我们记录这些指标:
test_loss,test_acc = model.evaluate(x_test,y_test,verbose = 2)mlflow.log_metric(“ test_loss ”,test_loss)mlflow.log_metric(“ test_accuracy ”,test_acc)
最后,让我们记录模型权重,以确保保存所有重要的实验信息。
model.save(' my_model.h5 ')mlflow.log_artifact(' my_model.h5 ')
因此,MLflow跟踪的完整培训脚本如下所示:
import tensorflow as tfimport mlflowPARAMS = {'epoch_nr': 5,'batch_size': 256,'lr': 0.1,'momentum': 0.9,'use_nesterov': True,'unit_nr': 512,'dropout': 0.25}with mlflow.start_run():for name, value in PARAMS.items():mlflow.log_param(name, value)mnist = tf.keras.datasets.mnist(x_train, y_train),(x_test, y_test) = mnist.load_data()x_train, x_test = x_train / 255.0, x_test / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(PARAMS['unit_nr'], activation=tf.nn.relu),tf.keras.layers.Dropout(PARAMS['dropout']),tf.keras.layers.Dense(10, activation=tf.nn.softmax)])optimizer = tf.keras.optimizers.SGD(lr=PARAMS['lr'],momentum=PARAMS['momentum'],nesterov=PARAMS['use_nesterov'],)model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy',metrics=['accuracy'])model.fit(x_train, y_train,epochs=PARAMS['epoch_nr'],batch_size=PARAMS['batch_size'])test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)mlflow.log_metric("test_loss", test_loss)mlflow.log_metric("test_accuracy", test_acc)model.save('my_model.h5')mlflow.log_artifact('my_model.h5')
您可以快速体验新想法,并获得MLflow保存的超参数,指标和模型权重等元数据。这样,您就可以控制实验过程。感觉很好,不是吗?
用不同的参数进行一些实验并尝试改进可能是个好主意test_accuracy模型。
探索实验
现在,我们已经生成了一些实验元数据,我们可以开始探索它。MLflow带有一个实验比较界面,您可以通过运行来启动:mlflow ui
得到这样的东西: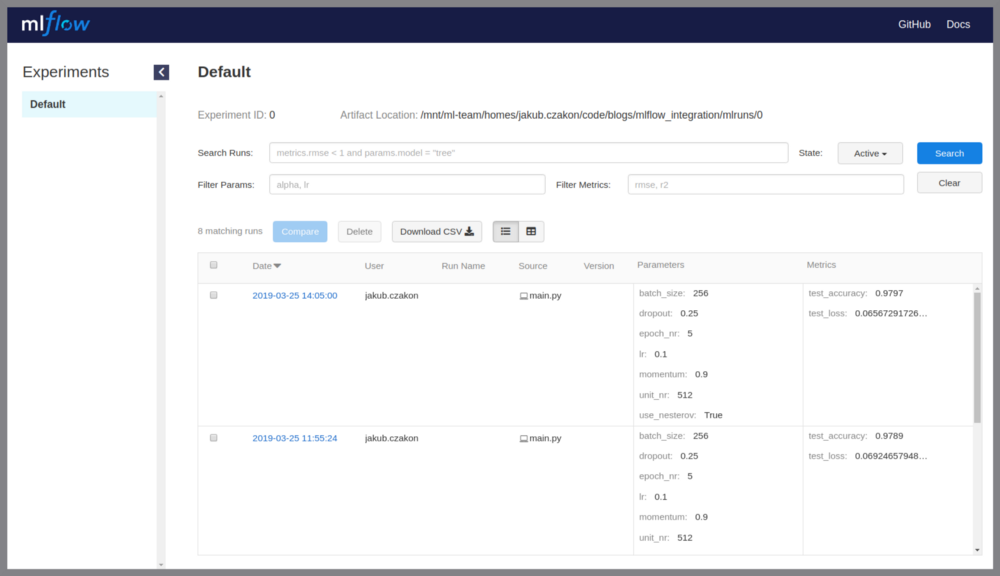
您可以搜索实验,查看超参数,按指标对其进行排序,并为实验运行添加注释。但是,在我看来,有很多事情可以改进。列举一些:
- 无法根据您的需要调整实验仪表板,
- 比较不同指标的学习曲线并不是很好。一个人需要一个接一个地做,
- 比较不同跑步的学习曲线(TensorBoard风格)还没有,
- 缺少项目级知识共享空间(注释,全局变更日志)。
这些正是海王星确实做得很好的一些事情以及为什么我们认为将海王星与MLflow整合在一起会给社区带来如此多的影响。
海王星的组织与合作
设置海王星(如果你已经拥有它,请跳过)
- 寄存器。转到neptune.ml并注册。非组织完全免费,您可以邀请其他人加入您的团队!
