本教程中,我将通过解释他们的W3H(时间,原因,内容和方式)快速浏览四个着名的CNN架构的细节以及它们之间的区别。
AlexNet
When?
- 阿兰图灵年
- 人人享有可持续能源的一年
- 伦敦奥运会
Why?
AlexNet的诞生是为了改善ImageNet挑战的结果。这是第一个在2012年ImageNet LSVRC-2012挑战中获得相当准确度的深度卷积网络之一,精度为84.7%,而第二个精度为73.8%。使用卷积层和感受域来探索图像帧中的空间相关性的想法。
What?
该网络包括5个卷积(CONV)层和3个完全连接(FC)层。使用的激活是整流线性单元(ReLU)。网络中每层的结构细节可以在下表中找到。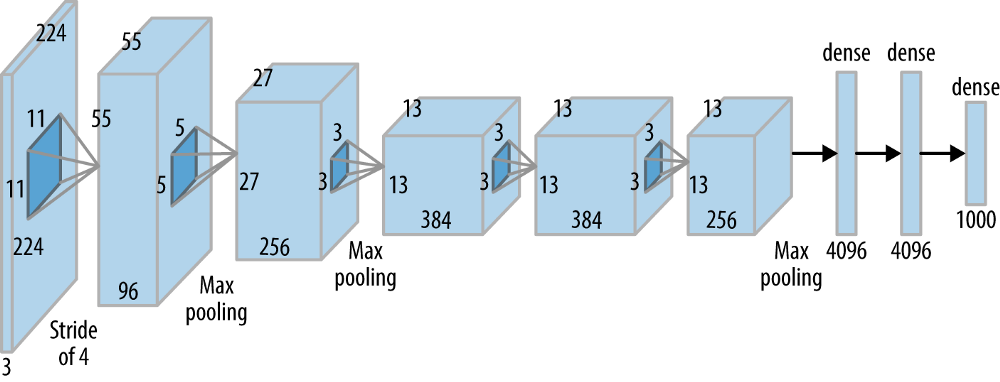
Alexnet Block Diagram(来源:oreilly.com)
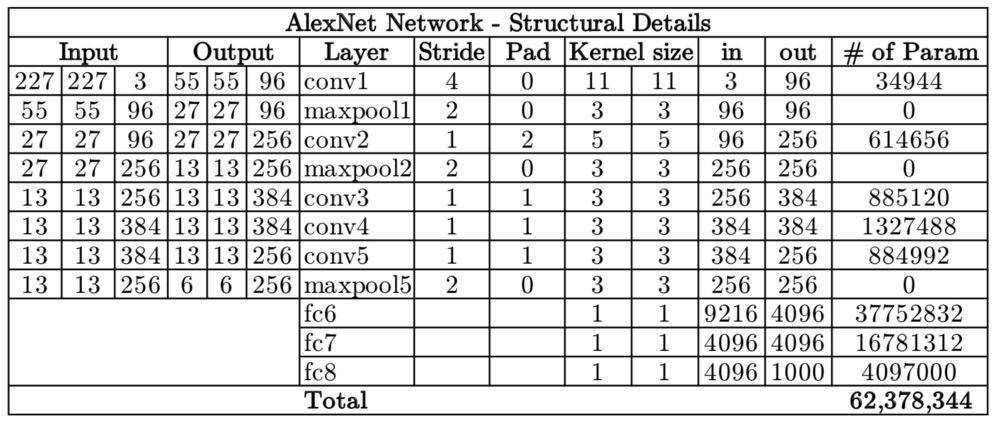
该网络共有6200万个可训练变量
How?
