让我们通过将现有的图像分类器(Inception V3)调整为自定义任务来体验转移学习的强大功能:对产品图像进行分类,以帮助食品和杂货零售商减少仓库和零售店库存管理过程中的人力。
这项工作的源代码可以在我下面的GitHub存储库中找到。
https://github.com/wisdal/Image-classification-transfer-learning
使用的工具:TensorFlow v1.1,Python 3.4,Jupyter。
深度神经网络的应用实际上是在滚动。无论是医疗保健,运输还是零售,各行各业的公司都对投资构建智能解决方案感到兴奋。同时,让我们希望人类的智慧仍然无可争议:)
趋势AI文章:
1.神经网络如何工作> 2. ResNets,HighwayNets和DenseNets,哦,我的!> 3.机器学习傻瓜 在实际情况下,强大的图像分类器等解决方案可以帮助公司跟踪货架库存,对产品进行分类,记录产品量,从专用设备(无人机?机器人?)实时捕获的原始产品图像。当然,能够识别产品并从给定的图片预测其类别是交易的一部分,这就是这个实验的全部内容:我们将培训机器人从图像中分类食品和杂货产品。

“这是一项轻松的任务!”,我们认为是人类,但计算机程序并不一定如此。无论如何,这个假设甚至都不适用于所有类别的人类; 一个5岁的孩子是一个完美的反例!当我们放大时,一切都是为了在您的生活中看到足够的产品图像,您可以从给定的图像轻松识别您之前看过的任何产品。
当我们使用现有标记数据训练模型时,我们尝试将这种经验概念转移到模型,以便学习如何准确地区分训练数据集中存在的不同类别的数据。从这个意义上说,我们使用人工神经网络,它只不过是模仿人类大脑的实际运作方式。使用这些算法构建模型的知识稍后将在未标记的观察上进行测试。在我们的示例中,模型将基于其先前学习的内容标记输入图像,因此通常分配给该任务的名称监督学习 。
谈到性能,已经注意到,在大多数监督学习的情况下,训练有素的模型往往比人类提供更好的准确性。在这个实际任务中,您会惊讶地发现即使在困难的条件下(模糊的图像,质量差的图像等),我们的算法也非常优于人类。
我们有一个来自hackerearth的产品图像数据集可以在这里下载。我们应该如何进行,为什么我们使用转学习?
为何转学?
当我们考虑对图像进行分类时,我们常常选择从头开始构建我们的模型以获得最佳匹配。这是一个选项,但构建自定义深度学习模型需要大量的计算资源和大量的培训数据。此外,已经存在的模型在分类来自各种类别的图像时表现得相当好。您可能听说过ImageNet及其大视觉识别挑战。在这个计算机视觉挑战中,模型试图将大量图像分类为1000个类,如“斑马”,“达尔马提亚”和“洗碗机”。Inception V3是Google Brain Team为此而建立的模型。毋庸置疑,该模型表现非常出色。
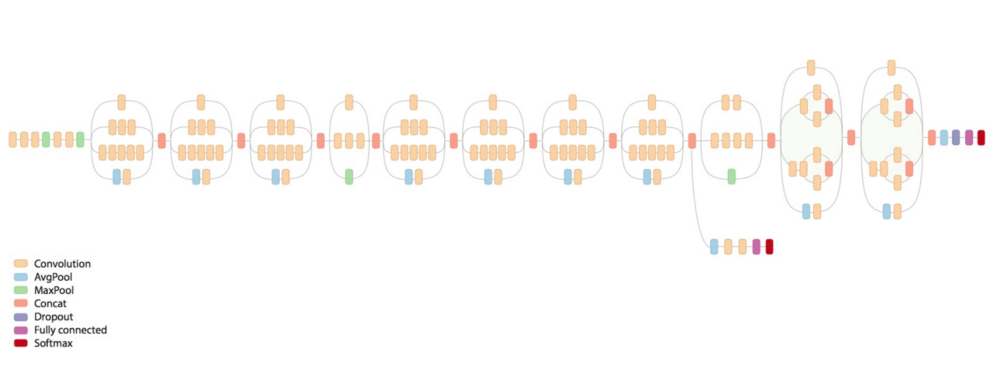
那么,我们可以利用这个模型的存在来进行像现在这样的自定义图像分类任务吗?嗯,这个概念有一个名字:转移学习。它可能不如从头开始的完整培训那么高效,但对于许多应用来说都是惊人的有效。通过修改现有的丰富深度学习模型,它可以显着减少训练数据和时间。
为什么会这样
在神经网络中,神经元被分层组织。不同的层可以对其输入执行不同类型的转换。信号可能在多次遍历各层之后从第一层(输入)传播到最后一层(输出)。作为最后一个隐藏层,“瓶颈”具有足够的汇总信息,以提供执行实际分类任务的下一层。
在retrain.py脚本中,我们删除旧的顶层,并在我们下载的图片上训练一个新的顶层。
我们的最后一层再训练可以用于新类的原因是,结果表明,区分ImageNet中所有1000个类所需的信息通常也可用于区分新类型的对象。
我们现在弄脏手!
