
CatBoost基于梯度增强。Yandex开发的一种新的机器学习技术,优于许多现有的增强算法,如XGBoost,Light GBM。
虽然深度学习算法需要大量数据和计算能力,但仍需要增强算法来解决大多数业务问题。然而,像XGBoost这样的提升算法需要花费数小时来训练,有时候在调整超参数时你会感到沮丧。
另一方面,CatBoost易于实施且功能强大。它在首次运行时提供了出色的结果。那么,让我们来看看CatBoost的特别之处。
基树结构:
- CatBoost和其他增强算法的一个主要区别是CatBoost实现了对称树 。这可能听起来很疯狂但有助于缩短预测时间,这对于低延迟环境非常重要。

-
其他梯度增强算法的程序(XG boost,Light GBM)
步骤1:考虑所有(或样本)数据点以训练高度偏向的模型。
第2步:计算每个数据点的残差(误差)。
步骤3:在相同的数据点和相应的残差(错误)上训练另一个模型作为类标签。
步骤4:重复步骤2和步骤3(对于n次迭代)。 此过程容易过度拟合,因为我们正在计算模型已经在> 同一数据点上训练的数据点的残差。CatBoost程序
CatBoost以非常优雅的方式进行渐变增强。以下是使用玩具示例对CatBoost的说明。
假设我们的数据集中有10个数据点,并按时间排序,如下所示。 如果数据> 没有时间,CatBoost会随机为每个数据点创建一个人工时间。
如果数据> 没有时间,CatBoost会随机为每个数据点创建一个人工时间。 步骤1:使用当时在所有其他数据点上训练的模型计算每个数据点的残差(例如,为了计算x5数据点的残差,我们使用x1,x2,x3和x4训练一个模型)。因此,我们为不同的数据点训练不同的模型。最后,我们计算每个数据点的残差,它的对应模型以前从未见过该数据点。
- 步骤2:使用每个数据点的残差训练模型
- 第3步:重复步骤1和步骤2(进行n次迭代)
对于上述玩具数据集,我们应该训练9种不同的模型来获得9个数据点的残差。当我们有更多数据点时,这在计算上是昂贵的。
因此,默认情况下,它不是为每个数据点训练不同的模型,而是仅训练log ( num_of_datapoints )模型。现在,如果已经在n个数据点上训练了模型,那么该模型用于计算下n个数据点的残差。
- 已经在第一数据点上训练的模型用于计算第二数据点的残差。
- 已经在前两个数据点上训练的另一个模型用于计算第三和第四数据点的残差
- 等等…
在上面的玩具数据集中,现在我们使用已经在x1,x2,x3和x4上训练的模型计算x5,x6,x7和x8的残差。
我到目前为止所解释的所有这些程序都被称为有序增强。
随机排列
CatBoost实际上将给定数据集划分为随机排列,并对这些随机排列应用有序增强。默认情况下,CatBoost会创建四个随机排列。有了这种随机性,我们可以进一步停止过度拟合我们的模型。我们可以通过调整参数bagging_temperature来进一步控制这种随机性。这是您在其他增强算法中已经看到的内容。
处理分类功能。
- CatBoost具有非常好的分类数据矢量表示。它采用有序增强的概念并将其应用于响应编码。
- 在响应编码,我们表示使用平均到的目标值每个分类特征的所有的 与同一个分类特征的数据点。我们用它的类标签表示数据点的一个特征。这导致目标泄漏。
- CatBoost仅考虑该时间的先前数据点并计算具有相同分类特征的那些数据点的目标值的平均值。以下是带有示例的详细说明。
让我们拿一个玩具数据集。(所有数据点都按时/天排序) 如果数据> 没有时间,CatBoost会随机为每个数据点创建一个人工时间。
我们有功能1,一个具有3个不同类别的分类功能。
如果数据> 没有时间,CatBoost会随机为每个数据点创建一个人工时间。
我们有功能1,一个具有3个不同类别的分类功能。
对于响应编码,我们表示混浊=(15 + 14 + 20 + 25)/ 4 = 18.5
这实际上导致了目标泄漏。因为我们使用相同数据点的目标值来矢量化数据点。
CatBoost矢量化所有分类功能,没有任何目标泄漏。它不会考虑所有数据点,而只会考虑数据点过去的数据点。例如,
- 星期五,它代表阴天= (15 + 14)/ 2 = 15.5
- 星期六,它代表阴天= (15 + 14 + 20)/ 3 = 16.3
- 但在星期二,它代表阴天= 0/0?