- 网络的输入是一批大小为227x227x3的RGB图像,并输出对应于每个类的1000x1概率向量。
- 执行数据增加以减少过度拟合。此数据增强包括镜像和裁剪图像以增加训练数据集的变化。网络在第一,第二和第五CONV层之后使用重叠的最大化层。重叠的maxpool图层就是大小小于窗口大小的maxpool图层。使用3x3 maxpool图层,步长为2,从而创建重叠的感知字段。这种重叠分别将top-1和top-5误差分别提高了0.4%和0.3%。
- 在AlexNet之前,最常用的激活函数是sigmoid和tanh。由于这些功能的饱和性,它们遭受消失梯度(VG)问题并且使得网络难以训练。AlexNet使用ReLU激活功能,不会受到VG问题的影响。原始论文表明,具有ReLU的网络实现了25%的错误率,比具有tanh非线性的同一网络快6倍。
- 虽然ReLU有助于解决消失的梯度问题,但由于其无限的性质,学习的变量可能变得不必要地高。为了防止这种情况,AlexNet引入了本地响应规范化(LRN)。LRN背后的想法是在像素附近进行归一化,放大激发的神经元,同时抑制周围的神经元。
AlexNet还通过使用丢弃层来解决过度拟合问题,其中在训练期间以概率p = 0.5丢弃连接。虽然这可以避免网络过度拟合,帮助它摆脱糟糕的局部最小值,但收敛所需的迭代次数也增加了一倍。
VGGNet
When?
国际家庭农业和晶体学年
- 彗星首次机器人着陆