- 获取您的海王星API令牌。为此,请单击
Get API Token左上角的按钮。
3.设置 NEPTUNE_API_TOKEN环境变量。转到您的控制台并运行:
导出NEPTUNE_API_TOKEN =’your_long_api_token’
4.创建您的第一个项目。点击Projects和New project。为其选择一个名称,以及是将其公开还是私有。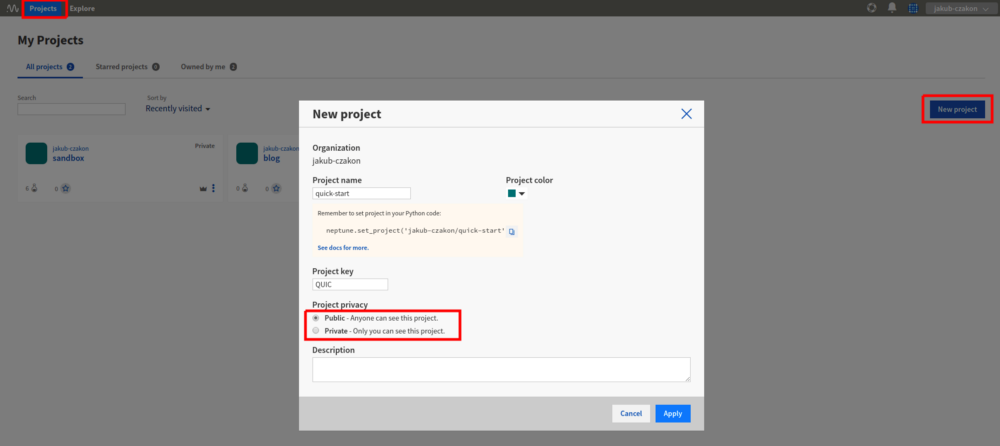
安装 neptune-mlflow
pip安装neptune-mlflow
将MLflow与海王星同步。
转到项目目录并运行:
neptune mlflow - 项目USER_NAME / PROJECT_NAME
您可以简化命令,并删除--project参数。USER_NAME/PROJECT_NAME通过运行以下命令设置NEPTUNE_PROJECT变量:
导出NEPTUNE_PROJECT = USER_NAME / PROJECT_NAME
并且您可以mlruns通过执行以下命令将目录与Neptune 同步:
海王星mlflow
容易腻好吧?