为了克服这一点,我们都知道拉普拉斯平滑在朴素贝叶斯中的作用。CatBoost实现了同样的功能。
下面是另一个简洁的例子,
在此数据集中,有两个功能(国家和头发长度)。我们可以很容易地发现,只要一个人来自印度,他/她的头发颜色就是黑色。我们可以将这两个功能表示为一个功能。在现实世界中,有许多分类特征可以表示为单个特征。
CatBoost通过构建基本树来实现功能组合,其中根节点仅包含单个特征,对于子节点,它随机选择另一个最佳特征并沿着根节点中的特征表示它 。
下面是CatBoost的整洁图表,它将两个特征表示为树的第2级的单个特征。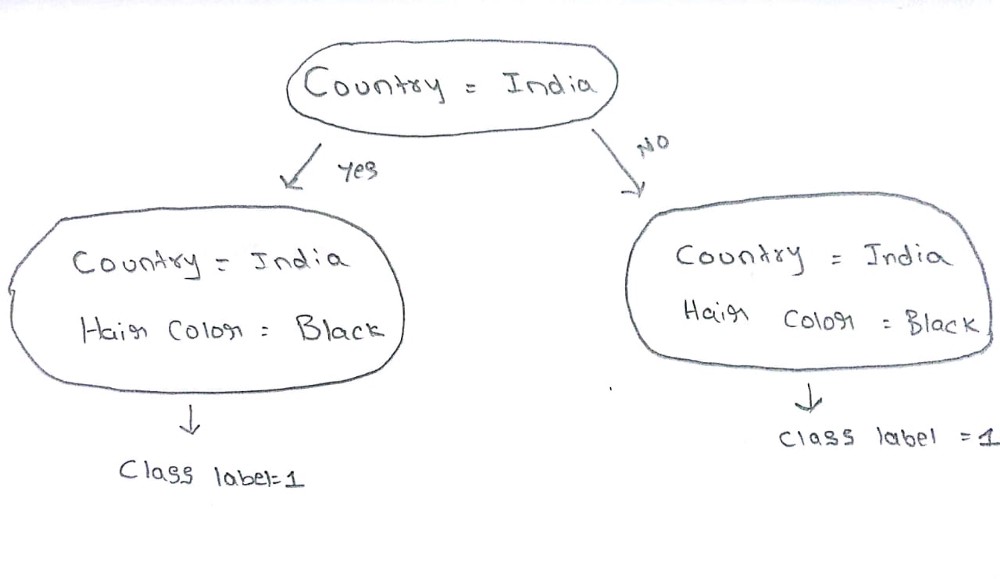
在树的第一层,我们有一个单一的特征。当树的级别增加时,分类特征组合的数量成比例地增加。
CatBoost中的单热编码
默认情况下,当且仅当分类功能具有两个不同的类别时,CatBoost在内部表示具有单热编码的所有分类功能。
- 如果你想实现一个分类的功能,有一个热码ñ不同的类别,那么你可以改变参数one_hot_max_size = ñ。
-
处理数字特征
CatBoost以与其他树算法相同的方式处理数字特征。我们根据信息增益选择最佳分割。
限制
此时,CatBoost 不支持稀疏矩阵。
当数据集具有许多数字特征时,CatBoost比Light GBM需要更多时间进行训练。
CatBoost在各种情况下:
虽然超参数调整并不是CatBoost的重要方面。最重要的是根据我们正在解决的问题设置正确的参数。以下是一些重要的情况。
1.数据随时间变化时
我们生活在21 日世纪,其中数据的分布硬拼随时间的变化。特别是在大多数互联网公司中,用户偏好随时间变化。现实世界中存在许多情况,其中数据随时间而变化。通过设置参数has_time = True,CatBoost在这些情况下可以很好地执行。
2.低延迟要求
客户满意度是每个企业最重要的方面。用户通常期望来自网站/模型的非常快速的服务。CatBoost是唯一具有非常少的预测时间的增强算法。由于其对称的树形结构。在预测时,它比XGBoost 快8倍。
3. 加权数据点
在某些情况下,我们需要更加重视某些数据点。特别是当您进行时间列车测试拆分时,您需要模型主要在较早的 数据点上进行训练。当您为数据点提供更多权重时,它在随机排列中被选中的可能性更高。
我们可以通过设置参数给予某些数据点更多的权重
例如,您可以为所有数据点提供线性权重
sample_weight = [x表示范围内的 x(train.shape [0])]4.使用小数据集
在某些情况下,如果数据点数较少,则需要的Log-loss最少。在这些情况下,您可以将参数fold_len_multiplier设置为接近 1 (必须> 1)和approx_on_full_history = True 。使用这些参数,CatBoost使用不同的模型计算每个数据点的残差。