- 罗宾威廉姆斯去世的那一年
Why?
VGGNet的诞生是因为需要减少CONV层中的参数数量并改善培训时间。
What?
VGGNet有多种变体(VGG16,VGG19等),它们的区别仅在于网络中的总层数。VGG16网络的结构细节如下所示。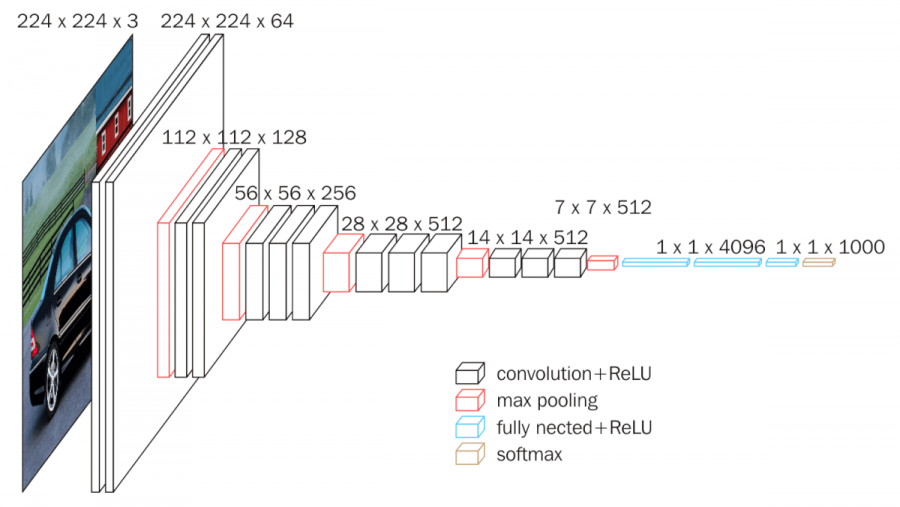
VGG16框图(来源:neurohive.io)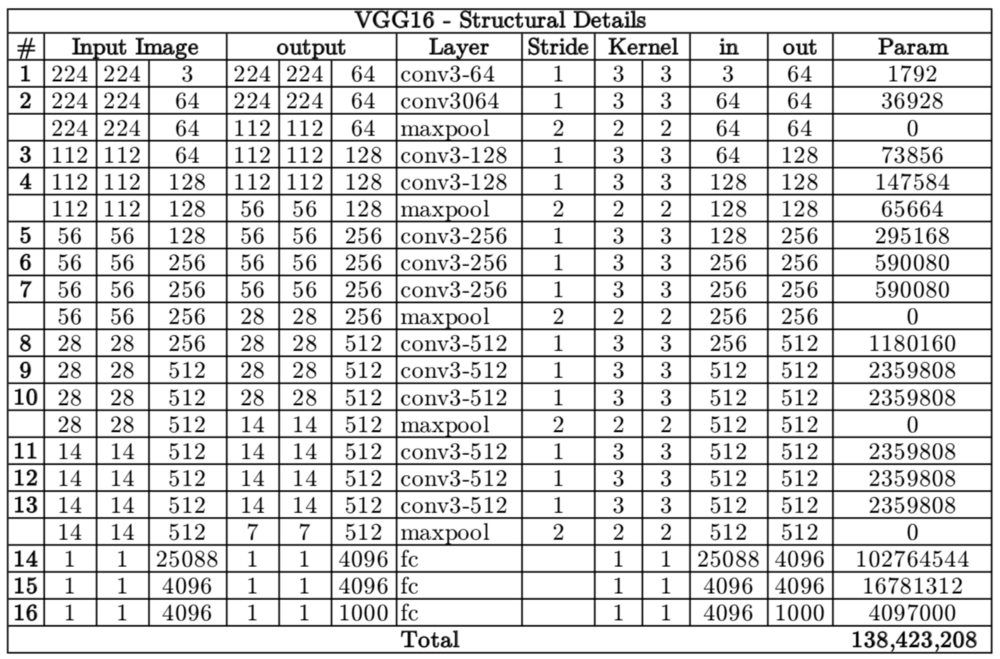 VGG16共有1.38亿个参数。这里要注意的重点是所有conv内核的大小为3x3,maxpool内核的大小为2x2,步长为2。
VGG16共有1.38亿个参数。这里要注意的重点是所有conv内核的大小为3x3,maxpool内核的大小为2x2,步长为2。
How?
具有固定大小内核的想法是,可以通过使用多个3x3内核作为构建块来复制Alexnet(11x11,5x5,3x3)中使用的所有可变大小卷积内核。复制是根据内核所涵盖的感知字段进行的。
让我们考虑以下示例。假设我们有一个大小为5x5x1的输入层。实现内核大小为5x5且步长为1的转换层将产生并输出1x1的特征映射。通过实现两个3x3转换层(步长为1)可以获得相同的输出特征映射,如下所示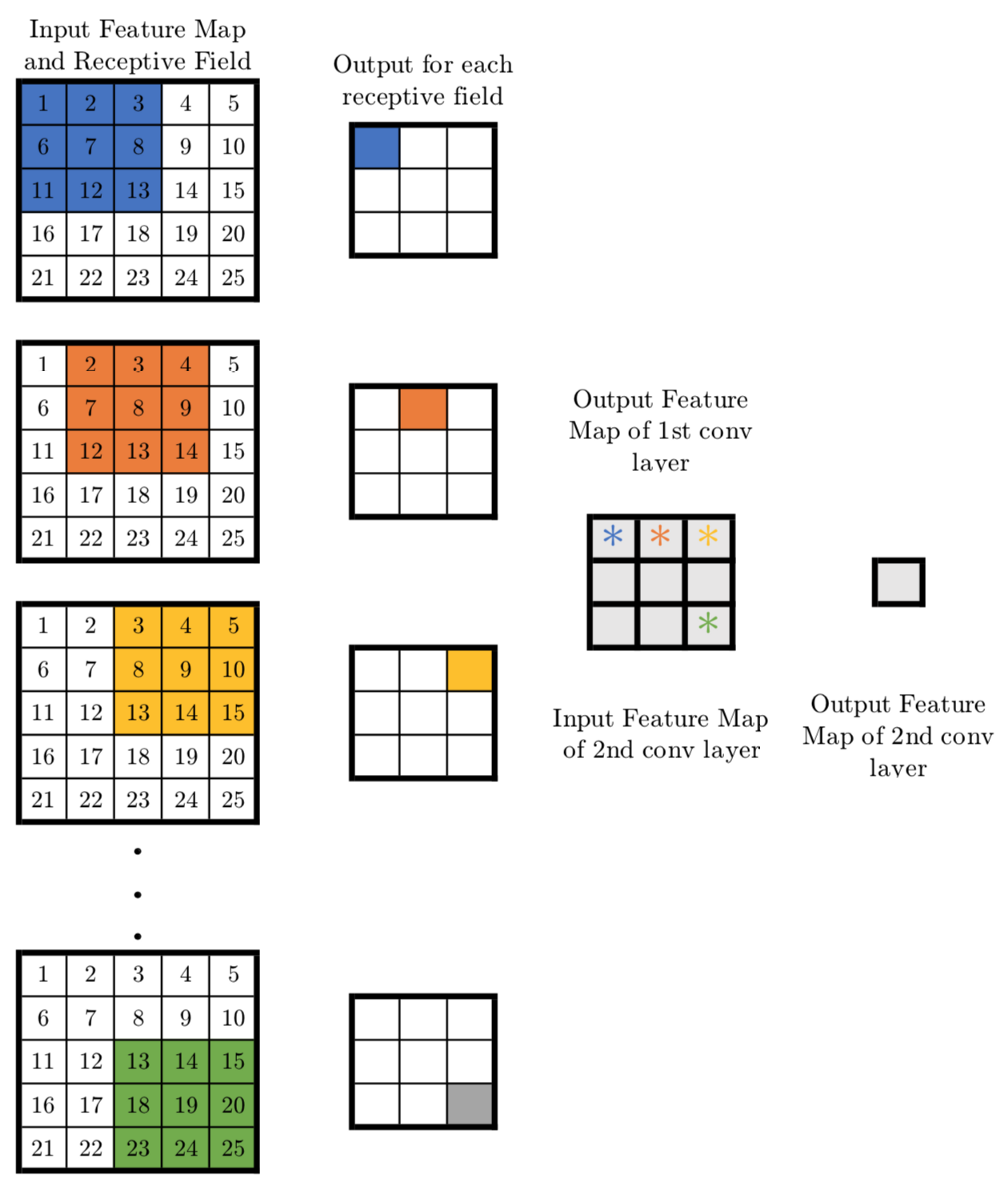