第1步:预处理图像
label_counts = train.label.value_counts()plt.figure(figsize =(12,6))sns.barplot(label_counts.index,label_counts.values,alpha = 0.9)plt.xticks(rotation ='vertical')plt.xlabel ('Image Labels',fontsize = 12)plt.ylabel('Counts',fontsize = 12)plt.show()
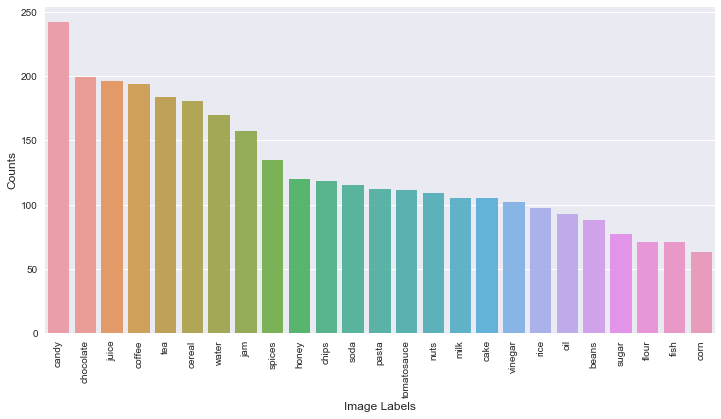
假设您已经下载了数据集,您会发现它附带了一个我们需要正确设置的“train”文件夹。我们的目标是将每个图像放在代表其类别的子文件夹中。最后,我们应该有x个子文件夹,x是不同类别的数量。
为了这个预处理目的,我为您提供了pre_process.ipynb笔记本。
for img in tqdm(train.values):filename=img[0]label=img[1]src=os.path.join(data_root,'train_img',filename+'.png')label_dir=os.path.join(data_root,'train',label)dest=os.path.join(label_dir,filename+'.jpg')im=Image.open(src)rgb_im=im.convert('RGB')if not os.path.exists(label_dir):os.makedirs(label_dir)rgb_im.save(dest)if not os.path.exists(os.path.join(data_root,'train2',label)):os.makedirs(os.path.join(data_root,'train2',label))rgb_im.save(os.path.join(data_root,'train2',label,filename+'.jpg'))
笔记本不仅仅是配置图像子文件夹,所以一定要检查它。
因为我们的数据集带有25个独特的标签,而我们只有3215个训练图像,我们需要增加数据以防止我们的模型过度拟合。
datagen = ImageDataGenerator(rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')class_size=600src_train_dir=os.path.join(data_root,'train')dest_train_dir=os.path.join(data_root,'train2')it=0for count in label_counts.values:#nb of generations per image for this class label in order to make it size ~= class_sizeratio=math.floor(class_size/count)-1print(count,count*(ratio+1))dest_lab_dir=os.path.join(dest_train_dir,label_counts.index[it])src_lab_dir=os.path.join(src_train_dir,label_counts.index[it])if not os.path.exists(dest_lab_dir):os.makedirs(dest_lab_dir)for file in os.listdir(src_lab_dir):img=load_img(os.path.join(src_lab_dir,file))#img.save(os.path.join(dest_lab_dir,file))x=img_to_array(img)x=x.reshape((1,) + x.shape)i=0for batch in datagen.flow(x, batch_size=1,save_to_dir=dest_lab_dir, save_format='jpg'):i+=1if i > ratio:breakit=it+1
第2步:重新训练瓶颈并微调模型
由谷歌提供,我们立即开始使用retrain.py脚本。该脚本默认下载Inception V3 预训练模型。