5.使用大型数据集
对于大型数据集,您可以通过设置参数task_type = GPU在GPU上训练CatBoost 。它还支持多服务器分布式GPU。CatBoost还支持您可以在Google Colabs中训练的旧GPU。
6.监控错误/丢失功能
每次迭代都要监控模型,这是一种非常好的做法。您可以通过设置参数custom_metric = [‘AUC’,’Logloss’]来监控您选择的任何指标以及优化损失函数 。
您可以可视化您选择监控的所有指标。确保已使用pip 安装ipywidgets以在Jupyter Notebook中可视化绘图并设置参数plot = True。7.分阶段预测和缩小模型
这又是CatBoost库提供的一种强大方法。您已经训练过模型,并且想知道模型在特定迭代中如何预测。您可以调用staged_predict()方法来检查模型在该阶段的执行情况。如果您确实注意到在特定阶段模型的性能优于最终训练模型,则可以使用shrink()方法将模型缩小到该特定阶段。查看文档以获取更多信息。
8.处理不同的情况
无论是节日季节还是弱节日或正常日,模型都应该预测每种情况下的最佳结果。
对于这类问题,您可以在 不同的交叉验证数据集上训练不同的模型,并使用sum_models()方法将所有模型与一些权重分配给每个模型。稍后根据情况,您可以更改每个模型的权重。还有很多..
默认情况下,CatBoost有一个过度拟合检测器,当CV错误开始增加时,它会停止训练。您可以设置参数od_type = Iter,以便在几次迭代后停止训练模型。
- 与其他算法一样,我们也可以使用class_weight参数来 平衡 不平衡数据集。
- CatBoost不仅提供重要功能。但它也告诉我们,对于给定的数据点,重要的特征是什么。
- 培训代码CatBoost只是直接转发,它几乎与sklearn模块类似。我只解释了CatBoost的一些重要方面。您可以在此处进一步阅读CatBoost的完整文档,以便更好地理解。
再见超级参数调整?
CatBoost由强大的理论实现,如有序Boosting,Random permutations。它确保我们不会过度拟合我们的模型。它还实现了对称树,它消除了像(minchild_leafs)这样的参数。我们可以进一步调整参数,例如_learning_rate,random_strength,L2_regulariser,但结果变化不大。结束注意:
CatBoost速度极快,它的性能优于所有梯度增强算法。如果数据集中的大多数功能都是分类的,那么它是一个很好的选择。您可以在此处对CatBoost团队提供的作业进一步练习CatBoost 。一个强大的模型,过度拟合和非常强大的工具,还有你还在等什么?开始使用CatBoost !!!

若有收获,就点个赞吧
0 人点赞