现在让我们看一下需要训练的变量数量。对于5x5转换层滤波器,变量的数量为25.另一方面,两个内核大小为3x3的转换层总共具有3x3x2 = 18个变量(减少28%)。
类似地,通过实现三(5)个3x3转换层(步长为1),可以实现一个7x7(11x11)转换层的效果。这使可训练变量的数量减少了44.9%(62.8%)。减少可训练变量的数量意味着更快的学习和更强大的过度拟合。
RESNET
When?
- 发现引力波
- 国际土壤和光照技术年
- 火星电影
Why?
- 神经网络因存在时无法找到更简单的映射而臭名昭着。
- 例如,假设我们有一个完全连接的多层感知器网络,我们希望在输入等于输出的数据集上训练它。解决这个问题的最简单方法是让所有权重等于所有隐藏层的一个和所有偏差零。但是当使用反向传播训练这样的网络时,学习相当复杂的映射,其中权重和偏差具有宽范围的值。
- 另一个例子是向现有神经网络添加更多层。假设我们有一个网络f(x),它在数据集上的准确度达到了n%。现在向该网络添加更多层g(f(x)应该至少具有n%的精度,即在最坏的情况下g(。)应该是相同的映射,产生与f(x)相同的精度,如果不是更多。但不幸的是情况并非如此。实验表明,通过向网络添加更多层,精度实际上降低了。
- 由于消失的梯度问题,上述问题发生了。当我们使CNN更深时,向后传播到初始层的导数变得几乎无关紧要。
ResNet通过引入两种类型的“快捷方式连接”来解决此网络:身份快捷方式和投影快捷方式。
what?