组织实验
现在,您的实验元数据可以在Neptune中安全地存储和备份。您可以根据需要自定义仪表板。您可以使用自定义过滤器添加标签和分组实验。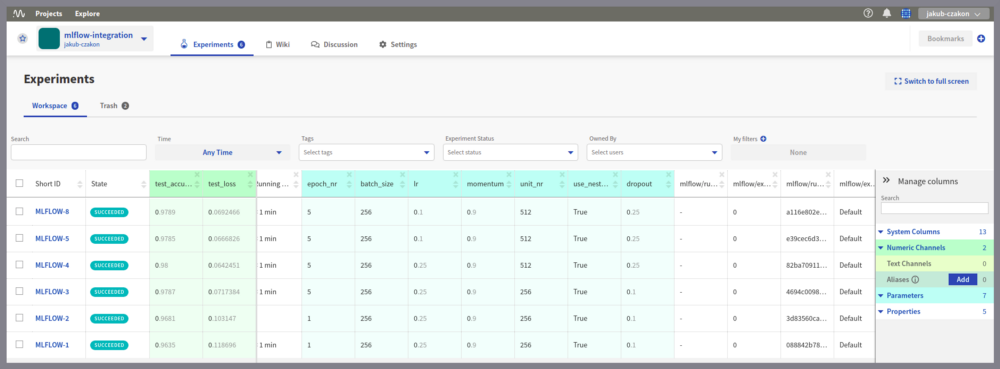
您可以添加项目Wiki并与他人共享知识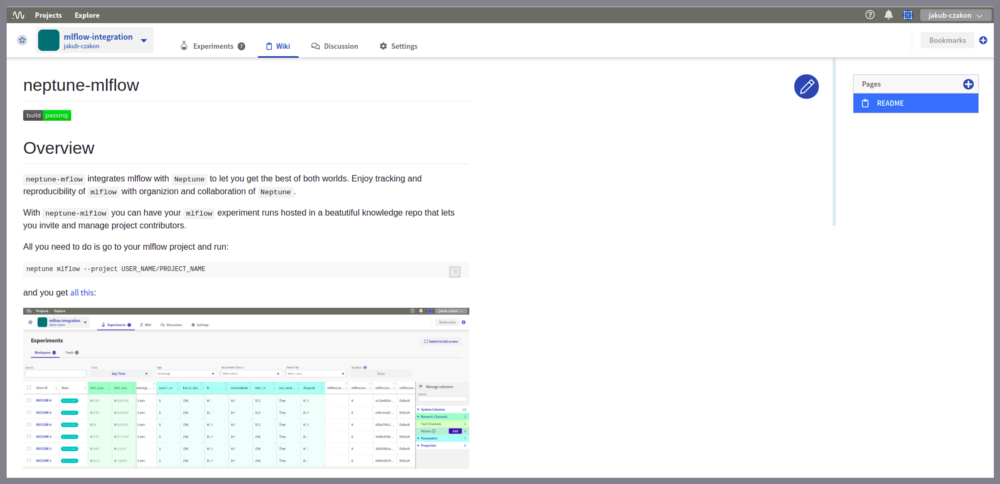
您甚至可以通过一次点击比较实验运行 TensorBoard风格。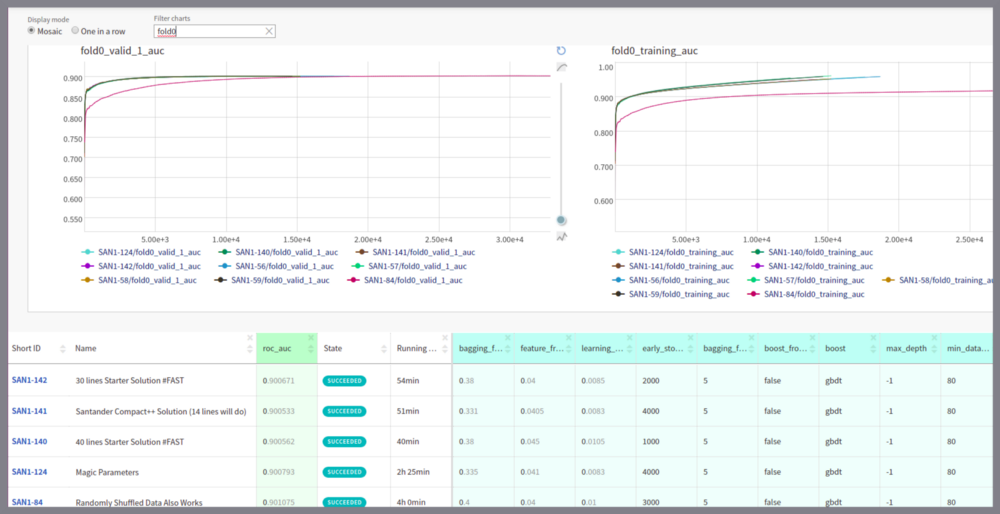
合作实验
将您的实验存储在海王星中的一个巨大优势是您可以与他人分享您的工作。只需将链接发送到实验图表,选定的实验组或模型诊断图,即可快速有效地解释您的问题或问题。
简单来说,我可以使用MLflow跟踪我的实验运行,并通过向您发送实验链接与您分享。多么酷啊?