重新训练脚本是我们算法的核心组件,也是使用从初始v3开始的转移学习的任何自定义图像分类任务的核心组件。它是由TensorFlow作者自己设计的,用于此特定目的(自定义图像分类)。
脚本的作用:
它训练一个新的顶层(瓶颈),可以识别特定类别的图像。顶层接收每个图像的2048维向量作为输入。然后在该表示之上训练softmax层。假设softmax层包含N个标签,这对应于学习与学习的偏差和权重相对应的N + 2048 N(或1001 N)个模型参数。
该脚本完全可以自定义,这里是可配置的参数列表:
- image_dir:标记图像文件夹的路径。幸运的是,我们在预处理步骤中正确设置了它。
- output_graph,intermediate_output_graphs_dir,output_labels等:保存输出文件的位置。
- 失真功能:我的最爱。仅此功能就值得整整一段。您可能已经注意到我们的训练集中的图像是完美的(清晰,高质量,明确)但不幸的是,在生产中并非总是如此。该算法可能会在部署后遇到,模糊图像,昏暗的图像等。

我们的算法应该足够智能,以捕捉这些图像代表相同的事情,并不是那么明显(这只是一个小例子)
- […]这就是失真特征的全部内容。我们有意地在训练过程中随机变换图像(大小,颜色,方向等)以使机器人习惯于不良图像,以避免在这种情况下失去预测准确性。
- how_many_training_steps:时代数。
- 学习率。
- …
您可以随意使用这些参数。学习率,nb。时期等是确定性参数。使用它们来微调您的模型并记住您可以随时使用TensorBoard来可视化您的训练结果。
您可以从一开始就获得约85%的准确度(零微调)。
第3步:在看不见的记录上测试模型
这一步没什么可疯狂的。只是一个小脚本来测试在上一步中构建和保存的模型,在我们数据集的“test”文件夹中的图像上。
查看测试笔记本,了解需要完成的工作。
def run_graph(src, labels, input_layer_name, output_layer_name,num_top_predictions):with tf.Session() as sess:i=0#outfile=open('submit.txt','w')#outfile.write('image_id, label \n')for f in os.listdir(dest):image_data=load_image(os.path.join(dest,test[i]+'.jpg'))#image_data=load_image(os.path.join(src,f))softmax_tensor = sess.graph.get_tensor_by_name(output_layer_name)predictions, = sess.run(softmax_tensor, {input_layer_name: image_data})# Sort to show labels in order of confidencetop_k = predictions.argsort()[-num_top_predictions:][::-1]for node_id in top_k:human_string = labels[node_id]score = predictions[node_id]#print('%s (score = %.5f) %s , %s' % (test[i], human_string))print('%s, %s' % (test[i], human_string))#outfile.write(test[i]+', '+human_string+'\n')i+=1return 0

结论
而已!希望这篇文章对你有用。随意评论并提出改进建议。
我鼓励你试一试,并在评论中告诉我你能达到多少准确度。我很乐意收到你的来信。
正如我之前所说,你肯定能够获得超过85%的基准精度。剩下的就是微调!在我的情况下,我的最终模型在测试装置上的准确性让我感到震惊,考虑到需要的工作量很少。很好地理解事情的工作方式有时候会有所帮助:)。我认为该项目是任何想要尝试图像失真或超参数调整的人的良好基础。这就是为我增加了更多的百分点。
请随意查看我在GitHub上的代码。
资源:tensorflow.org/tutorials/image_recognition

若有收获,就点个赞吧
0 人点赞