ResNetXX架构有多个版本,其中“XX”表示层数。最常用的是ResNet50和ResNet101。由于消失的梯度问题得到了关注(更多关于它如何部分),CNN开始变得越来越深。下面我们介绍ResNet18的结构细节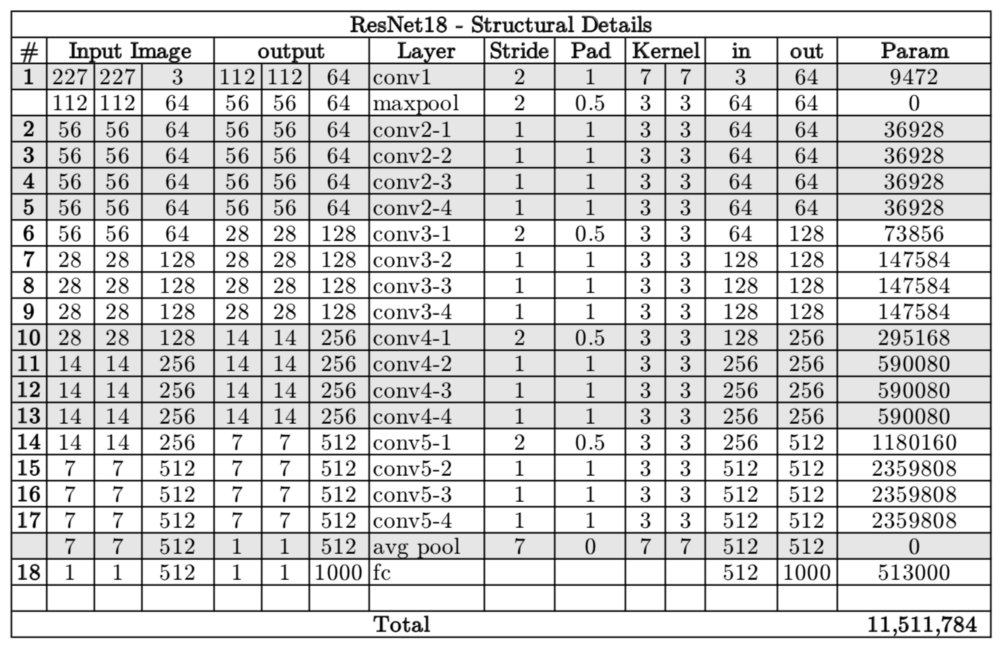
Resnet18拥有大约1,100万个可训练参数。它由CONV层组成,滤波器大小为3x3(就像VGGNet一样)。在整个网络中仅使用两个池化层,一个在网络的开始处,另一个在网络的末端。身份连接位于每两个CONV层之间。实线箭头显示了输入和输出的尺寸相同的标识快捷方式,而虚线箭头显示了尺寸不同的投影连接。
How?
如前所述,ResNet架构利用快捷连接确实解决了消失的梯度问题。ResNet的基本构建块是一个残留块,它在网络中重复出现。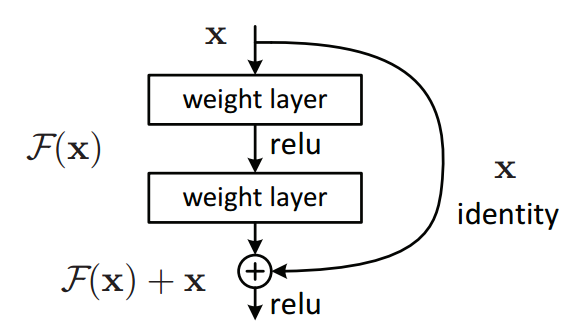
网络不是从x→F(x)学习映射,而是从x→F(x)+ G(x)学习映射。当输入x和输出F(x)的维数相同时,函数G(x)= x是一个标识函数,快捷方式连接称为标识连接。通过在训练期间将中间层中的权重归零来学习相同的映射,因为它更容易将权重归零而不是将它们推到一个。
对于F(x)的尺寸与x不同的情况(由于其间的CONV层中的步幅长度> 1),实现了投影连接而不是Identity连接。函数G(x)将输入x的尺寸改变为输出F(x)的尺寸。原始论文考虑了两种映射。
- 不可训练的映射(填充):输入x简单地用零填充以使维度与F(x)的维度匹配
可训练的映射(Conv层):1x1 Conv层用于将x映射到G(x)。从上表可以看出,在整个网络中,空间尺寸保持相同或减半,深度保持相同或加倍,每个转换层后的宽度和深度的乘积保持相同,即3584.1x1通过分别使用步长2和多个这样的滤波器,将conv层用于空间维度的一半并使深度加倍。1x1转换层的数量等于F(x)的深度。
Inception
when?
国际家庭农业和晶体学年
- 彗星首次机器人着陆
- 罗宾威廉姆斯去世的那一年
Why?