只需点击上面的一个链接,看看知识共享是多么容易。
此外,任何有权访问该项目的人都可以从UI下载它的每个部分。与同事共享最佳模型就像点击下载按钮一样简单。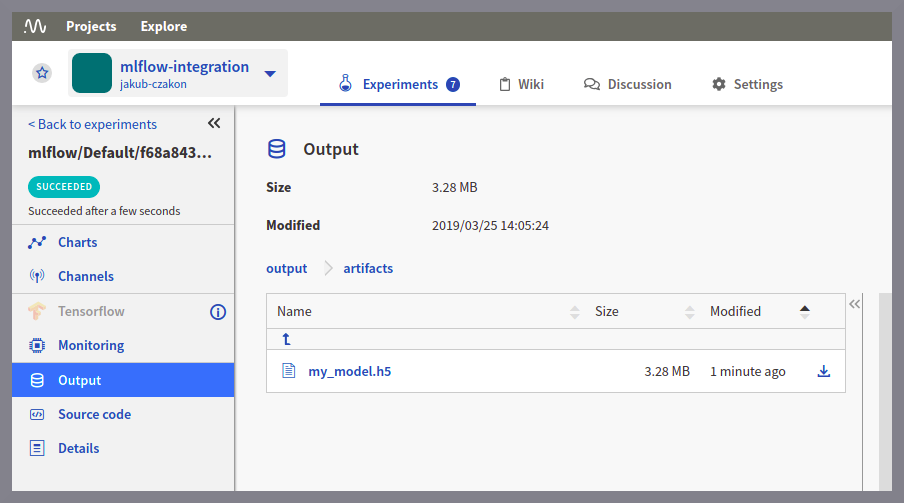
“哦,但是谁可以访问我的项目?” - 你
你决定。保持您的工作公开或将其公之于众。只需邀请其他人并为项目的每个成员选择一个角色(admin / contributor / viewer)。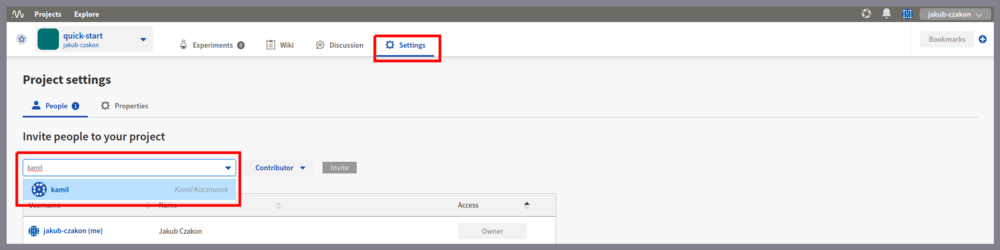
最后的想法
如果您希望拥有一个用于跟踪,再现性和部署的通用框架,那么Neptune + MLflow是一个有趣的组合,但与此同时,您关心知识组织和协作。
如果你想看看Neptune + MLflow duo如何为你的项目工作,请转到neptune.ml并注册。
感谢您坚持到最后。让我与你分享这句话作为回报。
“我们可以做的很少,我们可以一起做这么多。” - 海伦凯勒

若有收获,就点个赞吧
0 人点赞