在图像分类任务中,显着特征的大小可以在图像帧内显着变化。因此,决定固定的内核大小是相当困难的。Lager内核对于分布在图像的大面积上的更多全局特征是优选的,另一方面,较小的内核在检测分布在图像帧上的区域特定特征时提供良好的结果。为了有效识别这种可变大小的特征,我们需要不同大小的内核。这就是Inception的作用。它不仅仅是在层数方面更深入,而是更广泛。在同一层内实现不同大小的多个内核。
what?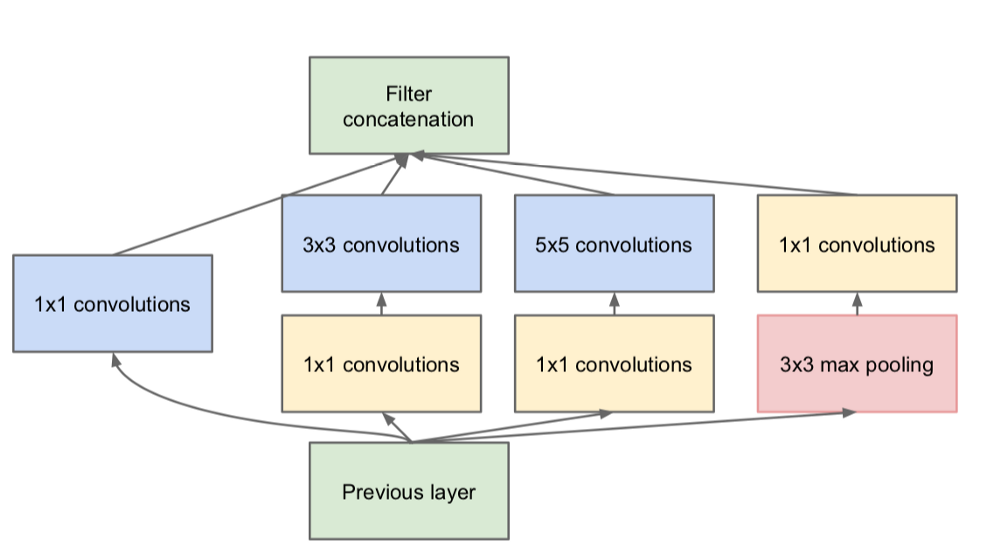
Inception网络体系结构由以下结构的多个初始模块组成
每个初始模块由四个并行操作组成
- 1x1转换层
- 3x3转换层
- 5x5转换层
- 最大池
以黄色显示的1x1转换块用于深度缩减。然后将来自四个并行操作的结果深度连接以形成过滤器连接块(绿色)。有多个版本的Inception,最简单的是GoogLeNet。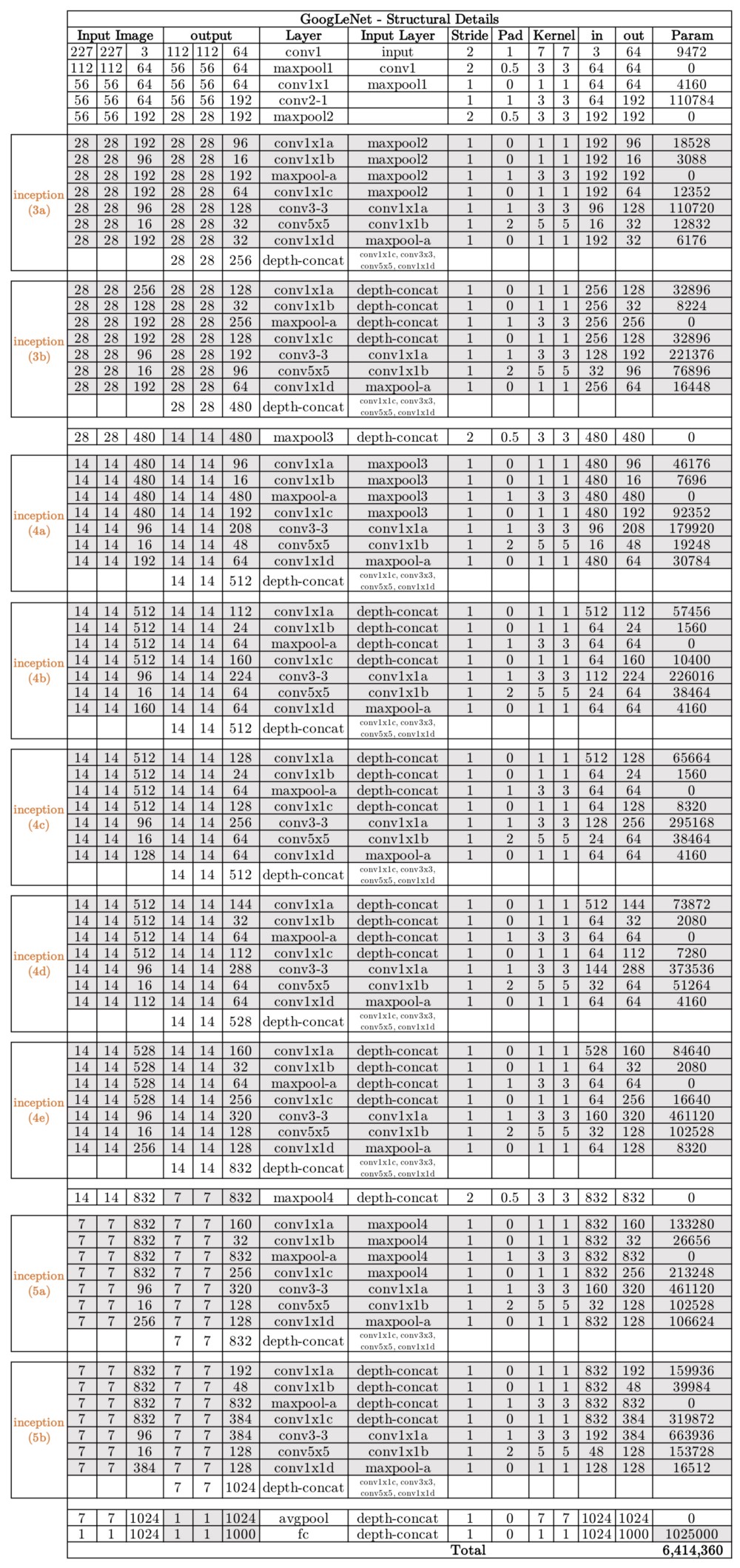
How?
初始化增加了通过培训选择最佳网络的网络空间。每个初始模块都能够捕获不同级别的显着特征。全局特征由5x5转换层捕获,而3x3转换层易于捕获分布式特征。最大池操作负责捕获邻域中突出的低级特征。在给定级别,所有这些特征在被馈送到下一层之前被提取和连接。我们留下网络/培训来决定哪些功能相应地保留了最多的值和重量。假设数据集中的图像具有丰富的全局特征而没有太低级别的特征,那么与5x5 conv内核相比,经过训练的Inception网络将具有与3x3 conv内核相对应的非常小的权重。
摘要
在下表中,这4个CNN按照Imagenet数据集的前5个精度进行排序。还可以看到正向通过所需的可训练参数的数量和浮点运算(FLOP)。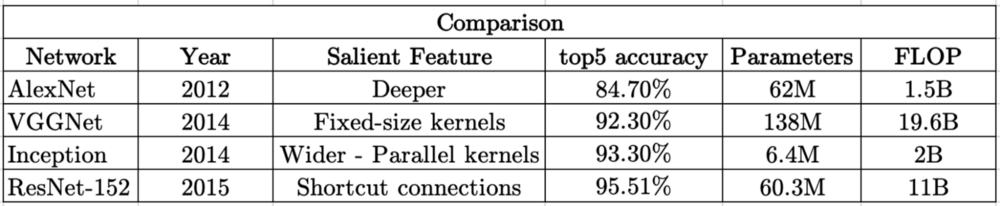
可以进行一些比较:
- AlexNet和ResNet-152都有大约60M的参数,但它们的前5个精度差异大约为10%。但是训练ResNet-152需要大量的计算(大约是AlexNet的10倍),这意味着需要更多的训练时间和精力。
- 与ResNet-152相比,VGGNet不仅具有更多的参数和FLOP,而且精度也有所降低。训练VGGNet的准确性降低需要更多时间。
- 训练AlexNet大致与训练开始时间相同。内存要求低10倍,精度提高(约9%)

若有收获,就点个赞吧
0 人点赞
